源代码查看,有三个常量,
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
三个常量中可以看出,默认的容器大小是16,最大长度是2的30次方,load factor默认是0.75,扩充的临界值是16*0.75=12
当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁。如图
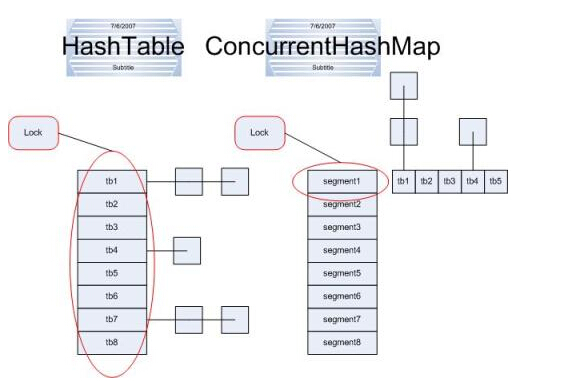
左边便是Hashtable的实现方式---锁整个hash表;而右边则是ConcurrentHashMap的实现方式---锁桶(或段)。ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。试想,原来只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见.
想要对ConcurrentHashMap如何实现锁粒度控制和如何锁,还需研读ConcurrentHashMap源码。