题目要求
- 利用除留余数法为下列关键字集合的存储设计hash函数,并画出分别用开放寻址法和拉链法解决冲突得到的空间存储状态(散列因子取0.75)
关键字集合:85,75,57,60,65,(你的8位学号相加值),98,74,89,12,5,46,97,13,69,52,92
实现思路
-
线性探测开放寻址法:
1.调用哈希函数处理键得到哈希值,用值除以表的长度后取余数,从而确定表中的一个位置。
2.如果该位置非空,则探测下一个位置,到达表最后一项时,折回表头。
3.如果回到原来哈希位置上时还未找到空闲位置,说明表已经填满了。
【附】注意发生冲突后的填入顺序。 -
线性探测(形象表达法):
简单地讲,也就是说,一间厕所,来了一个顾客就蹲其对应的位置,如果又来一个顾客,把厕所单间门拉开,一看里面有位童鞋正在用劲,那么怎么办?很自然的,拉另一个单间的门,看看有人不,有的话就继续找坑。当然了,一般来说,这个顾客不会按顺序一个一个地拉厕所门,而是会去拉他认为有可能没有被占用的单间的门,这可以通过闻味道,听声音来辨别,这就是寻址查找算法。如果找遍了所有厕所单间,看尽了所有人的光屁股,还是找不到坑,那么这座厕所就该扩容了。当然了,厕所扩容不会就只单单增加一个坑位,而是综合考虑成本和保证不让太多顾客拉到裤子里,会多增加几个坑位,比如增加现有坑位的0.72倍。为什么是0.72呢,这是所长多年经营所得到的经验值,为了让自己的经验发扬光大,需要出去演讲,又不能太俗,总不能说“厕所坑位因子”吧,那就把把0.72叫做“装填因子”或者“扩容因子”吧。目前很多产品使用0.72这个常数。
- 链式探查法(拉链法):
将哈希表看成是集合的表而不是各独立单元的表。
每个单元中保存一个指针,指向与表中该位置相关的元素集合。
实现结果
-
线性探测法:(注意发生冲突后的填入顺序,关键区域的填入顺序已标出)

-
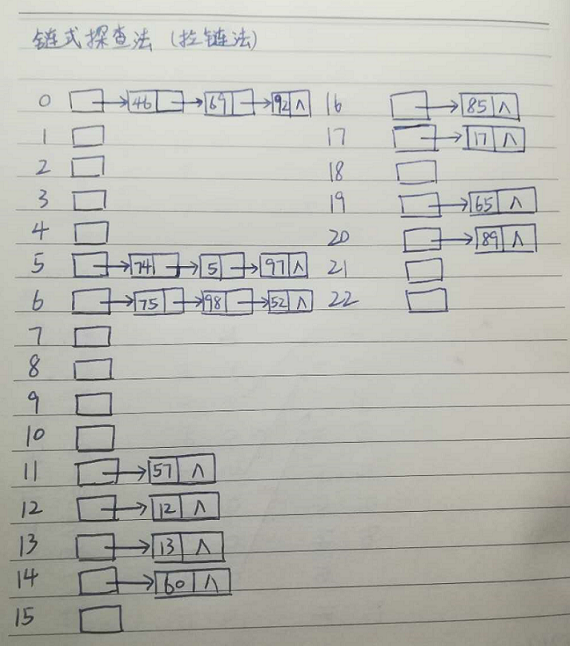
链式探查法:
关键问题
-
陈留余数法中如何确定H(key)中的key与哪个数取余?为什么?
-
解决方案 :(查找资料)
对于散列表长为 m 的散列函数公式为:f( key ) = key mod p ( p ≤ m ),若散列表表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。这么做是因为如果 p 的约数越多,那么冲突的几率就越大,这样余数相同的数就会增加,从而使得散列表第一次处理数据时的利用率降低,从而增加了算法复杂度,以上是个人理解。下面举一个查到的例子说明一下:
某散列表的长度为100,散列函数 H(k) = k%P ,则P通常情况下最好选择哪个呢?
A、91 B、93 C、97 D、99
【解析】实践证明,当P取小于哈希表长的最大质数时,产生的哈希函数较好。我选97,因为它是离长度值最近的最大质数。
- 至于为什么P应该这么选取,以下简单的证明过程:(gcd表示最大公约数)
假设 p 是一个有较多约数的数,同时在数据中存在 key 满足最大公约数 gcd(p,key) = d > 1 ,即有 p = a·d , key = b·d ,则有以下等式:key % p = key – p·[key/p] = key – p·[b/a] 。其中,[b / a]的取值范围是不会超过[0,a-1]的正整数。也就是说,[b / a]的值只有a 种可能,而p 是一个预先确定的数。因此上式的值就只有a 种可能了(这显然缩小了余数分布的范围)。这样,取 mod 运算之后的余数仍然在[0,p-1]内,但是它的取值仅限于等式可能取到的那些值,也就是说余数的分布变得不均匀了。容易看出,p 的约数越多,发生这种余数分布不均匀的情况就越频繁,冲突的几率越高。而素数的约数是最少的,因此我们选用大素数。所以 p应该最优选择素数。