问题:
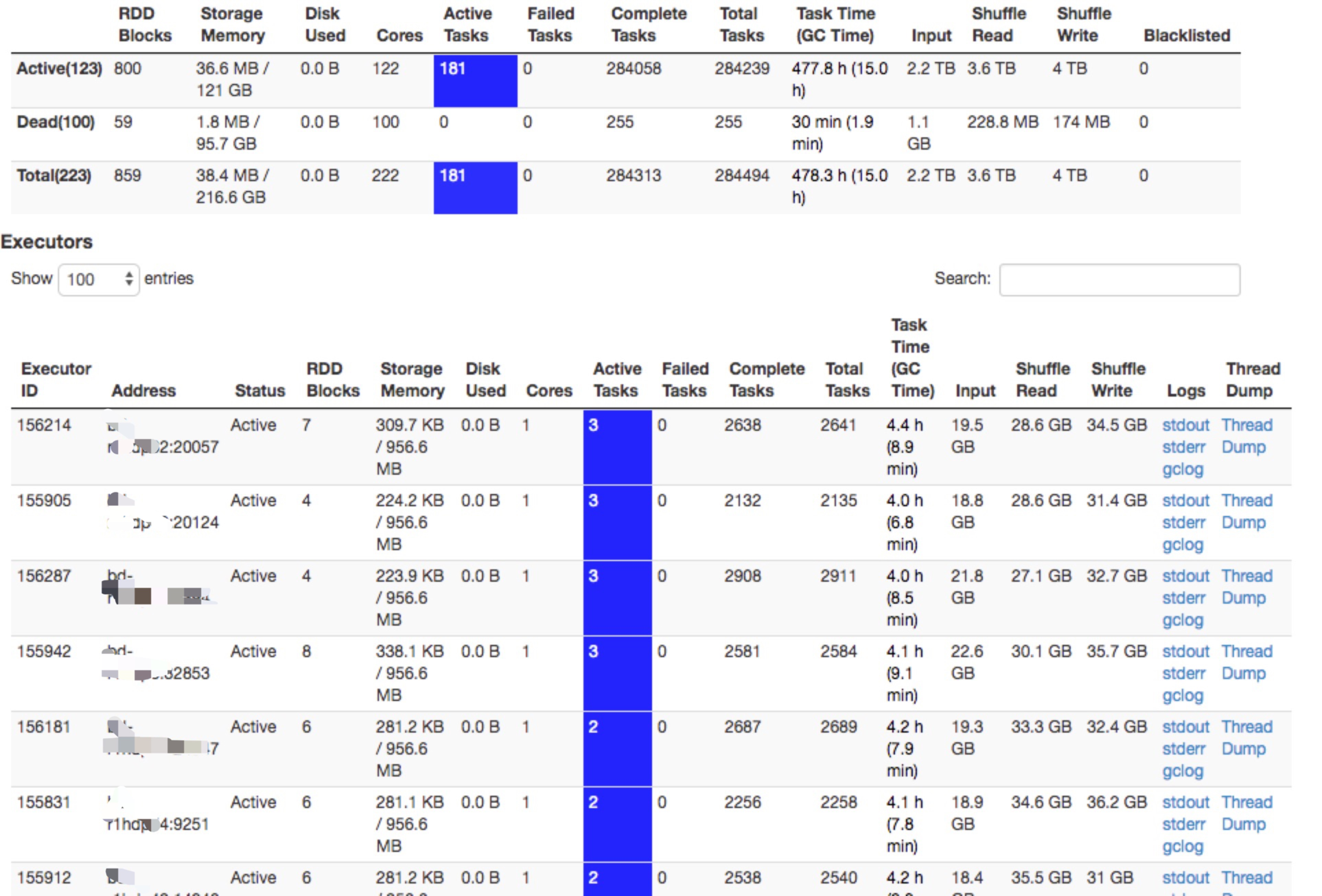
线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑。此外,由于在yarn mode下,默认情况是一个executor只能有一个active task,但是executor页面的active task却可以有多个。而且在没有任务在跑的情况下,动态资源你分配不能生效,spark thriftserver在空闲的情况下资源得不到释放。
问题排查:
1,看到某个executor有大量的active task,首先想到是不是真的是task没有结束。所以首先去对应的executor机器上,查看对应进程的cpu,发现利用率很低。与此同时,打印进程线程栈和正常的executor的线程栈进行对比,发现连行数都是一样的。初步排除了是由于task没有结束,导致task一直在忙的情况。
2,虽然是偶现,但是发现即使某个executor的active task已经很高了(比方说10,大于1),当有新的任务过来时,这个executor仍然可以调度在这个executor上。由此可以确定,在driver内部的dagscheuler和task scheduler中对资源使用情况的相关统计数据是对的。
3,通过1,2的分析,接下来的猜测就是UI显示的数据不对了。2.3以后对ui的模块进行了重新改造,难道是新引入的bug?从官方的jira上搜了一圈,没有发现类似的问题。
4,除了UI上显示的active task不对,spark的动态资源分配也确实没有生效(在没有任务时,executor资源没有释放),说明动态资源分配时获取的系统资源统计也是有误的。于是找了一圈有关动态资源分配的一些jira,还真发现了一些jira(https://issues.apache.org/jira/browse/SPARK-11334)打上补丁,但是UI页面显示的active task肯定和这个issue是没有关系的。
5,到此时,陷入了无解。后来突然想到,无论是UI页面的统计还是动态资源分配,都走的是消息总线机制,之前看源码的时候印象中,消息总线中的消息不是100%不丢的(spark Listener和Metrics机制),所以去日志中搜了一下相关消息,果然发现有消息丢失。

然后翻了一下源码,spark消息这个队列的大小是10000,超过这个值的时候,如果还没有消费掉,就会丢弃消息,然后果断调大到10w,目前已过去三四天了,线上还没有出现这个问题,应该就是这个原因了。
6,进一步思考,为啥会有这个的消息事件呢?spark官方并没有类似的jira,然后想到我们自己跑的spark自行添加了一些event到消息总线,可能是自行添加的event导致的,所以以后自行添加event事件的时候要注意一下这个队列大小的限制。另外,在100%需要对数据进行统计的准备的情况下,使用spark内部的消息总线机制来做异步处理并不是非常的恰当。