一、什么是继承
# 继承是一种创建新类的方式。 新建的类可称为子类或派生类,父类又可称为基类或超类,子类会遗传父类的属性
注意:python支持多继承,新建的类可以继承一个或多个父类
class ParentClass1: #定义父类 pass class ParentClass2: #定义父类 pass class SubClass1(ParentClass1): #单继承 pass class SubClass2(ParentClass1,ParentClass2): #多继承 pass
通过类的内置属性__bases__可以查看类继承的所有父类
print(SubClass2.__bases__) >> (<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
二、经典类与新式类
在python2中有新式类和经典类之分
#新式类:继承了object类的子类,以及该子类的子类子子类 #经典:没有继承object类的子类,以及该子类的子类子子类
在python3中没有继承任何类,那么会默认继承object类,所以python3中所有的类都是新式类
三、多继承
python多继承的优缺点
I 优点:子类可以同时遗传多个父类的属性,最大限度地重用代码 II缺点:1、违背人的思维习惯:继承表达的是一种什么"是"什么的关系 2、代码可读性会变差 3、不建议使用多继承,有可能会引发可恶的菱形问题,扩展性变差, 如果真的涉及到一个子类不可避免地要重用多个父类的属性,应该使用Mixins
继承主要是用来解决类与类之间的代码冗余问题
# 3、如何实现继承 # # 示范1:类与类之间存在冗余问题 # class Student: # school='OLDBOY' # # def __init__(self,name,age,sex): # self.name=name # self.age=age # self.sex=sex # # def choose_course(self): # print('学生%s 正在选课' %self.name) # # # class Teacher: # school='OLDBOY' # # def __init__(self,name,age,sex,salary,level): # self.name=name # self.age=age # self.sex=sex # self.salary=salary # self.level=level # # def score(self): # print('老师 %s 正在给学生打分' %self.name) # # 示范2:基于继承解决类与类之间的冗余问题 class OldboyPeople: school = 'OLDBOY' def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex class Student(OldboyPeople): def choose_course(self): print('学生%s 正在选课' % self.name) # stu_obj = Student('lili', 18, 'female') # print(stu_obj.__dict__) # print(stu_obj.school) # stu_obj.choose_course() class Teacher(OldboyPeople): # 老师的空对象,'egon',18,'male',3000,10 def __init__(self, name, age, sex, salary, level): # 指名道姓地跟父类OldboyPeople去要__init__ OldboyPeople.__init__(self,name,age, sex) self.salary = salary self.level = level def score(self): print('老师 %s 正在给学生打分' % self.name) tea_obj=Teacher('egon',18,'male',3000,10) # print(tea_obj.__dict__) # print(tea_obj.school) tea_obj.score()
四、属性查找
有了继承关系,对象在查找属性时,先从对象自己的__dict__中找,如果没有则去子类中找,然后再去父类中找
>>> class Foo: ... def f1(self): ... print('Foo.f1') ... def f2(self): ... print('Foo.f2') ... self.f1() ... >>> class Bar(Foo): ... def f1(self): ... print('Bar.f1') ... >>> b=Bar() >>> b.f2() Foo.f2 Bar.f1
父类如果不想让子类覆盖自己的方法,可以采用双下划线开头的方式将方法设置为私有的
>>> class Foo: ... def __f1(self): # 变形为_Foo__fa ... print('Foo.f1') ... def f2(self): ... print('Foo.f2') ... self.__f1() # 变形为self._Foo__fa,因而只会调用自己所在的类中的方法 ... >>> class Bar(Foo): ... def __f1(self): # 变形为_Bar__f1 ... print('Bar.f1') ... >>> >>> b=Bar() >>> b.f2() #在父类中找到f2方法,进而调用b._Foo__f1()方法,同样是在父类中找到该方法 Foo.f2 Foo.f1
五、菱形问题
大多数面向对象语言都不支持多继承,而在Python中,一个子类是可以同时继承多个父类的,这固然可以带来一个子类可以对多个不同父类加以重用的好处,但也有可能引发著名的
Diamond problem菱形问题
如下图:

A类在顶部,B类和C类分别位于其下方,D类在底部将两者连接在一起形成菱形。
继承原理:
python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表
python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查 2.多个父类会根据它们在列表中的顺序被检查 3.如果对下一个类存在两个合法的选择,选择第一个父类
对于对象
1.由对象发起的属性查找,会从对象自身的属性里检索,没有则会按照对象的类.mro()规定的顺序依次找下去,
2.由类发起的属性查找,会按照当前类.mro()规定的顺序依次找下去,
深度优先和广度优先
如果继承关系为菱形结构,那么经典类与新式类会有不同MRO,分别对应属性的两种查找方式:深度优先和广度优先
1、经典类
#当类是经典类时,多继承的情况下,要查找的属性不存在时,会按照深度优先的方式查找下去
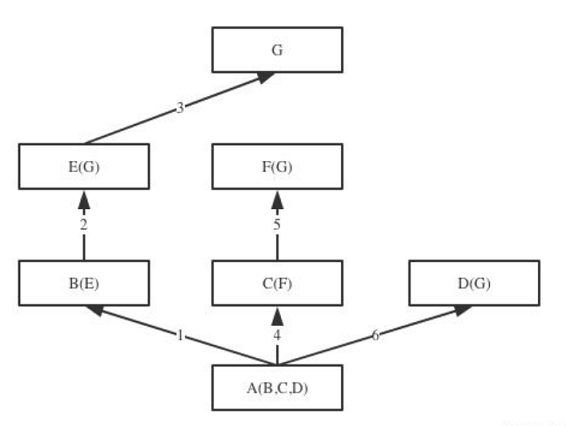
查找顺序:A->B->E->G->C-F-D
2、新式类
#当类是新式类时,多继承的情况下,要查找的属性不存在时,会按照广度优先的方式查找下去
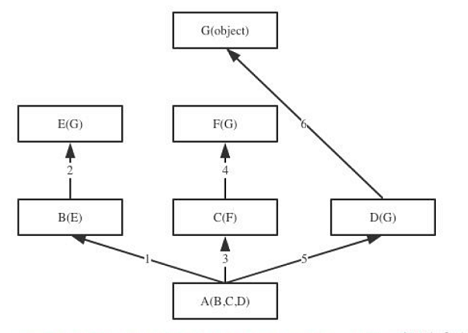
查找顺序:A->B->E->C->F-D->object
总结:
# 多继承到底要不用??? # 要用,但是规避几点问题 # 1、继承结构尽量不要过于复杂 # 2、推荐使用mixins机制:在多继承的背景下满足继承的什么"是"什么的关系