参考博客https://blog.csdn.net/qiu931110/article/details/86684241
在多分类任务中我们往往无论是使用sigmod函数还是softmax函数,最终都要经过交叉熵函数计算loss:
、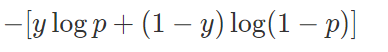
最终在训练网络时,最小化预测概率和标签真实概率的交叉熵,从而得到最优的预测概率分布。如果分类正确p=y,loss=0,否则若p=1-y,loss趋近于无穷大。也就是说交叉熵会尽量拉大正确和错误的差值,这样有两个后果。
1.如果我们的标注数据没有那么准确,导致模型混乱,也就是说鲁棒性不强;
2.如果训练样本不能表征所有样本特征,那么这种强制拉大两者距离的做法很容易过拟合,导致模型泛化能力弱。
为了解决这个问题,在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,用以减轻这个问题。label smoothing将真实概率分布作如下改变:
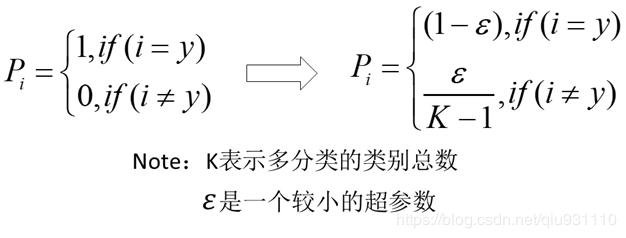
从概率分布上看,他让峰值不那么尖锐:
假设我们的分类只有两个,一个是猫一个不是猫,分别用1和0表示。Label Smoothing的工作原理是对原来的[0 1]这种标注做一个改动,假设我们给定Label Smoothing的值为0.1:

可以看到,原来的[0,1]编码变成了[0.05,0.95]了。这个label_smoothing的值假设为ϵ,那么就是说,原来分类准确的时候,p=1,不准确为p=0,现在变成了p=1−ϵ和ϵ,也就是说对分类准确做了一点惩罚。与之对应,label smoothing将交叉熵损失函数作如下改变:
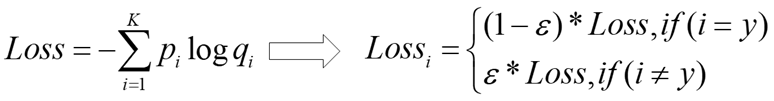
其实我们可以理解为过拟合与模型的能力和参数个数有关,我们相当于在label空间内做了个data augmentation,或者理解为加入了噪声,用来缓解过拟合。
在yolov3中这样使用(无论是focal loss 还是label smooth,yolov3都没有处理交叉熵):
