K-means is a very generic clustering algorithm, using four steps to separate the points into clusters. The following part show how it works:
1. Initialization, for every point, choose its cluster ID randomly.
2. Update the center, calculate different centers of points of their own cluster.
3. Reallocation or Assignment, assign the point, with the shortest distance to the centers of its cluster, to the cluster of the center.
4. Check the convergence, back to step 2 if centers or clusters are changed.
We can use the following formulas to evaluate how many clusters should be assign, so called the Davies-Bouldin Index (DBI), which lower is better.

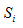 is the average dist. to the center of its cluster, the center can be median , mean etc. and the distance can be Euclidean distance or another.
is the average dist. to the center of its cluster, the center can be median , mean etc. and the distance can be Euclidean distance or another.
 , the dist. between center i and j, or a measure of separation between cluster i and j.
, the dist. between center i and j, or a measure of separation between cluster i and j.
源码链接<View code>
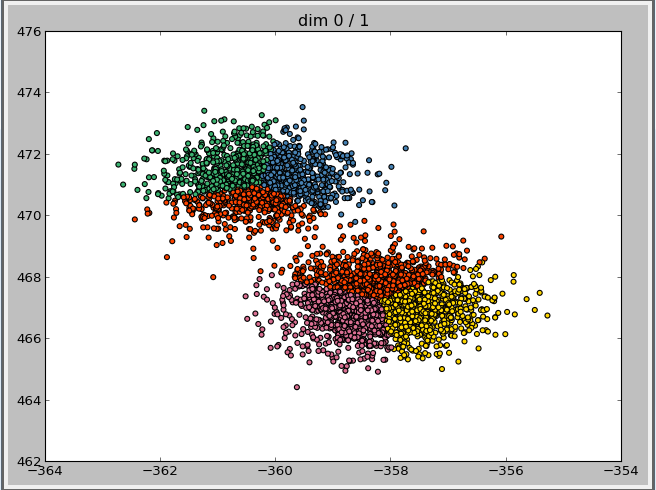
seperate the dataset into 6 parts
the iterations is: 14
by using the initialization of kmeans++.
Vector write with cluster_id finished
Only have one cluster or Max intra cluster distance is 0
the return value will be '0'.
Dunn cluster_num =1 0.0
Dunn cluster_num =2 1.4224045250244335
Dunn cluster_num =3 0.3787325061720893
Dunn cluster_num =4 0.4329611146967893
Dunn cluster_num =5 0.4504612854441182
cluster number is 1, the value will be 0
Davies_Bouldin cluster_num =1 0.0
Davies_Bouldin cluster_num =2 0.436282523420732
Davies_Bouldin cluster_num =3 1.0864451744194168
Davies_Bouldin cluster_num =4 1.0391365922042606
Davies_Bouldin cluster_num =5 1.0061221318606566