作业一:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
代码
`
import urllib
import urllib.request
from bs4 import UnicodeDammit
from bs4 import BeautifulSoup
import threading
print("排名", "电影名称", "导演", "主演", "上映时间", "国家", "电影类型", "评分", "评价人数")
class DouBan:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36 SLBrowser/6.0.1.9171"
}
global count
def getText(self, url, n):
try:
if (n == 0):
url = url
else:
url = "https://movie.douban.com/top250?start=" + str(n) + "&filter=" #url变化的实现,以此实现翻页
req = urllib.request.Request(url, headers=DouBan.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'html.parser')
return soup
except Exception as err:
print(err)
def getData(self, soup):
lis = soup.select('ol[class="grid_view"] li') #每个电影条目存在一个li标签下
for li in lis:
rank = li.select('div[class="pic"] em[class=""]')[0].text.replace("em", '').replace("
", '')
name = li.select('div[class="info"] div a span ')[0].text.replace("span", '').replace("
", '')
people = li.select('div[class="bd"] p')[0].text.replace("p", '').replace("
", '').replace(" ", '')
information = li.select('div[class="bd"] br')[0].text.replace("br", '').replace("
", '').replace(" ",'')
comment = li.select('div[class="bd"] div[class="star"] span[class="rating_num"]')[0].text.replace("span" , '').replace("
", '').replace(" ", '')
number = li.select('div[class="star"] span')[3].text.replace("span", '').replace("
", '').replace(" " ,'')
yinyong = li.select('div[class="bd"] p[class="quote"]')[0].text.replace("p", '').replace("
", '').replace(" ", '')
# 爬取文字相关内容
picurl = li.find('div', attrs={'class': 'pic'}).select("img")[0]["src"] #爬取图片
print(rank,name,people,information,comment,number,yinyong)
T = threading.Thread(target=self.download, args=(picurl,name))
T.setDaemon(False)
T.start()
def download(self, url, name): #图片下载
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:\pycharm\第六次作业\images\" + name + ext, "wb") # 存到对应的文件路径下
fobj.write(data)
fobj.close()
url = "https://movie.douban.com/top250"
n = 0
spider = DouBan() #启动进程
while n <= 225:
html = spider.getText(url, n)
n += 25
spider.getData(html) #记录爬取的数目,每隔25条要改变url
`
实验截图:
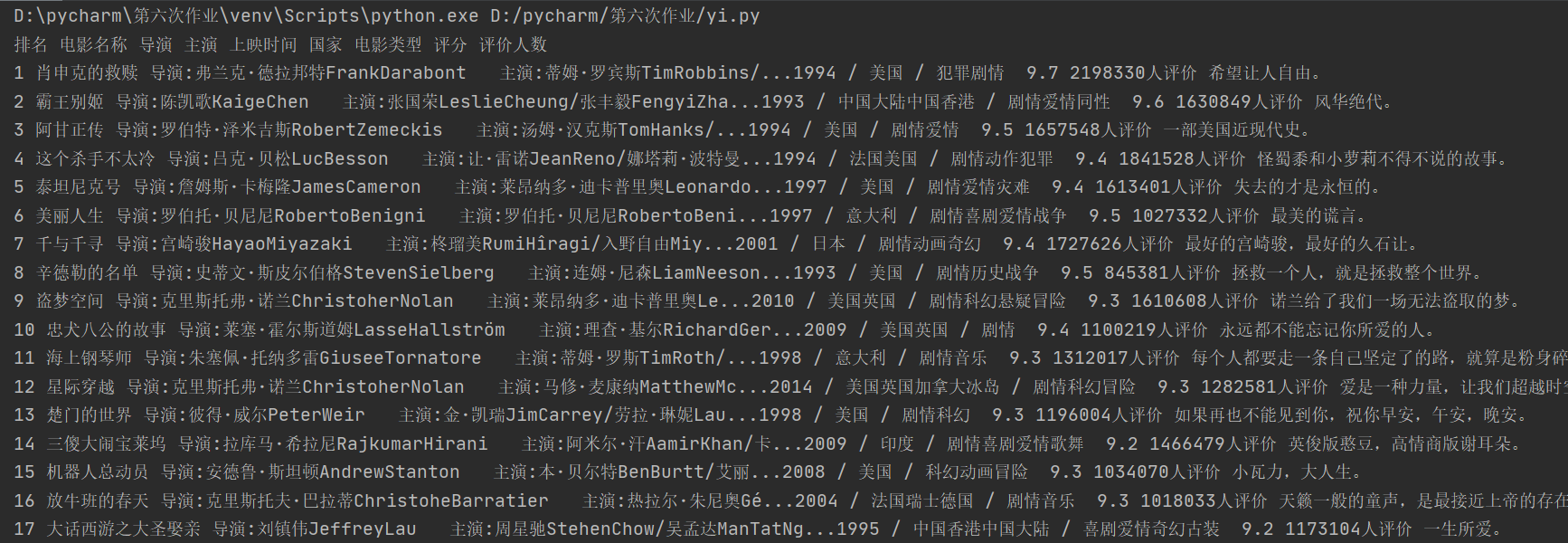
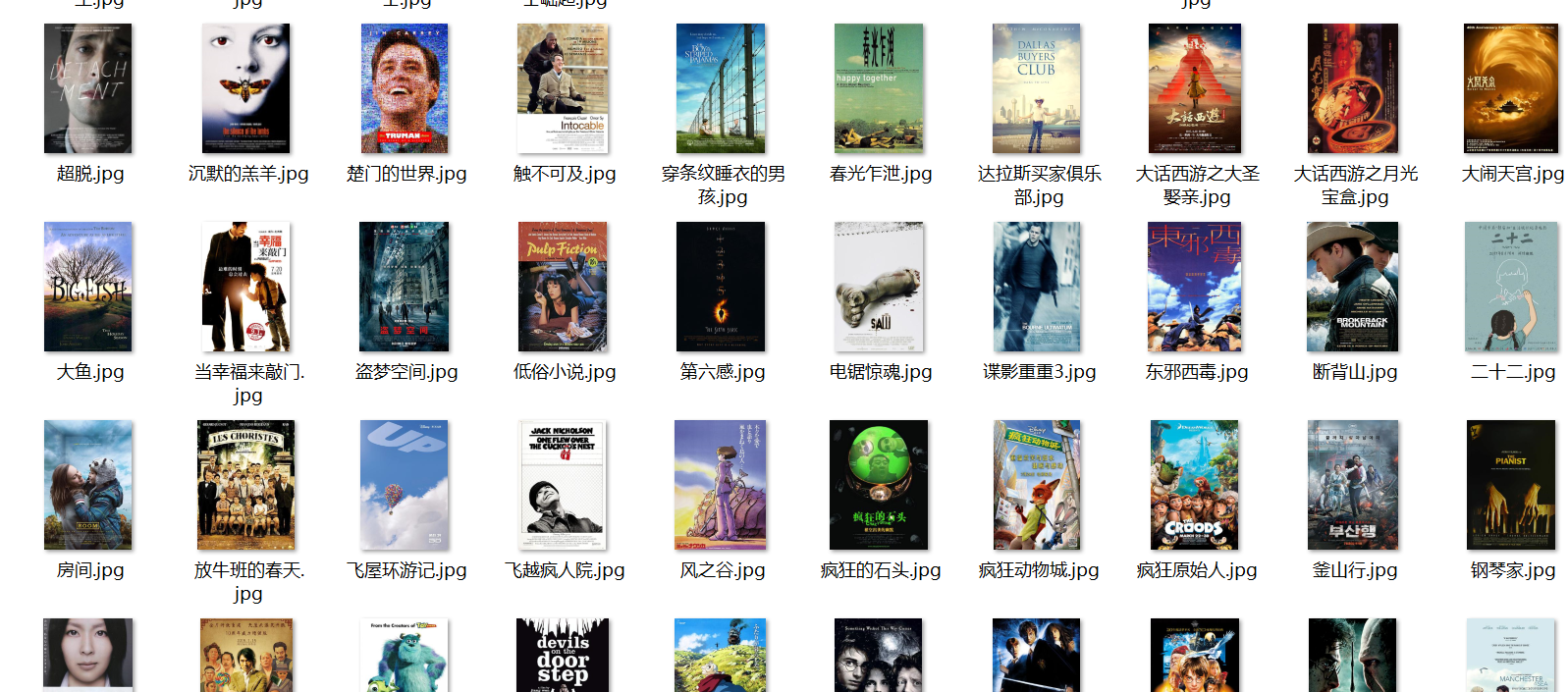
心得体会:
可能是太久没用beautiful soup了,做的时候觉得好难呀,正则表达式怎么就那么别扭又复杂,还是花了很多时间来复习,再加上同学的帮助,才把正则表达式的内容捡起来,后续要在这个版块多花点时间复习,其次,这道题的切入点在于url的切换,如果只用爬取一个页面的内容就会简单很多,刚开始,我还妄图使用双重循环来实现,大概是C语言中毒太深,不过后来,通过在网上看一些实例,有学到实现方法。
作业二:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
代码:
settings.py
`
BOT_NAME = 'university'
SPIDER_MODULES = ['university.spiders']
NEWSPIDER_MODULE = 'university.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'university.pipelines.UniversityPipeline': 300,
}
`
items.py
`
import scrapy
class UniversityItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
no = scrapy.Field()
name = scrapy.Field()
city = scrapy.Field()
officalurl = scrapy.Field()
info = scrapy.Field()
mFile = scrapy.Field()
pass
`
pipelines.py
`
import pymysql
from itemadapter import ItemAdapter
class UniversityPipeline:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36 SLBrowser/6.0.1.9171"
}
def open_spider(self, spider):
print("opened")
try:
#连接数据库
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from university")
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
print(item["no"],item["name"],item["city"],item["officalurl"],item["info"],item["mFile"]) #输出内容
#将爬到的内容插入表
self.cursor.execute("insert into university(no, name, city, "
"officalurl, info, mFile) values (%s,%s,%s,%s,%s,%s)",(item["no"],item["name"],item["city"],item["officalurl"],item["info"],item["mFile"]))
except Exception as err:
print(err)
return item
`
Rank.py
`
import urllib
import scrapy
from bs4 import UnicodeDammit
from university.items import UniversityItem
class RankSpider(scrapy.Spider):
name = 'Rank'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36 SLBrowser/6.0.1.9171"
}
def start_requests(self):
url="https://www.shanghairanking.cn/rankings/bcur/2020"
self.no = 1
yield scrapy.Request(url=url,headers=RankSpider.headers, callback=self.parse)
def parse(self,response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
trs =selector.xpath("//tbody[@data-v-2a8fd7e4]//tr[@data-v-2a8fd7e4]") #根据网页可以发现每个学校的信息都存于一个tr标签中
for tr in trs:
#对每条信息进行逐项爬取
no = tr.xpath("./td[@data-v-2a8fd7e4]/text()").extract_first()
name = tr.xpath("./td[@class='align-left']/a/text()").extract_first()
city = tr.xpath("./td[@data-v-2a8fd7e4][3]/text()").extract_first()
officalurl = tr.xpath("./td[@class='align-left']//a/@href").extract_first()
url = "https://www.shanghairanking.cn"+officalurl
# 进入学校的详情页获取信息
req = urllib.request.Request(url, headers=RankSpider.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
school_mes = scrapy.Selector(text=data)
picurl = school_mes.xpath("//td[@class='univ-logo']//img/@src").extract_first() #获取图片的url
mFile = str(self.no) + ".jpg"
self.no+=1
self.download(picurl)#根据url下载图片
officalurl = school_mes.xpath("//div[@class='univ-website']//a/@href").extract_first()
#有的学校有简介,有的没有
try:
#有简介就进行爬取并输出
info = school_mes.xpath("//div[@class='univ-introduce']//p/text()").extract_first()
print(info)
except:
#没有简介就返回空字符
info = ""
item = UniversityItem()
item["no"]=no.strip() if no else ""
item["name"]= name.strip() if name else ""
item["city"] = city.strip() if city else ""
item["officalurl"] = officalurl.strip() if officalurl else ""
item["info"] =info.strip() if info else ""
item["mFile"] = mFile.strip() if mFile else ""
yield item
except Exception as err:
print(err)
def download(self,url): #爬取图片
try:
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=RankSpider.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:\pycharm\第六次作业\images3\" + str(self.no) + ext, "wb") #图片保存路径
fobj.write(data)
fobj.close()
except Exception as err:
print(err)
`
run.py
`
from scrapy import cmdline
cmdline.execute("scrapy crawl Rank -s LOG_ENABLED=False".split())
`
实验截图:

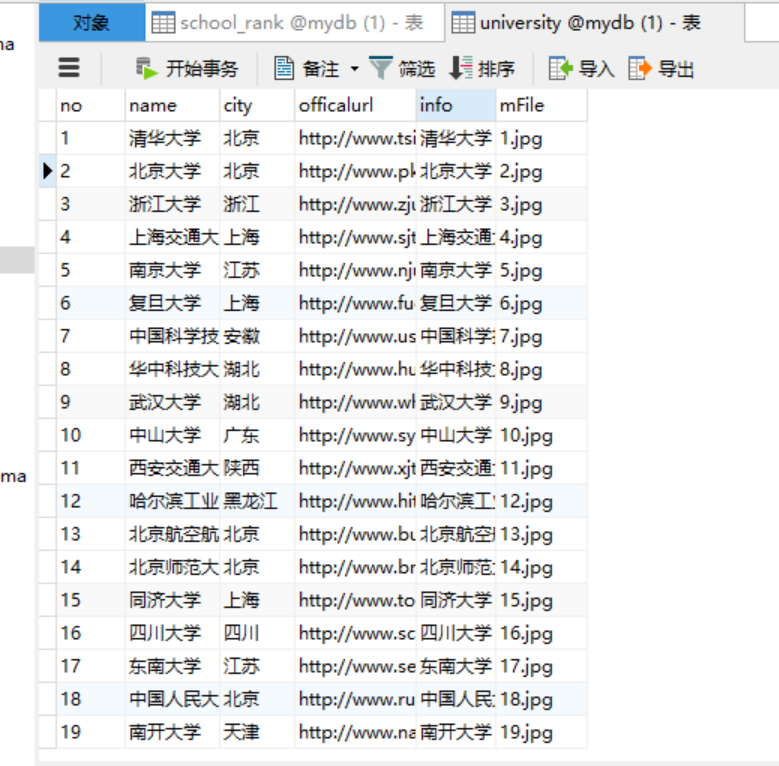

心得体会:
这次作业的切入点就是在进入到排名页后还要点进详情页才能获取到学校的简介内容,也就是要做到url的转换,做到这点的话这道题基本就解决了,其次就是。。xpath比正则表达式方便太多了哈哈哈,不过正则表达式也是要努力掌握的。
实验三:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
代码:
`
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
class Mooc:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36 SLBrowser/6.0.1.9171 "
}
def startUp(self, url):
chrome_options = Options()
self.driver = webdriver.Chrome(options=chrome_options)
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd='123456', db="mydb",
charset="utf8") #连接数据库
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from mooc")
self.opened = True
except Exception as err:
print(err)
self.opened = False
self.driver.get(url)
self.no = 1
def closeUp(self):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
print("closed")
def login(self):
self.driver.find_element_by_xpath("//a[@class='f-f0 navLoginBtn']").click() # 登录
time.sleep(3)
self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']").click() # 点击其他登录方式
time.sleep(3) # 停顿3秒,防止被认为是机器人
self.driver.find_elements_by_xpath("//ul[@class='ux-tabs-underline_hd']//li")[1].click() # 点击手机号登录
time.sleep(3)
iframe_id = self.driver.find_elements_by_tag_name("iframe")[1].get_attribute('id')
self.driver.switch_to.frame(iframe_id)
self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys('13107698505') # 输入手机号
time.sleep(1)
self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys('123456sun') # 输入密码
time.sleep(1)
self.driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click() # 点击登录
time.sleep(3)
self.driver.find_element_by_xpath("//div[@class='u-navLogin-myCourse-t']").click() # 点击个人中心
time.sleep(2)
self.driver.get(self.driver.current_url)
def processSpider(self):
time.sleep(1)
lis = self.driver.find_elements_by_xpath("//div[@class='course-panel-body-wrapper']"
"//div[@class='course-card-wrapper']") # 所有已经参加的课程
for li in lis:
li.find_element_by_xpath(".//div[@class='img']").click()
# 通过点击图片获取每门课的详细信息
last_window = self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
time.sleep(2)
# 进入课程介绍
self.driver.find_element_by_xpath(".//a[@class='f-fl']").click()
last_window = self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
# 开始爬取
try:
Course = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
College = self.driver.find_element_by_xpath("//img[@class='u-img']").get_attribute("alt")
Teacher = self.driver.find_element_by_xpath(
"//div[@class='um-list-slider_con']/div[position()=1]//h3[@class='f-fc3']").text
n = 0
# 教师队伍
while (True):
try:
Team = self.driver.find_elements_by_xpath(
"//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")[n].text
n += 1
except:
break
Count = self.driver.find_element_by_xpath(
"//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
Process = self.driver.find_element_by_xpath(
"//div[@class='course-enroll-info_course-info_term-info_term-time']//span[position()=2]").text
Brief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
except Exception as err:
print(err)
# 关闭窗口
self.driver.close()
old_window1 = self.driver.window_handles[-1]
self.driver.switch_to.window(old_window1)
self.driver.close()
old_window2 = self.driver.window_handles[0]
self.driver.switch_to.window(old_window2)
print(self.no, Course, College, Teacher, Team, Count, Process, Brief)
if self.opened:
self.cursor.execute(
"insert into mooc(Id, Course, College, Teacher, Team, Count, Process, Brief)"
"values(%s, %s, %s, %s, %s, %s, %s, %s)",
(str(self.no), Course, College, Teacher, Team, Count, Process, Brief))
self.no += 1 # 将爬取到的结果写入数据库
def executeSpider(self, url):
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.login()
self.processSpider()
print("Spider closing......")
self.closeUp()
url = 'https://www.icourse163.org/'
spider = Mooc()
spider.executeSpider(url)
`
实验截图:
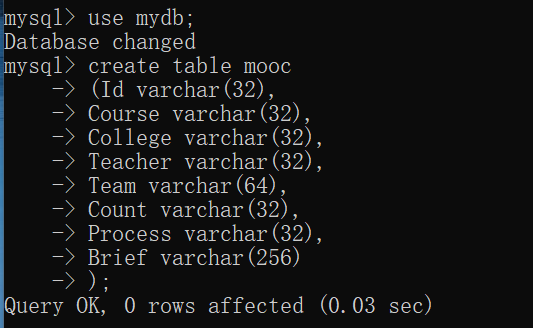

心得体会:
最开始看到这道题的时候有点无从下手,不过后来就一步一步地按正常操作进行,找到每个页面的切入点,然后进行爬取。这道题的主要难点就是页面之间的切换,解决了这一点,剩下的就很简单了。
总结:
不知不觉就最后一次作业了,在繁重的作业任务下感觉这学期过得格外的快,很感谢吴伶老师这一学期的帮助,感觉爬虫是个很神奇的东西,没有接触的时候听到这个词就觉得很高大上,现在了解了还是惊叹于它的神奇,几行代码就能把别的网站的东西搞到手,有时间的话会在继续学习这方面的内容的。吴伶老师也很好,笑起来很可(han)爱(han)(不是)。