python 的优缺点:
优点:
1、python 是一门解释性编程语言
2、python 的语法 简洁、优美、可读性好
3、可移值性:python 可跨平台运行
4、拥有大量的第三方库,很多功能只需调用即可,大大缩短开发周期
5、可嵌入性:可与其他语言串接,如不想公布的算法可以用c写,python进行调用
6、排错块
缺点:
1、相对c等编译型语言,耗时长,因为编译型语言是编码完成后一次编译成字节码,再运行,而解释性语言是一行一行编译
2、因为python是开源的,故代码不加密
py2 与 py3 区别:
1、py2 的库有很多其他语言的很多陋习
2、py2 print 引起来即可,也可加括号,py3 需要小括号括起来
3、py2 交互用raw_input ,py3 用input
4、py2 默认使用的是ASCII,py3 使用的是Unicode
5、py2 中有range()、xrange()(生成器),py3中只有range()
变量:
1、以字母、数字、下划线任意组合
2、不能以数字开头
3、区分大小写
4、不能是关键字
5、定义要有意思,且不要太长,不要有中文
6、书写格式为驼峰体或下划线
数据类型之间的转换:
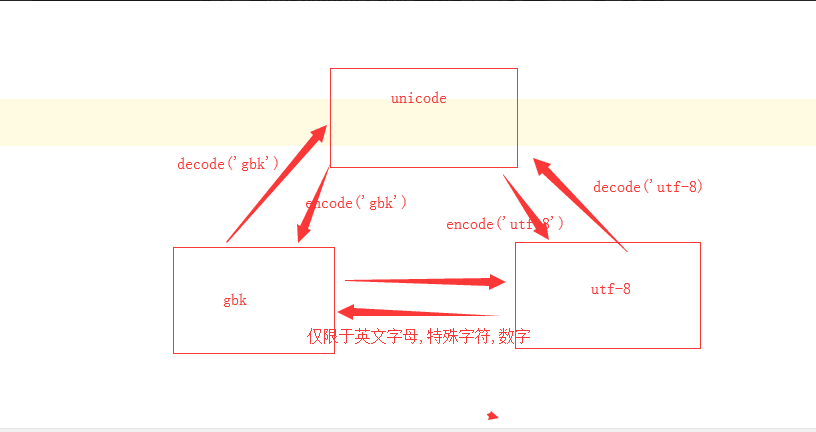
编码:
ASCII ANSI(GBK) UNICODE UTF-8
英文 中文
ASCII 8位、1个字节 无法识别 其他国家无法识别
GBK 8位、2个字节 16位、2个字节 (汉字有9万多个,2**16 =65536不够)
Unicode 8位、4个字节 32位、4个字节 浪费内存
Utf-8 8位、1个字节 24位、3个字节 最少一个字节、动态的(欧洲文字: 16bit 2bytes)
1、除了ASCII码外,其他信息不能直接转换,需要进行编码encoding
2、内存中存的是Unicode、传输和存储用的是(GBK、utf-8……)
3、所有的编码都是继承ascii后写的,所以英文等都还是8个字节
仅仅英文时:

【Python2和Python3之间的区别】
1.从Python2到Python3,很多基本的函数接口变了,甚至是,有些库或函数被去掉了,改名了
Python2和Python3,在很多基本的,最常用的函数方面,接口都变了,最典型的就要数大家最常用的print函数了。
2.第三方库的支持方面,目前来说,还是Python2支持的最好,Python3支持的不太够
Python强大的原因之一是第三方的库很多,功能很强大。
而目前很多Python的第三方的库,很多只提供Python2的。
或者是即使提供了Python3的,但是也不一定很成熟。
二、编码对比
在 Python 中,不论是 Python2 还是 Python3 中,总体上说,字符都只有两大类:
- 通用的 Unicode 字符;
- (unicode 被编码后的)某种编码类型的字符,比如 UTF-8,GBK 等类型的字符。
Python2 中字符的类型:
- str: 已经编码后的字节序列
- unicode: 编码前的文本字符
Python3 中字符的类型:
- str: 编码过的 unicode 文本字符
- bytes: 编码前的字节序列
我们可以认为字符串有两种状态,即文本状态和字节(二进制)状态。Python2 和 Python3 中的两种字符类型都分别对应这两种状态,然后相互之间进行编解码转化。编码就是将字符串转换成字节码,涉及到字符串的内部表示;解码就是将字节码转换为字符串,将比特位显示成字符。
在 Python2 中,str 和 unicode 都有 encode 和 decode 方法。但是不建议对 str 使用 encode,对 unicode 使用 decode, 这是 Python2 设计上的缺陷。Python3 则进行了优化,str 只有一个 encode 方法将字符串转化为一个字节码,而且 bytes 也只有一个 decode 方法将字节码转化为一个文本字符串。
Python2 的 str 和 unicode 都是 basestring 的子类,所以两者可以直接进行拼接操作。而 Python3 中的 bytes 和 str 是两个独立的类型,两者不能进行拼接。
Python2 中,普通的,用引号括起来的字符,就是 str;此时字符串的编码类型,对应着你的 Python 文件本身保存为何种编码有关,最常见的 Windows 平台中,默认用的是 GBK。Python3 中,被单引号或双引号括起来的字符串,就已经是 Unicode 类型的 str 了。
对于 str 为何种编码,有一些前提:
- Python 文件开始已经声明对应的编码
- Python 文件本身的确是使用该编码保存的
- 两者的编码类型要一样(比如都是 UTF-8 或者都是 GBK 等)
这样 Python 解析器才能正确的把文本解析为对应编码的 str。
总体来说,在 Python3 中,字符编码问题得到了极大的优化,不再像 Python2 那么头疼。在 Python3 中,文本总是 Unicode, 由 str 类型进行表示,二进制数据使用 bytes 进行表示,不会将 str 与 bytes 偷偷的混在一起,使得两者的区别更加明显。