参考来源:Python金融大数据分析第八章
提高性能有如下方法
1、Cython,用于合并python和c语言静态编译泛型
2、IPython.parallel,用于在本地或者集群上并行执行代码
3、numexpr,用于快速数值运算
4、multiprocessing,python内建的并行处理模块
5、Numba,用于为cpu动态编译python代码
6、NumbaPro,用于为多核cpu和gpu动态编译python代码
为了验证相同算法在上面不同实现上的的性能差异,我们先定义一个测试性能的函数
def perf_comp_data(func_list, data_list, rep=3, number=1): '''Function to compare the performance of different functions. Parameters func_list : list list with function names as strings data_list : list list with data set names as strings rep : int number of repetitions of the whole comparison number : int number ofexecutions for every function ''' from timeit import repeat res_list = {} for name in enumerate(func_list): stmt = name[1] + '(' + data_list[name[0]] + ')' setup = "from __main__ import " + name[1] + ','+ data_list[name[0]] results = repeat(stmt=stmt, setup=setup, repeat=rep, number=number) res_list[name[1]] = sum(results) / rep res_sort = sorted(res_list.items(), key = lambda item : item[1]) for item in res_sort: rel = item[1] / res_sort[0][1] print ('function: ' + item[0] + ', av. time sec: %9.5f, ' % item[1] + 'relative: %6.1f' % rel)
定义执行的算法如下
from math import * def f(x): return abs(cos(x)) ** 0.5 + sin(2 + 3 * x)
对应的数学公式是
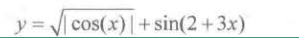
生成数据如下
i=500000
a_py = range(i)
第一个实现f1是在内部循环执行f函数,然后将每次的计算结果添加到列表中,实现如下
def f1(a): res = [] for x in a: res.append(f(x)) return res
当然实现这种方案的方法不止一种,可以使用迭代器或eval函数,我自己加入了使用生成器和map方法的测试,发现结果有明显差距,不知道是否科学:
迭代器实现
def f2(a): return [f(x) for x in a]
eval实现
def f3(a): ex = 'abs(cos(x)) **0.5+ sin(2 + 3 * x)' return [eval(ex) for x in a]
生成器实现
def f7(a): return (f(x) for x in a)
map实现
def f8(a): return map(f, a)
接下来是使用numpy的narray结构的几种实现
import numpy as np a_np = np.arange(i) def f4(a): return (np.abs(np.cos(a)) ** 0.5 + np.sin(2 + 3 * a)) import numexpr as ne def f5(a): ex = 'abs(cos(a)) ** 0.5 + sin( 2 + 3 * a)' ne.set_num_threads(1) return ne.evaluate(ex) def f6(a): ex = 'abs(cos(a)) ** 0.5 + sin(2 + 3 * a)' ne.set_num_threads(2) return ne.evaluate(ex)
上面的f5和f6只是使用的处理器个数不同,可以根据自己电脑cpu的数目进行修改,也不是越大越好
下面进行测试
func_list = ['f1', 'f2', 'f3', 'f4', 'f5', 'f6', 'f7', 'f8'] data_list = ['a_py', 'a_py', 'a_py', 'a_np', 'a_np', 'a_np', 'a_py', 'a_py'] perf_comp_data(func_list, data_list)
测试结果如下
function: f8, av. time sec: 0.00000, relative: 1.0 function: f7, av. time sec: 0.00001, relative: 1.7 function: f6, av. time sec: 0.03787, relative: 11982.7 function: f5, av. time sec: 0.05838, relative: 18472.4 function: f4, av. time sec: 0.09711, relative: 30726.8 function: f2, av. time sec: 0.82343, relative: 260537.0 function: f1, av. time sec: 0.92557, relative: 292855.2 function: f3, av. time sec: 32.80889, relative: 10380938.6
发现f8的时间最短,调大一下时间精度再测一次
function: f8, av. time sec: 0.000002483, relative: 1.0 function: f7, av. time sec: 0.000004741, relative: 1.9 function: f5, av. time sec: 0.028068110, relative: 11303.0 function: f6, av. time sec: 0.031389788, relative: 12640.6 function: f4, av. time sec: 0.053619114, relative: 21592.4 function: f1, av. time sec: 0.852619225, relative: 343348.7 function: f2, av. time sec: 1.009691877, relative: 406601.7 function: f3, av. time sec: 26.035869787, relative: 10484613.6
发现使用map的性能最高,生成器次之,其他方法的性能就差的很远了。但是使用narray数据的在一个数量级,使用python的list数据又在一个数量级。生成器的原理是并没有生成一个完整的列表,而是在内部维护一个next函数,通过一边循环迭代一遍生成下个元素的方法的实现的,所以他既不用在执行时遍历整个循环,也不用分配整个空间,它花费的时间和空间跟列表的大小是没有关系的,map与之类似,而其他实现都是跟列表大小有关系的。
内存布局
numpy的ndarray构造函数形式为
np.zeros(shape, dtype=float, order='C')
np.array(object, dtype=None, copy=True, order=None, subok=False, ndmin=0)
shape或object定义了数组的大小或是引用了另一个一个数组
dtype用于定于元素的数据类型,可以是int8,int32,float8,float64等等
order定义了元素在内存中的存储顺序,c表示行优先,F表示列优先
下面来比较一下内存布局在数组很大时的差异,先构造同样的的基于C和基于F的数组,代码如下:
x = np.random.standard_normal(( 3, 1500000)) c = np.array(x, order='C') f = np.array(x, order='F')
下面来测试性能
%timeit c.sum(axis=0) %timeit c.std(axis=0) %timeit f.sum(axis=0) %timeit f.std(axis=0) %timeit c.sum(axis=1) %timeit c.std(axis=1) %timeit f.sum(axis=1) %timeit f.std(axis=1)
输出如下
100 loops, best of 3: 12.1 ms per loop 10 loops, best of 3: 83.3 ms per loop 10 loops, best of 3: 70.2 ms per loop 1 loop, best of 3: 235 ms per loop 100 loops, best of 3: 7.11 ms per loop 10 loops, best of 3: 37.2 ms per loop 10 loops, best of 3: 54.7 ms per loop 10 loops, best of 3: 193 ms per loop
可知,C内存布局要优于F内存布局
并行计算multiprocessing
首先要pip install multiprocessing安装这个并行库
利用Pool创建进程池的方法来实现并行计算
先看一个简单的例子
from multiprocessing import Pool import os, time, random def long_time_task(name): print ('Run task %s (%s)...' % (name, os.getpid())) start = time.time() time.sleep(random.random() * 3) end = time.time() print ('Task %s runs %0.2f seconds.' % (name, (end - start))) if __name__=='__main__': print ('Parent process %s.' % os.getpid()) p = Pool() for i in range(5): p.apply_async(long_time_task, args=(i,)) print ('Waiting for all subprocesses done...') p.close() p.join() print ('All subprocesses done.')
输出结果为:
Parent process 54034. Waiting for all subprocesses done... Run task 1 (54875)... Run task 2 (54877)... Run task 0 (54873)... Run task 3 (54878)... Task 0 runs 1.06 seconds. Task 2 runs 1.22 seconds. Run task 4 (54873)... Task 1 runs 2.60 seconds. Task 3 runs 2.88 seconds. Task 4 runs 1.88 seconds. All subprocesses done.
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:
p = Pool(5)
就可以同时跑5个进程。
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进
程才能看到上面的等待效果。
上面说明了使用并行计算的方法,下面我们给出一个相同任务,测试它在不同的时间下所花费的时间
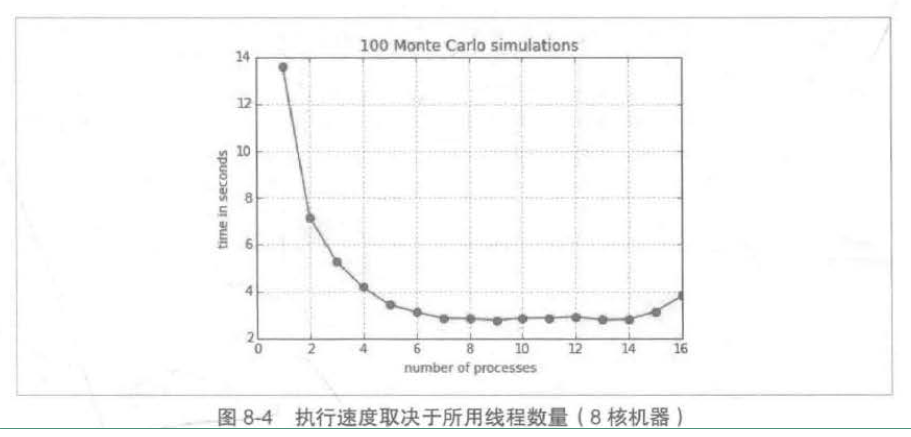
%pylab import multiprocessing as mp import math def simulate_geometric_brownian_motion(p) : M,I = p # time steps, paths S0 = 100; r = 0.05; sigma = 0.2; T = 1.0 # model parameters dt = T / M paths = np.zeros((M+1, I)) paths[0] = S0 for t in range(1,M+1): paths[t] = paths[t -1]*np.exp((r-0.5 * sigma **2)* dt + sigma*math.sqrt(dt)*np.random.standard_normal(I)) return paths I = 10000 # number of paths M = 100 # number of time steps t = 100 # number of tasks/simulations # running on server with 8 cores/16 threads from time import time times = [] for w in range(1, 17): t0 = time() pool = mp.Pool(processes=w) # the pool of workers result = pool.map(simulate_geometric_brownian_motion, t * [(M,I),]) # the mapping of the function to the list of parameter tuples times.append(time() -t0) plt.plot(range(1, 17) , times) plt.plot(range(1, 17) , times , 'ro') plt.grid(True) plt.xlabel('number of processes') plt.ylabel('time in seconds') plt. title( '%d Monte Carlo simulations' % t)
这是书上的源代码对于simulate_geometric_brownian_motion算法,计算其在1到17个线程下所花费时间的不同,原书是在8核16cpu下测试的,测试图如下
实际是在4核的ubuntu虚拟机测试的,并且计算量减少了很多,实际参数为
I = 100 # number of paths M = 10 # number of time steps t = 10 # number of tasks/simulations
测试结果如下
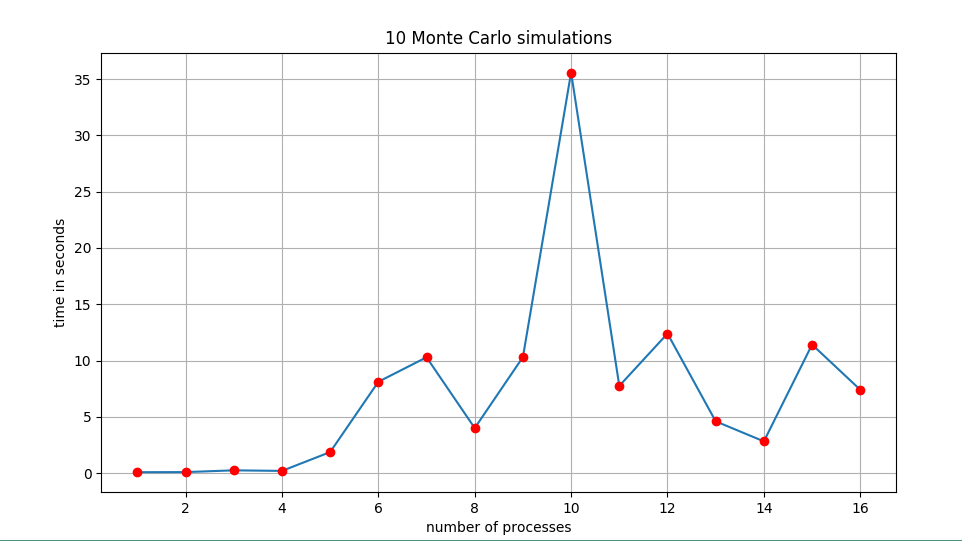
差距太大了,要换电脑了,还以为死机了
未完,待续。。。。。。。。。。。。。。。。。。。。。。