题记
这周一直在忙入职的事情,当然学习是不能停止的。前两天学了正则,想用正则爬爬东西,果然好用,我认为html页面用lxml爬取好些,当然正则也行。杂乱无章,例如日志这种我觉得正则好。
lxml可以学习我上一篇文章:http://cnblogs.com/sunny11/p/14745407.html(Python制作ip代理爬取与验证脚本(学会这个你就表格啥的都会爬了))
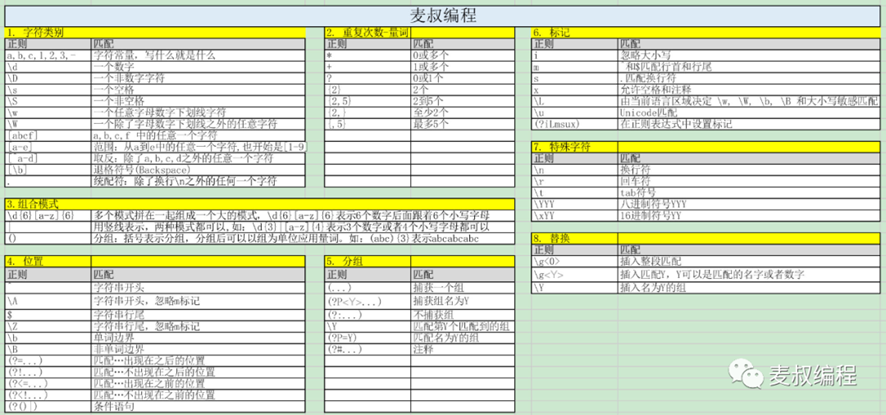
正则学习地址
正则学习视频:http://bilibili.com/video/BV1zK4y1Z75d?p=1
正则学习文档:http://mp.weixin.qq.com/s/CQ1vjRiG5H_aKnci1VFWsg
爬虫思路
我们可以看到下图是典型的thinkphp的日志泄露的内容,我们本次的目标是姓名,手机号,邮箱,学号。
代码正则部分,我们可以看到这种地方前边都有统一的键,例如`username`='xxx',我们可以利用这一点把键值一起爬取下来,然后利用替换把我们不想要的东西替换为空,这样就能得到我们想要的东西了。
name = re.findall(r"`username`='.+?'", text) #匹配姓名
number = re.findall(r"ber` = '[0-9]{3,12}", text) #匹配学号
phone = re.findall(r"phone`='[0-9]+", text) #匹配手机号
email=re.findall(r"`email`='[A-Za-z0-9]+@[a-zA-Z0-9]+.[a-zA-Z0-9]+.[a-z]+", text) #匹配邮箱

代码
# coding=gbk import re def mimi(): id=1 for text in open('target.txt',encoding="utf-8"): name = re.findall(r"`username`='.+?'", text) number = re.findall(r"ber` = '[0-9]{3,12}", text) phone = re.findall(r"phone`='[0-9]+", text) email=re.findall(r"`email`='[A-Za-z0-9]+@[a-zA-Z0-9]+.[a-zA-Z0-9]+.[a-z]+", text) #匹配邮箱 print(email) if name and email and phone: name=name[0] email = email[0] number =number[0] phone =phone[0] name = name.replace("`username`='", '') name = name.replace("'", '') email = email.replace("`email`='", '') email = email.replace("`email`=", '') number = number.replace("ber` = '", '') phone=phone.replace("phone`='", '') ipm="第"+str(id)+"位同学--->"+"姓名:"+name+" "+"学号:"+number+" "+"手机号:"+phone+" "+"邮箱:"+email print(ipm) id=id + 1 with open(r'student2.txt', 'a+', encoding='utf-8') as f: f.write(ipm + ' ') f.close() if (1): mimi()
最后效果
