李智慧老师的架构师课程进行到了第8周,作业是一个算法相关的问题。本文主要是对该问题的解答与分析。
题目
有两个单向链表(链表长度分别为 m,n),这两个单向链表有可能在某个元素合并,也可能不合并,如下图所示的这样。现在给定两个链表的头指针,在不修改链表的情况下,如何快速地判断这两个链表是否合并?如果合并,找到合并的元素,也就是图中的 x 元素。
请用代码(或伪代码)描述算法,并给出时间复杂度。
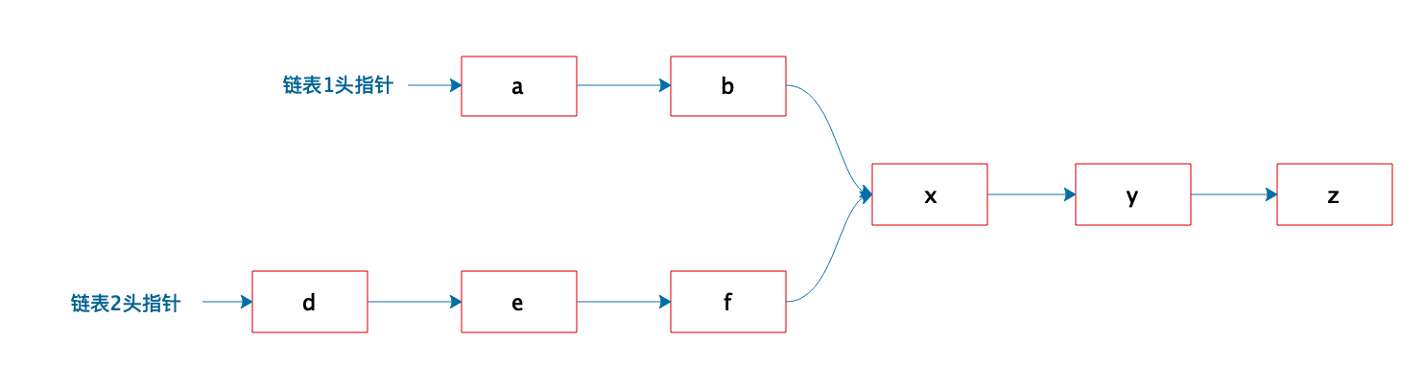
思路一,穷举法
问题是要寻找两个链表的合并节点,那么第一个直观的想法就是穷举法。顺序对第一个链表中的每一个节点,查看其在第二个链表中是否存在;若存在,则说明该节点就是两个链表的第一个合并点;若找不到,则说明两个链表没有合并。这个算法的时间复杂度为O(m*n)。伪代码如下。
1 static Node FindMergePoint(header1, header2) 2 { 3 var p1 = header1; 4 5 while (p1 != null) 6 { 7 // search for the p1 in the second list 8 var p2 = header2; 9 while (p2 != p1 && p2 != null) 10 { 11 p2 = p2->next; 12 } 13 14 // find p1 in the second list, then return this node 15 if (p2 == p1) 16 return p1; 17 18 // doesn't find it the second list. 19 // move to the next node in the first list. 20 p1 = p1->next; 21 } 22 23 // doesn't find any merge node 24 return null; 25 }
思路二,以空间换时间
在第一个思路中,我们很容易发现,第二个链表被检查过很多遍,最坏情况(找不到合并点)下对每个节点都查找了一遍。那能不能在查找一遍就把结果记在某个地方,以后直接查找而不用在遍历一遍呢?
在很多编程语言中都有Dictionary这种数据结构,它的一个特点就是查询的时间复杂度是O(1),即用key可以直接查得结果。Dictionary是用哈希算法实现这个O(1)复杂度的查询。假设哈希算法时间开销相比这个链表查询开销小很多的话,可以用Dictionary和下面的算法来解决问题,时间复杂度和空间复杂度都是O(m+n)。伪代码如下。
1 static Node FindMergePoint(header1, header2) 2 { 3 var nodeDict1 = new Dictionary<string, string>(); 4 5 // create a dictionary for the first linked list. 6 // both the key and the content of Dictionary are node address. 7 var p1 = header1; 8 while (p1 != null) 9 { 10 nodeDict1.Add(p1, p1); 11 p1 = p1->next; 12 } 13 14 // search the node p2 in the dictionary. 15 var p2 = header2; 16 while (!nodeDict1.ContainsKey(p2) && p2 != null) 17 p2 = p2->next; 18 19 // return the found one or null 20 return p2; 21 }
总结
穷举法简单直接,代码也容易理解,但是时间复杂度较高O(m*n)。哈希算法需要额外的时间计算哈希和额外的空间存储哈希结果,但是它可以把链表查合并点问题时间复杂度降低到O(m+n),在m、n较大时,还是优势较大。