已知两张数据表,其中表一存储的是学生编号、学生姓名;表二存储的是学生编号、考试科目、考试成绩;编写mapreduce程序,汇总两张表数据为一张统一表格。
表一:
A001 zhangsan
A002 lisi
A003 wangwu
A004 zhaoliu
A005 tianqi
表二:
A001 math 80 A002 math 76 A003 math 90 A004 math 67 A005 math 78 A001 english 78 A002 english 69 A003 english 88 A004 english 98 A005 english 56 A001 computer 56 A002 computer 77 A003 computer 84 A004 computer 92 A005 computer 55
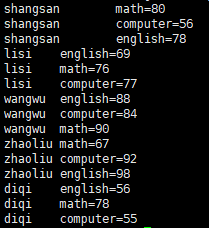
正确结果:
执行java程序,打印出part-r-00000中数据:
代码如下(由于水平有限,不保证完全正确,如果发现错误欢迎指正):
package com; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Test { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration config = new Configuration(); config.set("fs.defaultFS", "hdfs://192.168.0.100:9000"); config.set("yarn.resourcemanager.hostname", "192.168.0.100"); FileSystem fs = FileSystem.get(config); Job job = Job.getInstance(config); job.setJarByClass(Test.class); //设置所用到的map类 job.setMapperClass(myMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //设置用到的reduce类 job.setReducerClass(myReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //设置输入输出地址 FileInputFormat.addInputPath(job, new Path("/day19/")); Path path = new Path("/output5/"); if(fs.exists(path)){ fs.delete(path, true); } //指定文件的输出地址 FileOutputFormat.setOutputPath(job, path); //启动处理任务job boolean completion = job.waitForCompletion(true); if(completion){ System.out.println("Job Success!"); } } public static class myMapper extends Mapper<Object, Text, Text, Text> { // 实现map函数 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String temp=new String();// 左右表标识 String values=value.toString(); String words[]=values.split(" "); String mapkey = new String(); String mapvalue = new String(); //左表:A001,zhangsan if (words.length==2) { mapkey = words[0]; mapvalue =words[1]; temp = "1"; }else{ //右表:A001,math,80 mapkey = words[0]; mapvalue =words[1]+"="+words[2]; temp = "2"; } // 输出左右表 //左表:(A001,1+zhangsan) //右表:(A001,2+math=80) context.write(new Text(mapkey), new Text(temp + "+"+ mapvalue)); System.out.println("key:"+mapkey+"---value:"+mapvalue); } } //reduce解析map输出,将value中数据按照左右表分别保存 public static class myReducer extends Reducer<Text, Text, Text, Text> { // 实现reduce函数 public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //学生的数组 List<String> people =new ArrayList<String>(); //成绩的数组 List<String> score =new ArrayList<String>(); //(A001,{1+zhangsan,2+math=80}) for(Text value:values){ // 取得左右表标识 char temp = (char) value.charAt(0); //1 String words[] = value.toString().split("[+]"); //1,zhangsan if(temp == '1'){ people.add(words[1]); } if(temp == '2'){ score.add(words[1]); } } //遍历两次,求出笛卡尔积 for (String p : people) { for (String s : score) { context.write(new Text(p), new Text(s)); } } } } }
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击下方的【好文要顶】按钮【精神支持】,因为这两种支持都是使我继续写作、分享的最大动力!