本篇会讲剩余的java的对象引用与对象的区别、多态性理解、向上转型和向下转型、栈和堆等综合型的知识,亦是非常重要的难点!!!
一、对象引用与对象的区别
为便于说明,我们先定义一个简单的类:
class Vehicle {
int passengers;
int fuelcap;
int mpg;
}
有了这个模板,就可以用它来创建对象:
Vehicle veh1 = new Vehicle();
通常把这条语句的动作称之为创建一个对象,其实,它包含了四个动作。
1)右边的“new Vehicle”,是以Vehicle类为模板,在堆空间里创建一个Vehicle类对象(也简称为Vehicle对象)。
2)末尾的()意味着,在对象创建后,立即调用Vehicle类的构造函数,对刚生成的对象进行初始化。构造函数是肯定有的。如果你没写,Java会给你补上一个默认的构造函数。
3)左边的“Vehicle veh1”创建了一个Vehicle类引用变量。所谓Vehicle类引用,就是以后可以用来指向Vehicle对象的对象引用。
4)“=”操作符使对象引用指向刚创建的那个Vehicle对象。
我们可以把这条语句拆成两部分:
Vehicle veh1;
veh1 = new Vehicle();
效果是一样的。这样写,就比较清楚了,有两个实体:一是对象引用变量,一是对象本身。
在堆空间里创建的实体,与在数据段以及栈空间里创建的实体不同。尽管它们也是确确实实存在的实体,但是,我们看不见,也摸不着。不仅如此,我们仔细研究一下第二句,找找刚创建的对象叫什么名字?有人说,它叫“Vehicle”。不对,“Vehicle”是类(对象的创建模板)的名字。一个Vehicle类可以据此创建出无数个对象,这些对象不可能全叫“Vehicle”。
对象连名都没有,没法直接访问它。我们只能通过对象引用来间接访问对象。
为了形象地说明对象、引用及它们之间的关系,可以做一个或许不很妥当的比喻。对象好比是一只很大的气球,大到我们抓不住它。引用变量是一根绳,可以用来系汽球。
如果只执行了第一条语句,还没执行第二条,此时创建的引用变量veh1还没指向任何一个对象,它的值是null。引用变量可以指向某个对象,或者为null。它是一根绳,一根还没有系上任何一个汽球的绳。执行了第二句后,一只新汽球做出来了,并被系在veh1这根绳上。我们抓住这根绳,就等于抓住了那只汽球。
再来一句:
Vehicle veh2;
就又做了一根绳,还没系上汽球。如果再加一句:
veh2 = veh1;
系上了。这里,发生了复制行为。但是,要说明的是,对象本身并没有被复制,被复制的只是对象引用。结果是,veh2也指向了veh1所指向的对象。两根绳系的是同一只汽球。
如果用下句再创建一个对象:
veh2 = new Vehicle();
则引用变量veh2改指向第二个对象。
从以上叙述再推演下去,我们可以获得以下结论:(1)一个对象引用可以指向0个或1个对象(一根绳子可以不系汽球,也可以系一个汽球);(2)一个对象可以有N个引用指向它(可以有N条绳子系住一个汽球)。
如果再来下面语句:
veh1 = veh2;
按上面的推断,veh1也指向了第二个对象。这个没问题。问题是第一个对象呢?没有一条绳子系住它,它飞了。多数书里说,它被Java的垃圾回收机制回收了。这不确切。正确地说,它已成为垃圾回收机制的处理对象。至于什么时候真正被回收,那要看垃圾回收机制的心情了。
由此看来,下面的语句应该不合法吧?至少是没用的吧?
new Vehicle();
不对。它是合法的,而且可用的。譬如,如果我们仅仅为了打印而生成一个对象,就不需要用引用变量来系住它。最常见的就是打印字符串:
System.out.println(“I am Java!”);
字符串对象“I am Java!”在打印后即被丢弃。有人把这种对象称之为临时对象。
对象与引用的关系将持续到对象回收。但是,关于这一点,打算在下文“简述Java回收机制”再说。
例题:
public interface IA {
void ma();
}
public interface IB extends IA{
void mb();
}
public interface IC {
void mc();
}
public interface ID extends IB, IC{
void md();
}
public class IE implements ID{
public void mb() {
}
public void ma() {
System.out.println("呵呵");
}
public void mc() {
System.out.println("哈哈");
}
public void md() {
}
}
public class TestIE {
public static void main(String args[]){
IC ic = new IE();
new IE().ma(); //调用ma方法只能新建一个IE对象来调用
new IE().mc(); //调用mc方法可以新建一个IE对象来调用,也可以用ic.的方式调用
ic.mc();
}
}
public class TestIE {
public static void main(String args[]){
IC ic = new IE();
System.out.println(ic instanceof IA);
System.out.println(ic instanceof IB);
System.out.println(ic instanceof IC);
System.out.println(ic instanceof ID);
System.out.println(ic instanceof IE);
//五个都是对的,因为instanceof是Java中的二元运算符,左边是对象,右边是类;当对象是右边类或子类所创建对象时,返回true;否则,返回false。
}
}
二、多态性理解
1. Java中的多态性理解(注意与C++区分)
Java中除了static方法和final方法(private方法本质上属于final方法,因为不能被子类访问)之外,其它所有的方法都是动态绑定,这意味着通常情况下,我们不必判定是否应该进行动态绑定—它会自动发生。
- final方法会使编译器生成更有效的代码,这也是为什么说声明为final方法能在一定程度上提高性能(效果不明显)。
- 如果某个方法是静态的,它的行为就不具有多态性:
class StaticSuper {
public static String staticGet() {
return "Base staticGet()";
}
public String dynamicGet() {
return "Base dynamicGet()";
}
}
class StaticSub extends StaticSuper {
public static String staticGet() {
return "Derived staticGet()";
}
public String dynamicGet() {
return "Derived dynamicGet()";
}
}
public class StaticPolymorphism {
public static void main(String[] args) {
StaticSuper sup = new StaticSub();
System.out.println(sup.staticGet());
System.out.println(sup.dynamicGet());
}
}
输出:
Base staticGet()
Derived dynamicGet()
构造函数并不具有多态性,它们实际上是static方法,只不过该static声明是隐式的。因此,构造函数不能够被override。
在父类构造函数内部调用具有多态行为的函数将导致无法预测的结果,因为此时子类对象还没初始化,此时调用子类方法不会得到我们想要的结果。
class Glyph {
void draw() {
System.out.println("Glyph.draw()");
}
Glyph() {
System.out.println("Glyph() before draw()");
draw();
System.out.println("Glyph() after draw()");
}
}
class RoundGlyph extends Glyph {
private int radius = 1;
RoundGlyph(int r) {
radius = r;
System.out.println("RoundGlyph.RoundGlyph(). radius = " + radius);
}
void draw() {
System.out.println("RoundGlyph.draw(). radius = " + radius);
}
}
public class PolyConstructors {
public static void main(String[] args) {
new RoundGlyph(5);
}
}
输出:
Glyph() before draw()
RoundGlyph.draw(). radius = 0
Glyph() after draw()
RoundGlyph.RoundGlyph(). radius = 5
为什么会这样输出?这就要明确掌握Java中构造函数的调用顺序:
(1)在其他任何事物发生之前,将分配给对象的存储空间初始化成二进制0;(2)调用基类构造函数。从根开始递归下去,因为多态性此时调用子类覆盖后的draw()方法(要在调用RoundGlyph构造函数之前调用),由于步骤1的缘故,我们此时会发现radius的值为0;(3)按声明顺序调用成员的初始化方法;(4)最后调用子类的构造函数。
只有非private方法才可以被覆盖,但是还需要密切注意覆盖private方法的现象,这时虽然编译器不会报错,但是也不会按照我们所期望的来执行,即覆盖private方法对子类来说是一个新的方法而非重载方法。因此,在子类中,新方法名最好不要与基类的private方法采取同一名字(虽然没关系,但容易误解,以为能够覆盖基类的private方法)。
Java类中属性域的访问操作都由编译器解析,因此不是多态的。父类和子类的同名属性都会分配不同的存储空间,如下:
// Direct field access is determined at compile time.
class Super {
public int field = 0;
public int getField() {
return field;
}
}
class Sub extends Super {
public int field = 1;
public int getField() {
return field;
}
public int getSuperField() {
return super.field;
}
}
public class FieldAccess {
public static void main(String[] args) {
Super sup = new Sub();
System.out.println("sup.filed = " + sup.field +
", sup.getField() = " + sup.getField());
Sub sub = new Sub();
System.out.println("sub.filed = " + sub.field +
", sub.getField() = " + sub.getField() +
", sub.getSuperField() = " + sub.getSuperField());
}
}
输出:
sup.filed = 0, sup.getField() = 1
sub.filed = 1, sub.getField() = 1,
sub.getSuperField() = 0
Sub子类实际上包含了两个称为field的域,然而在引用Sub中的field时所产生的默认域并非Super版本的field域,因此为了得到Super.field,必须显式地指明super.field。
三、向上转型和向下转型
在我的理解:java的向上和向下转型可以看成是类型的转换。
public class Person {
public void eat(){
System.out.println("Person eatting...");
}
public void sleep() {
System.out.println("Person sleep...");
}
}
public class Superman extends Person{
public void eat() {
System.out.println("Superman eatting...");
}
public void fly() {
System.out.println("Superman fly...");
}
}
测试向上转型的主方法:
public class Main {
public static void main(String[] args) {
Person person = new Superman();
person.sleep(); //调用的是父类person的方法
person.eat(); // 调用的是Superman里面的eat方法,Superman重写了Person父类的方法
//person.fly(); //报错了,丢失了Superman类的fly方法
}
}
运行的结果:Person sleep…Superman eatting…
分析:当在执行Person person = new Superman()时,我们来看看它的内存存储:
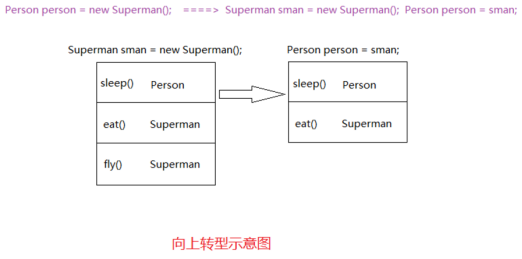
从此图我们可以看出 向上转型会丢失子类的新增方法,同时会保留子类重写的方法。
测试向下转型的主方法:
public class Main {
public static void main(String[] args) {
Person person = new Superman();
Superman s = (Superman)person; //向下转型
s.sleep();
s.fly();
s.eat();
}
}
运行的结果:Person sleep…Superman fly…Superman eatting…
分析:当在执行Superman s = (Superman)person;时,我们来看看他们的内存存储:
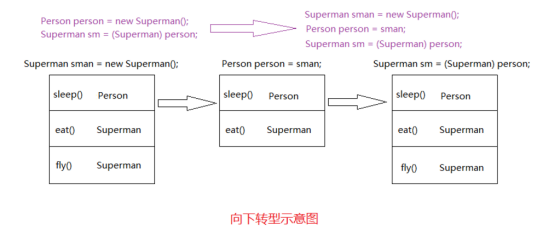
在这里我们看出 向下转型可以得到子类的所有方法(包含父类的方法)。
四、栈和堆
JAVA在程序运行时,在内存中划分5片空间进行数据的存储。分别是:1:寄存器。2:本地方法区。3:方法区。4:栈。5:堆。
基本,栈stack和堆heap这两个概念很重要,不了解清楚,后面就不用学了。
以下是这几天栈和堆的学习记录和心得。得些记录下来。以后有学到新的,会慢慢补充。
一、先说一下最基本的要点
基本数据类型、局部变量都是存放在栈内存中的,用完就消失。new创建的实例化对象及数组,是存放在堆内存中的,用完之后靠垃圾回收机制不定期自动消除。
二、先明确以上两点,以下示例就比较好理解了
示例1
main() int x=1;show () int x=2
主函数main()中定义变量int x=1,show()函数中定义变量int x=1。最后show()函数执行完毕。
以上程序执行步骤:
第1步——main()函数是程序入口,JVM先执行,在栈内存中开辟一个空间,存放int类型变量x,同时附值1。第2步——JVM执行show()函数,在栈内存中又开辟一个新的空间,存放int类型变量x,同时附值2。 此时main空间与show空间并存,同时运行,互不影响。第3步——show()执行完毕,变量x立即释放,空间消失。但是main()函数空间仍存在,main中的变量x仍然存在,不受影响。
示例2
main() int[] x=new int[3]; x[0]=20
主函数main()中定义数组x,元素类型int,元素个数3。
以上程序执行步骤第1步——执行int[] x=new int[3]; 隐藏以下几分支 JVM执行main()函数,在栈内存中开辟一个空间,存放x变量(x变量是局部变量)。 同时,在堆内存中也开辟一个空间,存放new int[3]数组,堆内存会自动内存首地址值,如0x0045。 数组在栈内存中的地址值,会附给x,这样x也有地址值。所以,x就指向(引用)了这个数组。此时,所有元素均未附值,但都有默认初始化值0。
第2步——执行x[0]=20 即在堆内存中将20附给[0]这个数组元素。这样,数组的三个元素值分别为20,0,0
示例3main() int[] x=new int[3]; x[0]=20 x=null;
以上步骤执行步骤第1、2步——与示例2完全一样,略。
第3步——执行x=null; null表示空值,即x的引用数组内存地址0x0045被删除了,则不再指向栈内存中的数组。此时,堆中的数组不再被x使用了,即被视为垃圾,JVM会启动垃圾回收机制,不定时自动删除。
示例4main() int[] x=new int[3]; int[] y=x; y[1]=100 x=null;
以上步骤执行步骤
第1步——与示例2第1步一致,略。第2步——执行int[] y=x, 在栈内存定义了新的数组变量内存y,同时将x的值0x0045附给了y。所以,y也指向了堆内存中的同一个数组。第3步——执行y[1]=100 即在堆内存中将20附给[0]这个数组元素。这样,数组的三个元素值分别为0,100,0第4步——执行x=null 则变量x不再指向栈内存中的数组了。但是,变量y仍然指向,所以数组不消失。
示例5
Car c=new Car;c.color="blue";Car c1=new Car;c1.num=5;
虽然是个对象都引用new Car,但是是两个不同的对象。每一次new,都产生不同的实体
示例6
Car c=new Car;c.num=5;Car c1=c;c1.color="green";c.run();
Car c1=c,这句话相当于将对象复制一份出来,两个对象的内存地址值一样。所以指向同一个实体,对c1的属性修改,相当于c的属性也改了。
三、栈和堆的特点
栈:
函数中定义的基本类型变量,对象的引用变量都在函数的栈内存中分配。栈内存特点,数数据一执行完毕,变量会立即释放,节约内存空间。栈内存中的数据,没有默认初始化值,需要手动设置。
堆:
堆内存用来存放new创建的对象和数组。堆内存中所有的实体都有内存地址值。堆内存中的实体是用来封装数据的,这些数据都有默认初始化值。堆内存中的实体不再被指向时,JVM启动垃圾回收机制,自动清除,这也是JAVA优于C++的表现之一(C++中需要程序员手动清除)。
注:
什么是局部变量:定义在函数中的变量、定义在函数中的参数上的变量、定义在for循环内部的变量
好啦。到目前为止,关于java的面向对象部分,基本写完啦,帮助到你们的话,可以点赞关注收藏一波O(∩_∩)O~!!!
喜欢前端、后端java开发的可以加+qun:609565759,有详细视频、资料、教程,文档,值得拥有!!!希望可以一起努力,加油ヾ(◍°∇°◍)ノ゙!!!