一: 库
1.增
创建库: create database 库名 charset utf8;
说明;#造一个数据库就相当于建了一个文件夹创建,造数据库,取一个名,指定字符编码utf8
2.查
查看创建库是否成功: show create database 库名;
查看全部的数据库: : show databases;
3.改
改字符编码对象: alter database 库名 charset gbk;
说明;对象是数据库,数据库下的某一个具体对象,eg:改字符编码,为gbk
二:表
PS:创建表之前要先创建库,然后从库切换到库这个目录下:语法: use 库名;
确认是否切换成功或者查看当前所在文件夹: select database();
a.增 例如:库名为db2,表名为t4
新增一个表: create table t4(id int,name char(设置长度));
说明:创建表指定表名称t4 (id号类型,名字类型); #id,name是可改变的字段名
b.查
1: 查看具体的才新建的表,或者当前的表:show create table t4;
2: 查看当前所在表: desc t4;
3: 查看当前库下所有的表名: show tables;
4: 查看表详细结构,可加G
c.改 #改表的字段
1:改字段类型的参数:
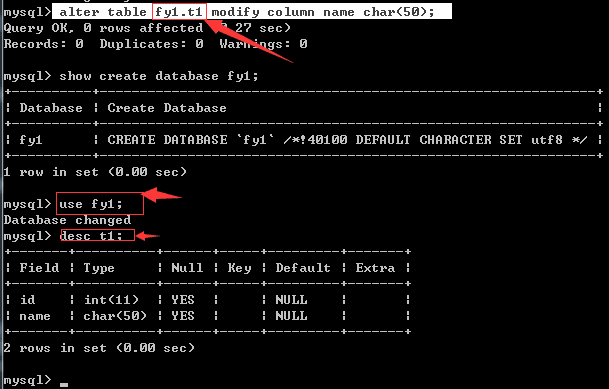
改字段类型的参数: alter table t4 modify name char(6);
说明:改表,改t4,修改 name字段[name是在增加的时候创建的],改他的类型,指定 宽度为(6),默认情况下宽度为
能想到的名字宽度无非就是存储name时是一个字节还是多个字节.
下图是在库目录下,只改name字段数据类型的长度:
2: 改字段名称
改字段名称: alter table t4 change name NAME char(7);
说明:改表,改t4,改变name,后边跟改变成什么样子,同时char类型也可以改为7.这个俩个参数都能改.
3: 改表的结构:
- 指定表类型/存储引擎:
创建表时指定: create table t1(id int)engine =innodb;
说明:在硬盘上产生俩个文件frm,idb 其中frm存放表结构,idb存放的是数据文件
以下为了解部分:
create table t2(id int)engine = memory; #存在内存里面,只有frm文件,存放表结构
create table t3(id int)engine = blackhole; #存进去就没有了,只有frm文件,存放表结构
create table t4(id int)engine = myisam;#在硬盘上存储 frm->表结构MYD->data文件,MYI->索引文件
还可以往表里面增加一条记录
insert into t1 values(1);
insert into t2 values(1);
insert into t3 values(1);
insert into t4 values(1);
PS:不同类型的文件他对应的存取机制是不一样的.
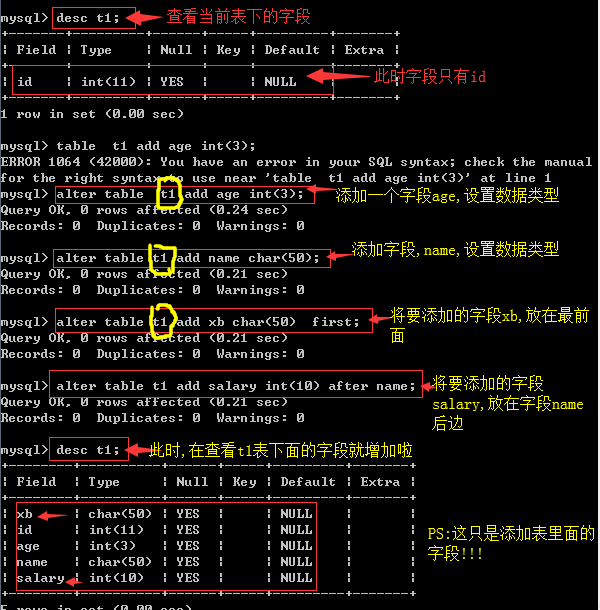
- 添加字段:
是在原有的.同一个表里面添加.
语法:
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…],
ADD 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…]FIRST;
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;
实例:
- 删除字段:
语法: ALTER TABLE 表名 DROP 字段名;
实例:

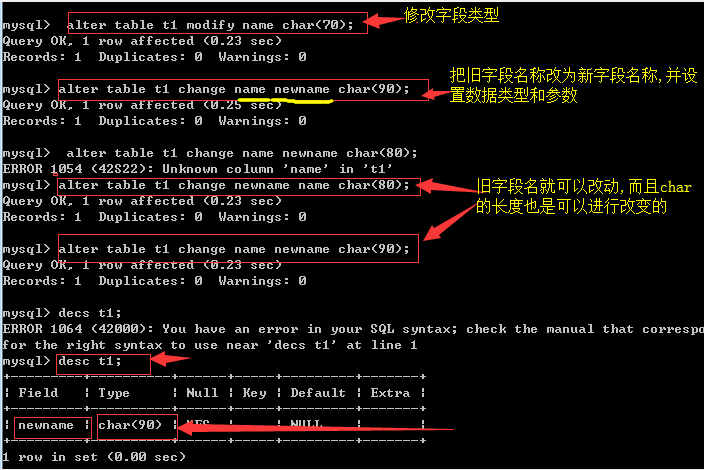
- 修改字段类型modify, 和改字段名称
语法:
ALTER TABLE 表名
MODIFY 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
实例: PS:不能将旧字段名name 改成 name.
d:复制表:
1.复制表结构+记录
(key不会复制: 主键、外键和索引)
备好A被复制的表,就从mysql自带的user表
查看user表的所有信息
select * from mysql.user;
1.取出被复制的mysql表下的host,user字段
select host,user from mysql.user;
2.准备好B,在造一个库, db3
create database db3 charset utf8;
3.切换到表目录下,
use db3
4.将A表的host,user信息复制到B表
create table t1 select host,user from mysql.user;
理论是:将A表查出的信息,[select host,user from mysql.user;] 丢给 t1,
而t1,则是db3库下create table t1新建的表
2.只复制表结构:
a. 取A表的部分结构:从mysql下的user表取host.user字段
1.条件为假,查不到任何记录,即为拷复制表结构
select host,user from mysql.user where 1>3;
2.理解为粘贴表结构
create table t2 select host,user from mysql.user where 1>3;
#理论是:将A取出的结构复制给t2,而t2则是db3库下create table t2新建的表
,b. 取A表的全部结构:
create table t3 like mysql.user;
一步完成,将mysql下的user表全部结构 粘贴到新建的表t3下面.不能拷贝表的数据
e:删除表
DROP TABLE 表名;
补充概念:什么是存储引擎?
现实生活中我们用来存储数据的文件应该有不同的类型:比如存文本用txt类型,存表格用excel,存图片用png等
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。
存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方
法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)