scrapy框架的介绍
scrapy是一个开源和协作的框架。是一个快速、简单、并且可扩展的方法。Scrapy使用了异步网络框架来处理网络通讯,可以获得较快的下载速度,因此,我们不需要去自己实现异步框架。并且,Scrapy包含了各种中间件接口,可以灵活的完成各种需求。所以我们只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页上的各种内容。
scrapy爬虫的优点:
<1>内建的css选择器和xpath表达式;
<2>扩展性强,可使用signals和api(中间件,插件,管道)添加自定义功能;
<3>多用于session,cookies,http认证,user-agent,robots.txt,抓取深度限制的中间件和插件
<4>scrapy內建teinet console,可用于debug;
<5>健壮的编码支持。
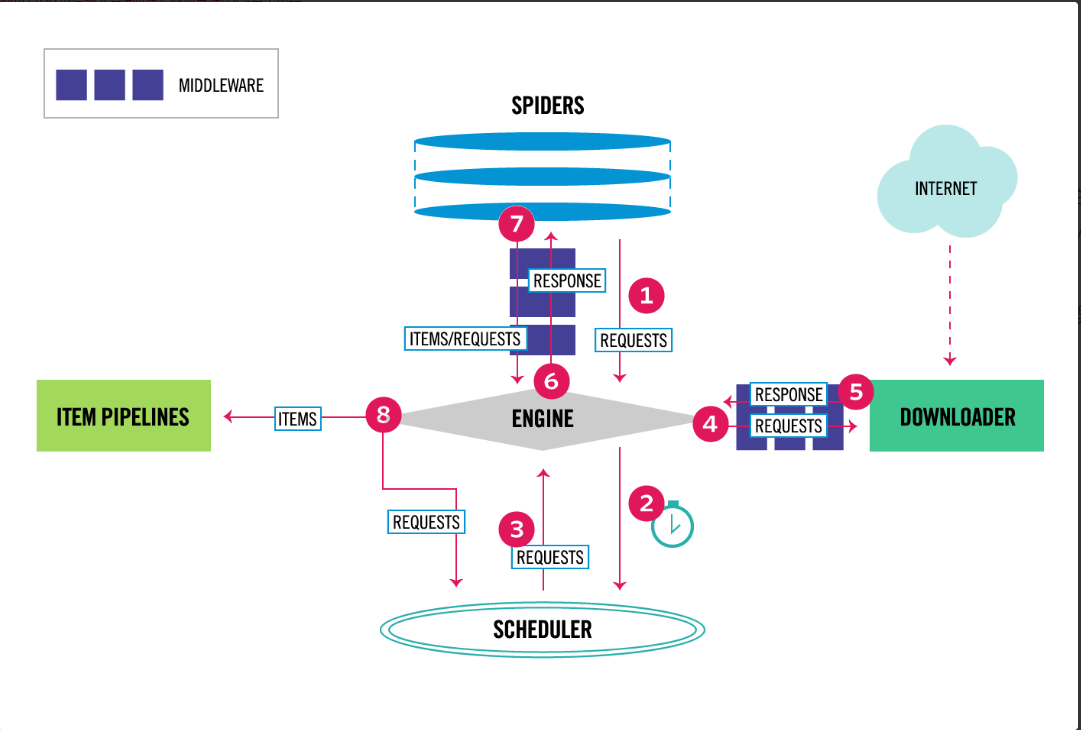
scrapy框架的组成
从上图中,可以看出scrapy框架由7个部分组成,分别是5个组件和2个中间件。
1.引擎(EGINE)
引擎(egine)是整个框架的核心部分,维系着整个框架的生命。通过它,可以处理整个系统的数据流,并在某些动作时触发事务。
2.调度器(SCHEDULER)
用来接受引擎发过来的请求, 传入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时比较强大的功能就是:可以对以前已经抓取过得链接进去重。
3.下载器(DOWNLOADER)
用于下载网页内容, 并将网页内容返回给Spider(Scrapy下载器是建立在twisted这个高效的异步模型上的),其实是将抓取的内容返回给引擎,引擎然后将网站的内容返回给spider。spider将内容进行解析。提取有用的数据或者进行下一步的抓取,或者将数据结构化给pipeline。
4.爬虫(SPIDERS)
SPIDERS是开发人员自己定义的类,用来解析responses,并且提取items, 获取重新发送新请求
5.项目管道(TIEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证,持久化(比如存到数据库中)等操作
6.下载中间件(DOWNLOADER MIDDLEWARES)
位于Scrapy引擎和下载器之间,主要是用来处理从EGINE传到DOWNLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response。
process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
change received response before passing it to a spider;
send a new Request instead of passing received response to a spider;
pass response to a spider without fetching a web page;
silently drop some requests.
7.爬虫中间件(Spider middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(responses)和输出(request)
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html
Srapy框架的安装
windows平台安装
step1 pip install wheel
step2 pip install lxml
step3 pip install pyopenssl
step4 pip install pywin32
step5 pip install Twisted-20.3.0-cp38-cp38-win_amd64.whl
step6 pip install scrapy
创建Scrapy项目
# scrapy可执行文件的路径
D:PythonPython38Scriptsscrapy.exe
# 创建scrapy项目
E:>scrapy startproject firstscrapy
# 创建爬虫
scrapy genspider 爬虫名 爬虫地址
E:firstscrapyfirstscrapyspiders>scrapy genspider chouti dig.chouti.com
# 运行爬虫
# 带运行日志
scrapy crawl chouti
# 不带运行日志
scrapy crawl chouti --nolog
# 支持右键执行爬虫
<1>创建可执行文件run.py
<2>在run.py中输入:
from scrapy.cmdline import execute
execute(['scrapy','crawl','chouti','--nolog']) # 这里的‘chouti’是类中定义的name
scrapy项目的目录结构
firstscrapy # 项目名称
firstscrapy # 包
spiders # 所有爬虫的包
__init__.py
chouti.py
__init__.py
items.py # 一个一个的类
middlewares.py # 中间件(爬虫,下载中间件都写在这)
pipelines.py # 持久化相关写在这(items.py中类的对象
run.py # 执行爬虫
settings.py # 配置文件
scrapy.cfg # 上线相关
settings配置文件
1 默认情况,scrapy会去遵循爬虫协议
2 修改配置文件参数,强行爬取,不遵循协议
-ROBOTSTXT_OBEY = False
3 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
4 LOG_LEVEL='ERROR'
使用scrapy框架爬取抽屉新闻
使用解析的三种方式
使用第三方解析:
from bs4 import BeautifulSoup
def parse(self, response):
print(response.text)
# 解析数据(第一种方案,自己解析,bs4,lxml)
soup=BeautifulSoup(response.text,'lxml')
divs=soup.find_all(class_='link-title')
for div in divs:
print(div.text)
继续爬取其他网址:
def parse(self, response):
# 以后解析都在这
print(response.status)
# 假设解析出一个网址(继续爬取)
# don_filter=True 不过滤除了allowed_domains之外的URL
return Request('https://www.baidu.com/',dont_filter=True)
使用自带的解析方式:
# 取文本
-css选择器
response.css('.link-title::text').extract() #取多个,列表
-xpath选择器
response.xpath('//a[contains(@class,"link-title")]/text()').extract()
# 取属性
response.css('.link-title::attr(href)').extract_first() # 取第一个
response.xpath('//a[contains(@class,"link-title")]'/@href).extra_first()
解析出所有的标题和图片地址
使用
xpath选择器
def parse(self, response, **kwargs):
news_list = [
{
'title':div.xpath('.//a[contains(@class,"link-title")]/text()').extract_first(),
'img_url':div.xpath('.//img[contains(@class,"image-scale")]/@src').extract_first(),
# 'title':div.css('.link-title::text').extract_first(),
# 'img_url':div.css('.image-scale::attr(src)').extract_first(),
}
for div in response.xpath('//div[contains(@class,"link-item")]')
]
print(len(news_list))
for news in news_list:
print(news)
使用
css选择器
news_list = [
{
# 'title':div.xpath('.//a[contains(@class,"link-title")]/text()').extract_first(),
# 'img_url':div.xpath('.//img[contains(@class,"image-scale")]/@src').extract_first(),
'title':div.css('.link-title::text').extract_first(),
'img_url':div.css('.image-scale::attr(src)').extract_first(),
}
for div in response.xpath('//div[contains(@class,"link-item")]')
]
print(len(news_list))
for news in news_list:
print(news)
scrapy持久化
方案一:parser函数必须返回列表套字典的形式(了解)
存储为
csv文件
def parse(self, response, **kwargs):
news_list = []
for div in response.xpath('//div[contains(@class,"link-item")]'):
news_list.append(
{
'title':div.xpath('.//a[contains(@class,"link-title")]/text()').extract_first(),
'img_url':div.xpath('.//img[contains(@class,"image-scale")]/@src').extract_first()
}
)
return news_list
在终端中执行以下命令:
scrapy crawl drawer -o drawer.csv -s FEED_EXPORT_ENCODING=GBK
# 也可以在settings.py中指定编码
FEED_EXPORT_ENCODING='GBK'
存储为
json格式文件
scrapy crawl drawer -o drawer.json
# 打开文件显示的是Unicode编码,如果想显示为中文,需要设置下:-s FEED_EXPORT_ENCODING=UTF-8
方案二:高级,pipline item存储(mysql,redis,file)
在Items.py中写一个类
import scrapy
class DrawerItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
url = scrapy.Field()
img_url = scrapy.Field()
在spinder中导入,实例化,把数据放进去
import scrapy
from firstscrapy.items import DrawerItem
class DrawerSpider(scrapy.Spider):
name = 'drawer'
allowed_domains = ['dig.chouti.com']
start_urls = ['http://dig.chouti.com/']
def parse(self, response, **kwargs):
for div in response.xpath('//div[contains(@class,"link-item")]'):
item = DrawerItem()
title = div.xpath('.//a[contains(@class,"link-title")]/text()').extract_first()
url = div.xpath('.//a[contains(@class,"link-title")]/@href').extract_first()
img_url = div.xpath('.//img[contains(@class,"image-scale")]/@src').extract_first()
item['title'] = title
item['url'] = url
item['img_url'] = img_url
yield item
在settings中配置(数字越小,级别越高)
ITEM_PIPELINES = {
'firstscrapy.pipelines.DrawerFilePipeline': 300,
'firstscrapy.pipelines.DrawerMysqlPipeline': 305,
'firstscrapy.pipelines.DrawerRedisPipeline': 310,
}
在pipelines.py中写DrawerFilePipeline
class DrawerFilePipeline:
def open_spider(self,spider):
self.file = open('drawer.txt',mode='w',encoding='utf-8')
def process_item(self, item, spider):
title = item['title']
url = item['url']
img_url = item['img_url'] or 'None'
self.file.write(title+'
'+url+'
'+img_url+'
')
return item
def close_spider(self,spider):
self.file.close()
"""
-open_spider(开始的时候)
-close_spider(结束的时候)
-process_item(在这持久化)
"""