历史
1990年 Python 诞生;2000年 Python 2.0 发布;2008年 Python 3.0 发布;2010年 Python 2.7 发布(最后一个2.x 版本)。
Python的作者说,Python2.x 已经是遗产,Python3.x 是现在和未来的语言。
语言特点
语法简洁;跨平台;可扩展;开放源码;类库丰富。
最典型的“编程语言两问”:
你了解你学过的每种编程语言的特点吗?
你能根据不同的产品需求,选用合适的编程语言吗?
举个例子,Python 的优点之一是特别擅长数据分析,所以广泛应用于人工智能、机器学习等领域,如机器学习中 TensorFlow 的框架,就是用 Python 写的。
但是涉及到底层的矩阵运算等等,还是要依赖于 C++ 完成,因为 C++ 的速度快,运行效率更高。
事实上,很多公司都是这样,服务器端开发基于 Python,但底层的基础架构依赖于 C++。这就是典型的“不同需求选用不同语言”。
版本选择
Python最流行的发行版Anaconda
学习网站
Python官方文档: https://www.python.org/doc/
iPython: https://www.ipython.org/
jupyter notebook: http://jupyter-notebook.readthedocs.io/en/latest/
sublime text: https://www.sublimetext.com
PyCharm: https://www.jetbrains.com/pycharm/
pip: https://pip.pypa.io/en/stable/installing/
在线编程:http://www.dooccn.com/python3/
Jupyter Notebook
按照 Jupyter 创始人 Fernando Pérez 的说法,他最初的梦想是做一个综合 Ju (Julia)、Py (Python)和 R 三种科学运算语言的计算工具平台,所以将其命名为 Ju-Py-te-R。
发展到现在,Jupyter 已经成为一个几乎支持所有语言,能够把软件代码、计算输出、解释文档、多媒体资源整合在一起的多功能科学运算平台。
Stack Overflow: https://stackoverflow.com/
Jupyter Notebook: https://jupyter.org/
Jupyter 官方的 Binder 平台:https://mybinder.org/
介绍文档:https://mybinder.readthedocs.io/en/latest/index.html
Google 提供的 Google Colab 环境介绍:https://colab.research.google.com/notebooks/welcome.ipynb
基本数据类型
int 整数
float 浮点数
bool 布尔值 True False
str 字符串,如 ‘python’, "python",如果字符串里有',则采用" "


cindy@ubuntu:~$ python3 Python 3.8.10 (default, Jun 2 2021, 10:49:15) [GCC 9.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> >>> type(1) <class 'int'> >>> type(2.2) <class 'float'> >>> type(True) <class 'bool'> >>> type('1') <class 'str'> >>> >>> int('123') 123 >>> str(123) '123' >>> >>> bool(123) True >>> bool(0) False >>> >>> float(1) 1.0 >>> int(1.0) 1 >>>
Misc
i > 0 and i < 10 i = int(s) print(type(i)) # i is a int import time time.sleep(1)
序列
序列指它的成员都是有序排列,并且可以通过下标偏移量访问到它的一个或几个成员。
字符串、列表 list、元组 tuple 三种类型都属于序列。
字符串 “abcd”
元组 (“abc”, “def”),不可修改
列表 [ 0, “abcd”],可修改
序列的基本操作
in, not in 成员关系操作符,对象[not] in 序列;
+ 连接操作符,序列 + 序列;
* 重复操作符,序列 * 整数;
[:] 切片操作符,序列[0:整数]
字符串
字符串是由独立字符组成的一个序列,是不可变的(immutable),通常包含在单引号('')双引号("")或者三引号之中(''' '''或""" """,两者一样)。
Python 同时支持这三种表达方式,很重要的一个原因就是,这样方便你在字符串中,内嵌带引号的字符串。
Python 的三引号字符串,则主要应用于多行字符串的情境,比如函数的注释等等。
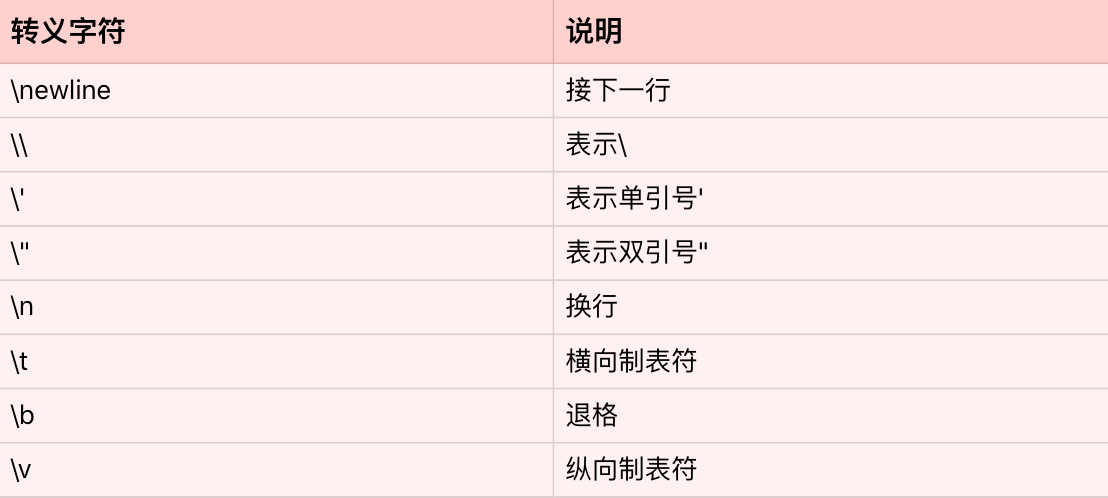
Python 也支持转义字符。所谓的转义字符,就是用反斜杠开头的字符串,来表示一些特定意义的字符。
s1 = 'hello' s2 = "hello" s3 = """hello""" s1 == s2 == s3 True def calculate_similarity(item1, item2): """ Calculate similarity between two items Args: item1: 1st item item2: 2nd item Returns: similarity score between item1 and item2 """ s = 'a b c' print(s) a b c len(s) 5
常见的的转义字符:
Python 中字符串的改变,通常只能通过创建新的字符串来完成。
比如把'hello'的第一个字符'h',改为大写的'H':
s = 'H' + s[1:] s = s.replace('h', 'H')
第一种方法,是直接用大写的'H',通过加号'+'操作符,与原字符串切片操作的子字符串拼接而成新的字符串。
第二种方法,是直接扫描原字符串,把小写的'h'替换成大写的'H',得到新的字符串。
i = '3' a = '01234' if i in a: print(a*3) print(a+a) print(a[1:4]) print(a[-1]) print('4' in a) print('4' not in a) 运行结果: 012340123401234 0123401234 123 4 True False
元组
# 元组的赋值 (month,day) = (11, 8) # 元组的嵌套 ((1, 2), (2, 5)) # 元组的比较 >>> (4) > (5) False >>> (4) < (5) True >>> (1, 4) > (2, 4) False >>> (1, 4) > (1, 3) True >>> # filter >>> a = (1, 3, 5, 7) >>> b = 4 >>> filter(lambda x: x < b, a) <filter object at 0x7f25b3f71c10> # 列出 a 中小于 b 的元素 >>> list(filter(lambda x: x < b, a)) [1, 3] # 列出 a 中小于 b 的元素个数 >>> len(list(filter(lambda x: x < b, a))) 2
列表
a_list = [123, 'abc'] a_list.append('xyz') print(a_list) a_list.remove('abc') print(a_list) 运行结果: [123, 'abc', 'xyz'] [123, 'xyz']
列表和元组都是有序的,可以存储任意数据类型的集合,主要区别:
列表是动态的,长度可变,可以随意地增加、删减或者改变元素(mutable);存储空间略大于元组,性能略逊于元组。
元组是静态的,长度固定,无法增加、删减或者改变(immutable);相对于列表更加轻量级,性能稍优。
l = [1, 2, 'hello', 'world'] # 列表中同时含有int和string类型的元素 tup = ('jason', 22) # 元组中同时含有int和string类型的元素 l = [1, 2, 3, 4] l[3] = 40 # 索引从0开始,l[3]表示访问列表的第四个元素 l [1, 2, 3, 40] tup = (1, 2, 3, 4) tup[3] = 40 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment # 要“改变”已有元组,只能重新开辟一块内存,创建新的元组 tup = (1, 2, 3, 4) new_tup = tup + (5, ) # 创建新的元组new_tup,并依次填充原元组的值 new _tup (1, 2, 3, 4, 5) l = [1, 2, 3, 4] l.append(5) # 添加元素5到原列表的末尾 l [1, 2, 3, 4, 5] # Python 中的列表和元组都支持负数索引 # -1 表示最后一个元素,-2 表示倒数第二个元素,以此类推 l = [1, 2, 3, 4] l[-1] 4 tup = (1, 2, 3, 4) tup[-1] 4 # 列表和元组都支持切片操作 l = [1, 2, 3, 4] l[1:3] # 返回列表中索引从1到2的子列表 [2, 3] tup = (1, 2, 3, 4) tup[1:3] # 返回元组中索引从1到2的子元组 (2, 3) # 列表和元组都可以随意嵌套 l = [[1, 2, 3], [4, 5]] # 列表的每一个元素也是一个列表 tup = ((1, 2, 3), (4, 5, 6)) # 元组的每一个元素也是一个元组
# 列表和元组可以相互转换 list((1, 2, 3)) [1, 2, 3] tuple([1, 2, 3]) (1, 2, 3)
列表和元组常用的内置函数
# count(item)表示统计列表/元组中 item 出现的次数 # index(item)表示返回列表/元组中 item 第一次出现的索引 l = [3, 2, 3, 7, 8, 1] l.count(3) 2 l.index(7) 3 # list.reverse()和 list.sort()分别表示原地倒转列表和排序(注意,元组没有内置的这两个函数) l.reverse() l [1, 8, 7, 3, 2, 3] l.sort() l [1, 2, 3, 3, 7, 8] tup = (3, 2, 3, 7, 8, 1) tup.count(3) 2 tup.index(7) 3 # reversed()和 sorted()同样表示对列表/元组进行倒转和排序 list(reversed(tup)) # reversed()返回一个倒转后的迭代器,list()函数再将其转换为列表 [1, 8, 7, 3, 2, 3] sorted(tup) # sorted()返回排好序的新列表 [1, 2, 3, 3, 7, 8]
列表和元组存储方式的差异
l = [1, 2, 3] l.__sizeof__() 64 tup = (1, 2, 3) tup.__sizeof__() 48
可以看到,对列表和元组,我们放置了相同的元素,但是元组的存储空间,却比列表要少 16 字节。这是为什么呢?
由于列表是动态的,所以它需要存储指针,来指向对应的元素(上述例子中,对于 int 型,8 字节)。
另外,由于列表可变,所以需要额外存储已经分配的长度大小(8 字节),这样才可以实时追踪列表空间的使用情况,当空间不足时,及时分配额外空间。
l = [] l.__sizeof__() # 空列表的存储空间为40字节 40 l.append(1) l.__sizeof__() 72 # 加入了元素1之后,列表为其分配了可以存储4个元素的空间 (72 - 40)/8 = 4 l.append(2) l.__sizeof__() 72 # 由于之前分配了空间,所以加入元素2,列表空间不变 l.append(3) l.__sizeof__() 72 # 同上 l.append(4) l.__sizeof__() 72 # 同上 l.append(5) l.__sizeof__() 104 # 加入元素5之后,列表的空间不足,所以又额外分配了可以存储4个元素的空间
我们可以看到,为了减小每次增加 / 删减操作时空间分配的开销,Python 每次分配空间时都会额外多分配一些,这样的机制(over-allocating)保证了其操作的高效性:增加 / 删除的时间复杂度均为 O(1)。
元组长度大小固定,元素不可变,所以存储空间固定。
列表和元组的性能
通过学习列表和元组存储方式的差异,我们可以得出结论:元组要比列表更加轻量级一些,所以总体上来说,元组的性能速度要略优于列表。
另外,Python 会在后台,对静态数据做一些资源缓存(resource caching)。通常来说,因为垃圾回收机制的存在,如果一些变量不被使用了,Python 就会回收它们所占用的内存,返还给操作系统,以便其他变量或其他应用使用。
但是对于一些静态变量,比如元组,如果它不被使用并且占用空间不大时,Python 会暂时缓存这部分内存。这样,下次我们再创建同样大小的元组时,Python 就可以不用再向操作系统发出请求,去寻找内存,而是可以直接分配之前缓存的内存空间,这样就能大大加快程序的运行速度。
下面的例子,是计算初始化一个相同元素的列表和元组分别所需的时间。我们可以看到,元组的初始化速度,要比列表快 5 倍。
python3 -m timeit 'x=(1,2,3,4,5,6)' 20000000 loops, best of 5: 9.97 nsec per loop python3 -m timeit 'x=[1,2,3,4,5,6]' 5000000 loops, best of 5: 50.1 nsec per loop
但如果是索引操作的话,两者的速度差别非常小,几乎可以忽略不计。
python3 -m timeit -s 'x=[1,2,3,4,5,6]' 'y=x[3]' 10000000 loops, best of 5: 22.2 nsec per loop python3 -m timeit -s 'x=(1,2,3,4,5,6)' 'y=x[3]' 10000000 loops, best of 5: 21.9 nsec per loop
字典和集合
字典是一系列由键(key)和值(value)配对组成的元素的集合。
在 Python3.7+,字典被确定为有序(注意:在 3.6 中,字典有序是一个 implementation detail,在 3.7 才正式成为语言特性,因此 3.6 中无法 100% 确保其有序性),而 3.6 之前是无序的,其长度大小可变,元素可以任意地删减和改变。
相比于列表和元组,字典的性能更优,特别是对于查找、添加和删除操作,字典都能在常数时间复杂度内完成。
而集合和字典基本相同,唯一的区别,就是集合没有键和值的配对,是一系列无序的、唯一的元素组合。
字典和集合的内部结构都是一张哈希表。
对于字典而言,这张表存储了哈希值(hash)、键和值这 3 个元素;
而对集合来说,区别就是哈希表内没有键和值的配对,只有单一的元素了。
# 字典和集合的创建 d1 = {'name': 'jason', 'age': 20, 'gender': 'male'} d2 = dict({'name': 'jason', 'age': 20, 'gender': 'male'}) d3 = dict([('name', 'jason'), ('age', 20), ('gender', 'male')]) d4 = dict(name='jason', age=20, gender='male') d1 == d2 == d3 ==d4 True s1 = {1, 2, 3} s2 = set([1, 2, 3]) s1 == s2 True # 字典和集合可以是混合类型 s = {1, 'hello', 5.0} # 字典访问可以直接索引键,如果不存在,就会抛出异常 d = {'name': 'jason', 'age': 20} d['name'] 'jason' d['location'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'location' # 可以使用 get(key, default) 函数来进行索引 d = {'name': 'jason', 'age': 20} d.get('name') 'jason' d.get('location', 'null') 'null' # 集合并不支持索引操作,因为集合本质上是一个哈希表,和列表不一样。 s = {1, 2, 3} s[0] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'set' object does not support indexing # 判断一个元素在不在字典或集合内 s = {1, 2, 3} 1 in s True 10 in s False d = {'name': 'jason', 'age': 20} 'name' in d True 'location' in d False
当然,除了创建和访问,字典和集合也同样支持增加、删除、更新等操作。
d = {'name': 'jason', 'age': 20}
d['gender'] = 'male' # 增加元素对'gender': 'male'
d['dob'] = '1999-02-01' # 增加元素对'dob': '1999-02-01'
d
{'name': 'jason', 'age': 20, 'gender': 'male', 'dob': '1999-02-01'}
d['dob'] = '1998-01-01' # 更新键'dob'对应的值
d.pop('dob') # 删除键为'dob'的元素对
'1998-01-01'
d
{'name': 'jason', 'age': 20, 'gender': 'male'}
s = {1, 2, 3}
s.add(4) # 增加元素4到集合
s
{1, 2, 3, 4}
s.remove(4) # 从集合中删除元素4
s
{1, 2, 3}
不过要注意,集合的 pop() 操作是删除集合中最后一个元素,可是集合本身是无序的,你无法知道会删除哪个元素,因此这个操作得谨慎使用。
对于字典,我们通常会根据键或值,进行升序或降序排序:
d = {'b': 1, 'a': 2, 'c': 10}
d_sorted_by_key = sorted(d.items(), key=lambda x: x[0]) # 根据字典键的升序排序
d_sorted_by_value = sorted(d.items(), key=lambda x: x[1]) # 根据字典值的升序排序
d_sorted_by_key
[('a', 2), ('b', 1), ('c', 10)]
d_sorted_by_value
[('b', 1), ('a', 2), ('c', 10)]
这里返回了一个列表。列表中的每个元素,是由原字典的键和值组成的元组。
而对于集合,其排序和前面讲过的列表、元组很类似,直接调用 sorted(set) 即可,结果会返回一个排好序的列表。
s = {3, 4, 2, 1}
sorted(s) # 对集合的元素进行升序排序
[1, 2, 3, 4]
dict1 = {} print(type(dict1)) dict1 = {'x':1, 'y':2} dict1['z'] = 3 print(dict1) for key in dict1.keys(): print('%s: %d' %(key, dict1[key])) 运行结果: <class 'dict'> {'x': 1, 'y': 2, 'z': 3} x: 1 y: 2 z: 3 # 列表推导式 # 从 1 到 10 所有偶数的平方 alist = [i*i for i in range(1,11) if(i%2 == 0)] print(alist) # 字典推导式 # 初始化为 0 a = ('month', 'day') dict2 = {i:0 for i in a} print(dict2) 运行结果: [4, 16, 36, 64, 100] {'month': 0, 'day': 0}
条件与循环
# 条件语句 if condition_1: statement_1 elif condition_2: statement_2 ... elif condition_i: statement_i else: statement_n # 循环语句 for item in <iterable>: ... while condition: ....
#条件语句 s = input("Please enter s:") # s is a string if s == '123': print('s = 123') else: print('s != 123') #循环语句 #i = 4 5 for i in range(4,6): j = i*2 print('i=%d, j=%d' %(i,j)) while True: print('True') break 运行结果: Please enter s:12 s != 123 i=4, j=8 i=5, j=10 True
文件操作
open() 打开文件
read() 输入
readline() 输入一行
seek() 文件内移动
write() 输出
close() 关闭文件
# open mode: r read, w write, a append file1 = open('name.txt','a') file1.write('cindy jack pony') file1.close() file2 = open('name.txt') # default mode: r print(file2.tell()) print(file2.read()) print(file2.tell()) # seek(offset, whence) whence: 0 file start, 1 file current, 2 file tail file2.seek(11, 0) print('seek: %d' %file2.tell()) print('read: %s' %file2.read()) file2.seek(0, 0) print('seek: %d' %file2.tell()) #print('readline: %s' %file2.readline()) for line in file2.readlines(): print(line) print('===') file2.close() 运行结果: 0 cindy jack pony 15 seek: 11 read: pony seek: 0 cindy === jack === pony ===
输入与输出
input() 函数暂停程序运行,同时等待键盘输入;直到回车被按下,函数的参数即为提示语,输入的类型永远是字符串型(str)。
print() 函数则接受字符串、数字、字典、列表甚至一些自定义类的输出。
异常
异常是在出现错误时采用正常控制流以外的动作。
异常处理的一般流程是: 检测到错误,引发异常;对异常进行捕获的操作
try:
<监控异常>
except Exception[, reason]:
<异常处理代码>
finally:
<无论异常是否发生都执行>
try: year = int(input('input year:')) except ValueError: print('year should be a integer.') try: print(1/'a') except Exception as e: print(' %s' %e) try: raise NameError('helloError') except NameError: print('my custom error') try: a = open('name.txt') except Exception as e: print(e) finally: a.close()
模块
模块是在代码量变得相当大之后,为了将需要重复使用的有组织的代码段放在一起,这部分代码可以附加到现有的程序中,附加的过程叫做导入(import)。
导入模块的一般写法:
import 模块名称
from 模块名称 import 方法名
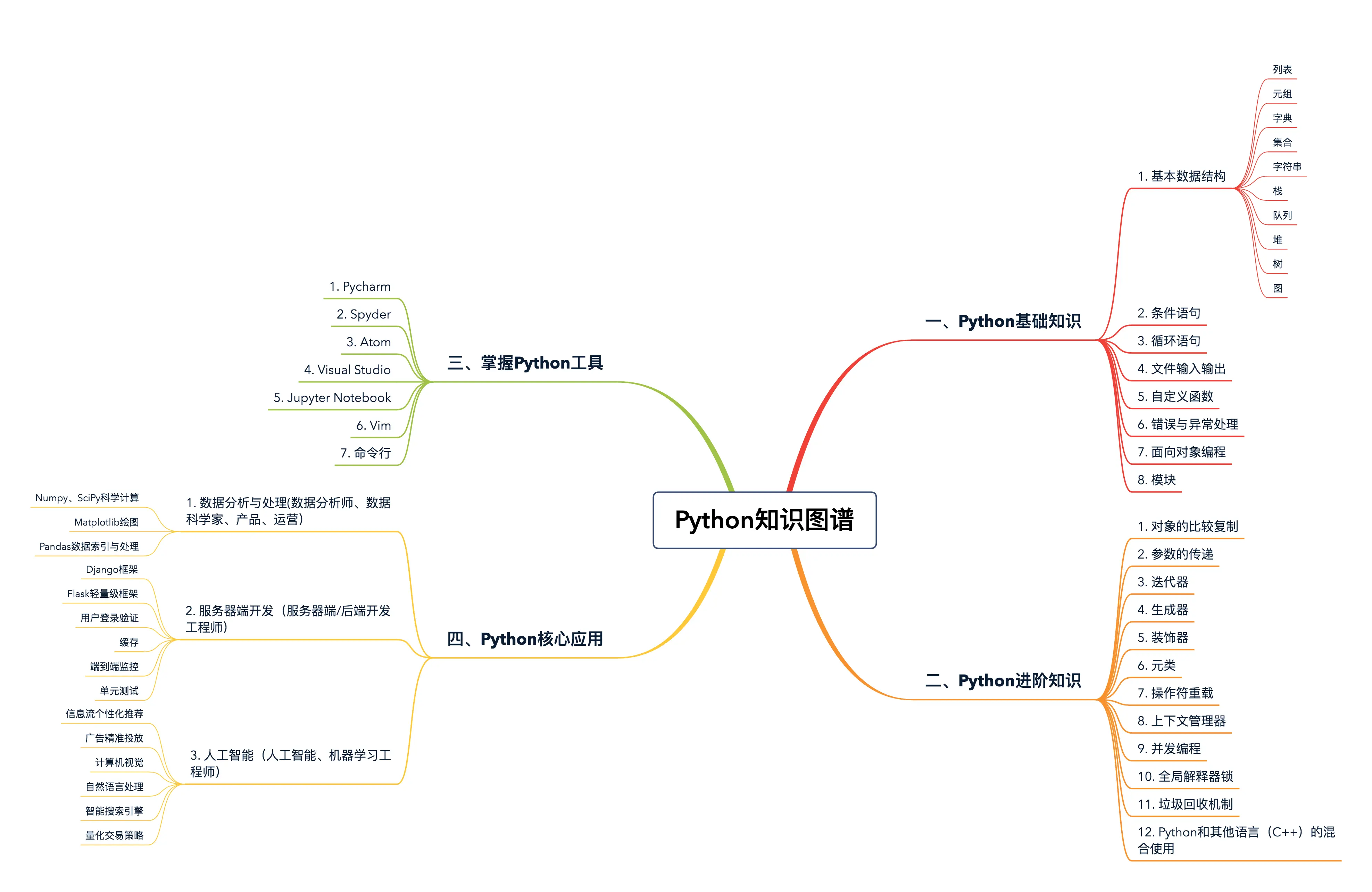
知识图谱