题记
因为前些日子我一直看到文件泄露的漏洞,什么.git什么的,于是一直想自己整一个检测的批量脚本,尝试自己写了一个,效果却不太符合心意。今天偶然看到一个推荐git等漏洞利用的工具,我以为是批量扫的工具,后来发现是扫到漏洞后利用漏洞下载源码的工具。工具地址:https://github.com/0xHJK/dumpall。于是我觉得还是一劳永逸吧,终于百度大法看到一个大哥的脚本。
批量扫描网站备份文件的脚本
此脚本思路:把要检测的网站放到tar.txt里面,通过在url后拼接敏感文件名字进行访问,通过响应包判断漏洞是否存在,存在的话把漏洞路径保存在bfvul.txt中。
import requests import re import multiprocessing list = ['wwwroot.rar','wwwroot.zip','新建文件夹.rar','新建文件夹.zip','www.rar','www.zip','web.rar','web.zip'] headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0'} content_type = ['application/x-rar','application/x-gzip','application/zip','application/octet-stream','application/x-7z-compressed'] def main(i): url1 = i.strip(' ') c = re.findall(r'https?://(?:[-w.]|(?:%[da-fA-F]{6}))+',url1) url2 = (',').join(str(x) for x in c) for i in list: try: b = url2 +'/'+ i r = requests.head(url = b ,headers = headers) if r.headers['Content-Type'] in content_type: with open (r'bfvul.txt','a', encoding ='utf-8' ) as f: a = f.write('存在备份文件'+ ':' + b + ' ') else: print('不存在'+b) except: print('无法连接') if __name__ == '__main__': p = multiprocessing.Pool(50)#线程数 with open(r'tar.txt','r',encoding = 'utf-8') as f: a = f.readlines() for i in a: p.apply_async(main,(i,)) p.close() p.join()
经过测试成功跑出来一些网站的备份文件,此脚本还是很好用的,如果想添加路径可在数组内添加。

批量扫描git、svn等脚本
经过思考,我尝试改造一下尝试跑git、svn这种漏洞,但是我并没有遇到过svn泄露不太清楚返回包的内容,因此这里的判断行为是,响应200后进行下一轮判断,如果包含git响应内容存到git.txt中,不存在就放到qita.txt中,以后遇到在优化吧,还是挺好用的。
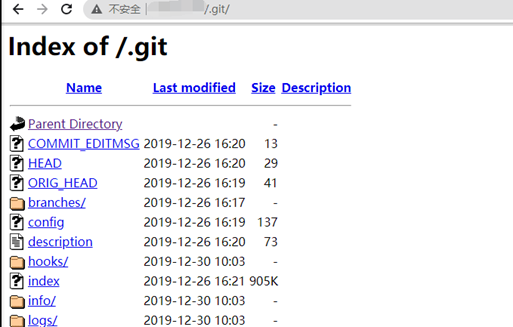
import requests import re import multiprocessing list = ['.git','.svn','.DS_Store','robots.txt'] headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0'} def main(i): url1 = i.strip(' ') c = re.findall(r'https?://(?:[-w.]|(?:%[da-fA-F]{6}))+',url1) url2 = (',').join(str(x) for x in c) for i in list: try: b = url2 +'/'+ i r = requests.get(url = b ,headers = headers) m = r.status_code if m==200: r.encoding = r.apparent_encoding HtmlText = r.text if 'logs' in HtmlText: with open (r'git.txt','a', encoding ='utf-8' ) as f: a = f.write('存在泄露情况'+ ':' + b + ' ') else: with open (r'qita.txt','a', encoding ='utf-8' ) as w: c = w.write('可能存在泄露情况'+ ':' + b + ' ') else: print('不存在'+b) except: print('无法连接') if __name__ == '__main__': p = multiprocessing.Pool(50)#线程数 with open(r'tar.txt','r',encoding = 'utf-8') as f: a = f.readlines() for i in a: p.apply_async(main,(i,)) p.close() p.join()
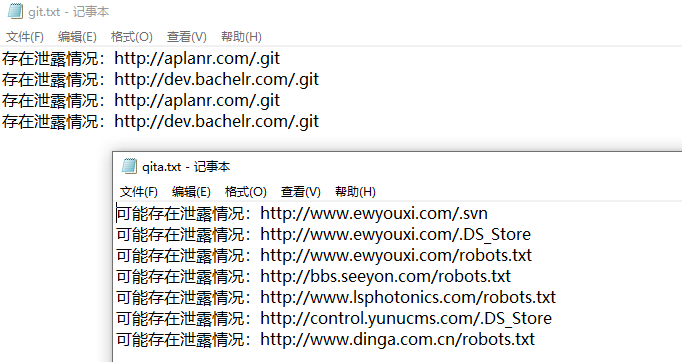
脚本运行:

运行结果:
Python脚本踩坑记录
第一种报错:IndentationError: expected an indented block

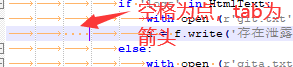
这个错误因为if语句后我没在下一行多搞个tab键位,导致上下级关系不明确。

第二种报错:IndentationError: unindent does not match any outer indentation level

这个错误是因为python脚本对空格和tab键不能共存。需要统一。Notepad++显示出来空格与制表符,改成一样的。
参考文章
python 多进程批量扫描网站备份文件:http://blog.csdn.net/qq_39650046/article/details/110429544
IndentationError: unindent does not match any outer indentation level笔记:http://cnblogs.com/kerrycode/p/11183963.html