source:https://www.elastic.co/guide/en/elasticsearch/reference/6.4/api-conventions.html
es的API使用http的json格式进行请求(https://www.elastic.co/guide/en/elasticsearch/reference/6.4/modules-http.html)
这一张列出来的协议可以适用于所有的API,除非有其他另外的说明。
多重索引:
大多数的AP都支持跨多个索引执行一个索引参数操作
用简单的test1,test2,test3表示(或者_all来表示所有的索引)
这同样支持wildcards,比如:test* / *test / te*t / *test*
所有的索引API支持下面的url字符串变量查询
ignore_unavailable
控制如果特定的索引不可用是否可以忽略,包括不存在的或者关闭的索引,可以指定true或者false
allow_no_indices:
控制通过通配符索引表达式查询的当前索引是否失败。可以指定true/false。
举个栗子:
如果指定通配符表达式foo*,但是没有对应的索引匹配,按照这个设定这个请求将会失败,这个设置同时适用于别名,一个别名指向一个关闭的索引
expand_wildcards
控制扩展到哪种索引通配符表达式,指定open的话通配符表达式就只扩展到open的索引;指定closed通配符表达式就只扩展到关闭的索引,同时指定两个值(open,closed)就可以扩展到所有索引
如果什么也不指定(指定none) 通配符表达式就会不可用,如果指定了all就会扩展到所有索引。
默认参数取决于正在使用的api
一个索引API比如说 documentAPI single-index 别名api不支持多重索引
索引名中支持的日期数学
日期数学索引名解决方法使你能对一个区间的时间系列索引进行搜索,而不是搜索所有的时间系列索引再过滤结果或者是维护一些别名。限制索引的数量可以降低搜索对集群的负载提高查询性能。举个栗子,如果在你的日志中发现了搜索错误,你可以使用日期数学名字模板去限制搜索过去两天的数据。
几乎所有的API有索引变量索引变量值中支持日期数学
一个日期数学索引名称是以下的格式:
<static_name{date_math_expr{date_format|time_zone}}>
static_name:名称的静态文本部分
date_math_expr:动态日期数学表达式用来动态计算日期
date_format:日期可选格式,默认 YYYY.MM.dd
time_zone:可选的zone,默认utc
你必须将日期数学索引名称表达式放入到尖括号内,所有特殊的字符都应该用URI编码,比如:
# GET /<logstash-{now/d}>/_search
curl -X GET "localhost:9200/%3Clogstash-%7Bnow%2Fd%7D%3E/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query" : {
"match": {
"test": "data"
}
}
}
'
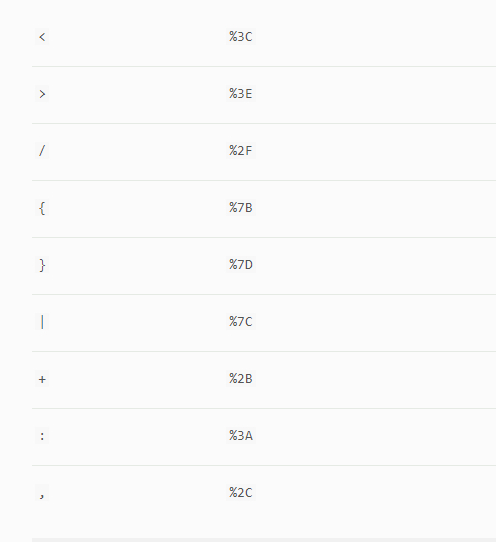
日期数学字符的百分比编码:
下面的例子展示了日期数学索引名称的不同格式,在给定当前时间的情况下给定的最终索引名称是
22nd March 2024 noon utc
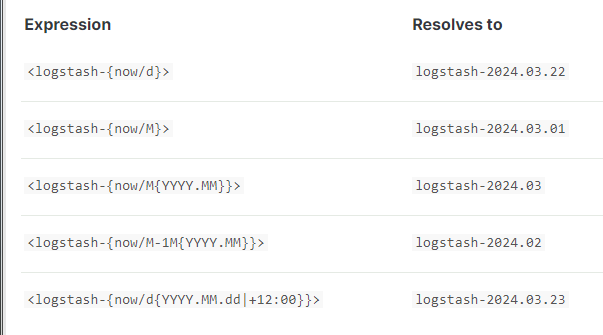
在索引名模板中用字符 { 和 } 在静态部分中,用 反斜杠来进行转义
<elastic\{ON\}-{now/M}>resolves toelastic{ON}-2024.03.01
下面的例子展示了一个搜索过去三天日志索引的搜索请求,假设索引用默认的日志索引名称格式,logstash-YYYY.MM.dd
# GET /<logstash-{now/d-2d}>,<logstash-{now/d-1d}>,<logstash-{now/d}>/_search
curl -X GET "localhost:9200/%3Clogstash-%7Bnow%2Fd-2d%7D%3E%2C%3Clogstash-%7Bnow%2Fd-1d%7D%3E%2C%3Clogstash-%7Bnow%2Fd%7D%3E/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query" : {
"match": {
"test": "data"
}
}
}
'
公用操作
下面的操作可以适用于所有的REST APIS
好看的结果
在请求后面加上?pretty=true, JSON返回一个好看一点的结果,另一个操作就是设置?format=yaml
这将会返回一个易读的yaml格式
人类可读输出
统计数据返回一个人类易阅读的格式("exists_time":"1h" or "size":"1kb") 和对电脑友好格式("exists_time_in_millis":3600000 or "size_in_bytes":1024) 人类友好阅读方式可以通过在查询语句后增加?human=false关掉,方便监控工具进行结果获取,默认的human标志是未开启false
返回过滤:
请求:
curl -X GET "localhost:9200/_search?q=elasticsearch&filter_path=took,hits.hits._id,hits.hits._score&pretty"
返回:
{
"took" : 3,
"hits" : {
"hits" : [
{
"_id" : "0",
"_score" : 1.6375021
}
]
}
}
请求:
curl -X GET "localhost:9200/_cluster/state?filter_path=metadata.indices.*.stat*&pretty"
返回:
{
"metadata" : {
"indices" : {
"twitter": {"state": "open"}
}
}
}
请求:
curl -X GET "localhost:9200/_cluster/state?filter_path=routing_table.indices.**.state&pretty"
返回:
{
"routing_table": {
"indices": {
"twitter": {
"shards": {
"0": [{"state": "STARTED"}, {"state": "UNASSIGNED"}],
"1": [{"state": "STARTED"}, {"state": "UNASSIGNED"}],
"2": [{"state": "STARTED"}, {"state": "UNASSIGNED"}],
"3": [{"state": "STARTED"}, {"state": "UNASSIGNED"}],
"4": [{"state": "STARTED"}, {"state": "UNASSIGNED"}]
}
}
}
}
}
可以用字符 - 来对结果进行过滤
curl -X GET "localhost:9200/_count?filter_path=-_shards&pretty"
返回:
{
"count" : 5
}
包括语句和排除语句都能在同样的表达式中组合,下面的例子中,先排除后包括过滤
curl -X GET "localhost:9200/_cluster/state?filter_path=metadata.indices.*.state,-metadata.indices.logstash-*&pretty"
返回:
{
"metadata" : {
"indices" : {
"index-1" : {"state" : "open"},
"index-2" : {"state" : "open"},
"index-3" : {"state" : "open"}
}
}
}
注意es有时候直接返回字段的原始值,比如"_source",如果你想过滤_source,你可以考虑组合已存在的_source 元素,(https://www.elastic.co/guide/en/elasticsearch/reference/6.4/docs-get.html#get-source-filtering)
通过filter_path
curl -X POST "localhost:9200/library/book?refresh&pretty" -H 'Content-Type: application/json' -d'
{"title": "Book #1", "rating": 200.1}
'
curl -X POST "localhost:9200/library/book?refresh&pretty" -H 'Content-Type: application/json' -d'
{"title": "Book #2", "rating": 1.7}
'
curl -X POST "localhost:9200/library/book?refresh&pretty" -H 'Content-Type: application/json' -d'
{"title": "Book #3", "rating": 0.1}
'
curl -X GET "localhost:9200/_search?filter_path=hits.hits._source&_source=title&sort=rating:desc&pretty"
返回:
{
"hits" : {
"hits" : [ {
"_source":{"title":"Book #1"}
}, {
"_source":{"title":"Book #2"}
}, {
"_source":{"title":"Book #3"}
} ]
}
}
平面设置
flat_settings 标志影响设置列表的呈现,当flag_settings标志是true的时候以平面模式返回数据
curl -X GET "localhost:9200/twitter/_settings?flat_settings=true&pretty"
返回:
{
"twitter" : {
"settings": {
"index.number_of_replicas": "1",
"index.number_of_shards": "1",
"index.creation_date": "1474389951325",
"index.uuid": "n6gzFZTgS664GUfx0Xrpjw",
"index.version.created": ...,
"index.provided_name" : "twitter"
}
}
}
当flag_settings 标志是false的时候以人类可阅读的方式返回
curl -X GET "localhost:9200/twitter/_settings?flat_settings=false&pretty"
返回:
"twitter" : {
"settings" : {
"index" : {
"number_of_replicas": "1",
"number_of_shards": "1",
"creation_date": "1474389951325",
"uuid": "n6gzFZTgS664GUfx0Xrpjw",
"version": {
"created": ...
},
"provided_name" : "twitter"
}
}
}
}
默认情况下flag_settings设置为false
参数:
rest参数遵循大小写试用下划线的约定
布尔值:
所有的restAPI参数(请求参数和json体)都支持提供布尔值'false'当做false和“true”当做true,其他的值会报错。
数值:
所有的rest api都支持以字符串形式提供数值在支持json数字类型的时候
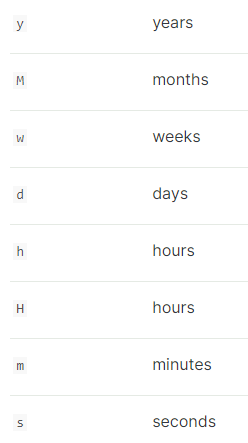
时间单元:
当需要指定持续时间时,比如timeout元素,间隔必须指定单位,比如2d代表2天,支持单元如下:
假设当前时间now是 2001-01-01 12:00:00,有以下使用方式:
now+1h :2001-01-01 13:00:00
now-1h:2001-01-01 11:00:00
now-1h/d: 2001-01-01 00:00:00
2001.02.01||+1M/d :2001-03-01 00:00:00
结果过滤:
所有的rest API都接收filter_path参数 这个可以用来减少es返回的结果,这个参数接收一些用逗号分割的过滤条件列表
curl -X GET "localhost:9200/_search?q=elasticsearch&filter_path=took,hits.hits._id,hits.hits._score&pretty"
{
"took" : 3,
"hits" : {
"hits" : [
{
"_id" : "0",
"_score" : 1.6375021
}
]
}
}
这同样支持 * 匹配查询参数,用来匹配field需要过滤的名称。
curl -X GET "localhost:9200/_cluster/state?filter_path=metadata.indices.*.stat*&pretty"
{
"metadata" : {
"indices" : {
"twitter": {"state": "open"}
}
}
}
**匹配可以用来匹配一些不知道绝对路径的field,我们可以用下面的请求获取每个segment的lucene版本:
curl -X GET "localhost:9200/_cluster/state?filter_path=routing_table.indices.**.state&pretty"
返回{
"routing_table": { "indices": { "twitter": { "shards": { "0": [{"state": "STARTED"}, {"state": "UNASSIGNED"}], "1": [{"state": "STARTED"}, {"state": "UNASSIGNED"}], "2": [{"state": "STARTED"}, {"state": "UNASSIGNED"}], "3": [{"state": "STARTED"}, {"state": "UNASSIGNED"}],
"4": [{"state": "STARTED"}, {"state": "UNASSIGNED"}] } } } } }
这同样可以用字符'-'来对结果进行过滤