Oracle中的体系结构:
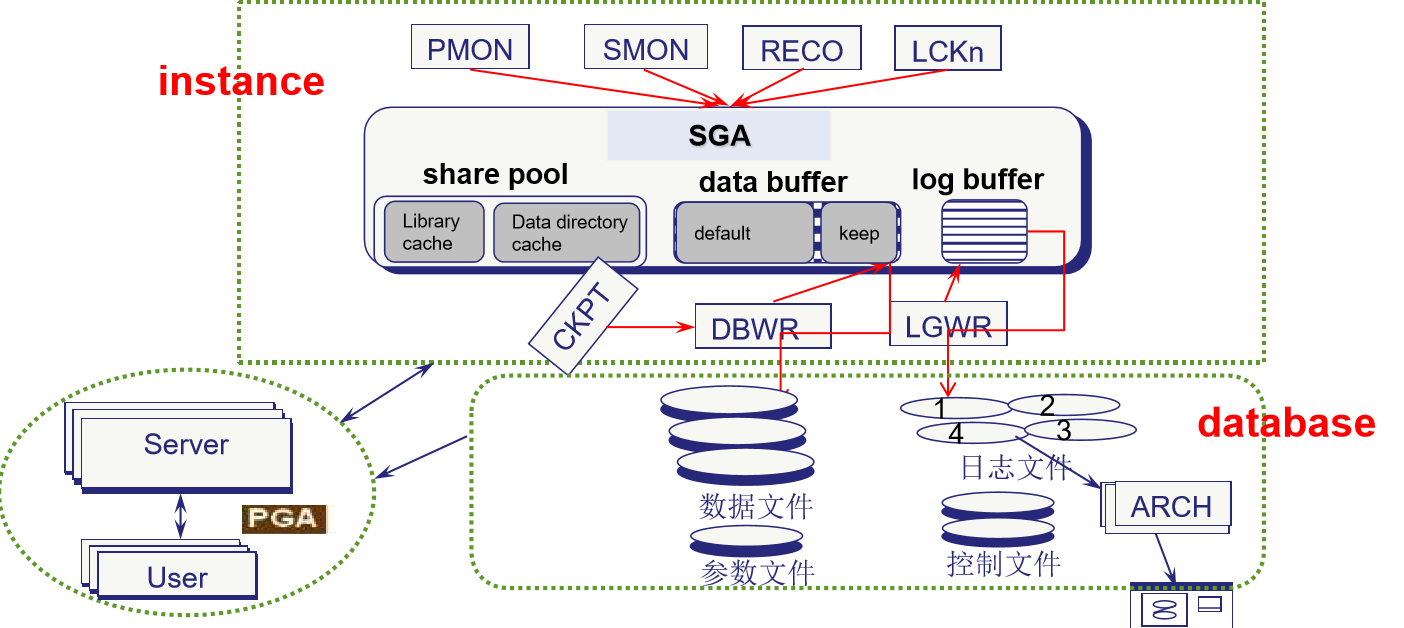

oracle体系结构中的进程:

共享池相关的优化:
drop table t purge; create table t as select * from dba_objects; set linesize 1000 set autotrace on set timing on --第1次执行 select count(*) from t; --第2次执行 --该命令只是为了先不考虑解析的优化,单纯考虑第2次执行物理读减少带来的优化效应 alter system flush shared_pool; select count(*) from t;

绑定变量带来的性能飞跃:

begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values (:x)' using i;
end loop;
commit;
end;
/
select t.sql_text, t.sql_id, t.executions, t.parse_calls
from v$sql t
where sql_text like 'insert into t values%';
select t.sql_text, t.sql_id, t.executions, t.parse_calls
from v$sql t
where sql_text like 'insert into t values (:x)%';
SQL>--未使用绑定变量
SQL> begin
2 for i in 1 .. 100000
3 loop
4 execute immediate
5 'insert into t values ( '||i||')';
6 end loop;
7 commit;
8 end;
9 /
PL/SQL 过程已成功完成。
已用时间: 00: 00: 43.50
SQL>--使用绑定变量
SQL> begin
2 for i in 1 .. 100000
3 loop
4 execute immediate
5 'insert into t values ( :x )' using i;
6 end loop;
7 commit;
8 end;
9 /
PL/SQL 过程已成功完成。
已用时间: 00: 00: 04.77
硬解析次数和执行次数:

实验1
drop table t purge;
create table t ( x int );
alter system flush shared_pool;
exec dbms_workload_repository.create_snapshot();
set timing on
begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values ( '||i||')';
end loop;
commit;
end;
/
exec dbms_workload_repository.create_snapshot();
@?/rdbms/admin/awrrpt.sql
实验2
drop table t purge;
create table t ( x int );
alter system flush shared_pool;
exec dbms_workload_repository.create_snapshot();
set timing on
begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values ( :x )' using i;
end loop;
commit;
end;
/
exec dbms_workload_repository.create_snapshot();
@?/rdbms/admin/awrrpt.sql
执行语句:
drop table t purge;
create table t ( x int );
set linesize 266
set pagesize 5000
alter system flush shared_pool;
alter system flush buffer_cache;
alter session set events '10046 trace name context forever,level 12';
begin
for i in 1 .. 10000
loop
execute immediate
'insert into t values ( '||i||')';
end loop;
commit;
end;
alter session set events '10046 trace name context off';
--通过如下命令可以查出生成的trc文件
select d.value
|| '/'
|| LOWER (RTRIM(i.INSTANCE, CHR(0)))
|| '_ora_'
|| p.spid
|| '.trc' trace_file_name
from (select p.spid
from v$mystat m,v$session s, v$process p
where m.statistic#=1 and s.sid=m.sid and p.addr=s.paddr) p,
(select t.INSTANCE
FROM v$thread t,v$parameter v
WHERE v.name='thread'
AND(v.VALUE=0 OR t.thread#=to_number(v.value))) i,
(select value
from v$parameter
where name='user_dump_dest') d;
exit
生成报表:
tkprof d:oraclediag dbms est11g est11g race/test11g_ora_4516.trc d:10046_no_bind.txt sys=no sort=prsela,exeela,fchela
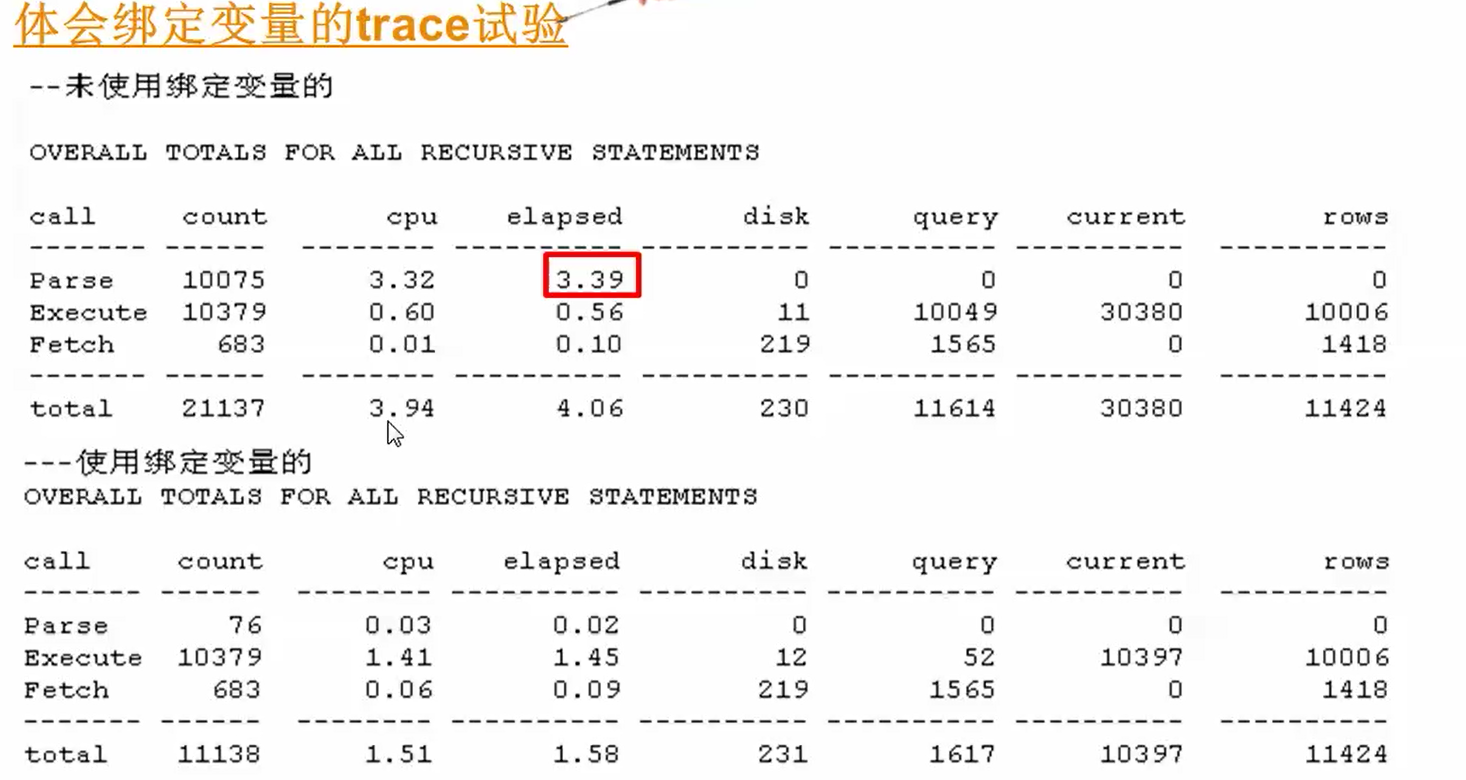
--查询10046.txt,发现总共是花费4.38秒,其中解析时间占用了3.3秒
---用10046来跟踪另外一个使用绑定变量的写法,如下:
drop table t purge;
create table t ( x int );
set linesize 266
set pagesize 5000
alter system flush shared_pool;
alter system flush buffer_cache;
alter session set events '10046 trace name context forever,level 12';
begin
for i in 1 .. 10000
loop
execute immediate
'insert into t values ( :x )' using i;
end loop;
commit;
end;
/
alter session set events '10046 trace name context off';
select d.value
|| '/'
|| LOWER (RTRIM(i.INSTANCE, CHR(0)))
|| '_ora_'
|| p.spid
|| '.trc' trace_file_name
from (select p.spid
from v$mystat m,v$session s, v$process p
where m.statistic#=1 and s.sid=m.sid and p.addr=s.paddr) p,
(select t.INSTANCE
FROM v$thread t,v$parameter v
WHERE v.name='thread'
AND(v.VALUE=0 OR t.thread#=to_number(v.value))) i,
(select value
from v$parameter
where name='user_dump_dest') d;
tkprof d:oraclediag
dbms est11g est11g race/test11g_ora_2908.trc d:10046_bind.txt sys=no sort=prsela,exeela,fchela
--查询10046.txt,发现总共是花费2.75秒,其中解析时间占用了0.03秒
静态sql自动绑定变量:
drop table t purge;
create table t(x int);
alter system flush shared_pool;
select * from v$mystat where rownum=1;
set timing on
begin
for i in 1 .. 100000
loop
insert into t values (i);
end loop;
commit;
end;
/
select t.sql_text, t.sql_id, t.executions, t.parse_calls
from v$sql t
where lower(sql_text) like 'insert into t values%';
参数对Sql性能的影响:

drop table t purge;
create table t ( x int );
set timing on
alter session set session_cached_cursors=0;
--使用绑定变量
begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values ( :x )' using i;
end loop;
commit;
end;
/
drop table t purge;
create table t ( x int );
set timing on
alter session set session_cached_cursors=50;
--使用绑定变量
begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values ( :x )' using i;
end loop;
commit;
end;
/
说明:
oracle有一个概念,那就是session cursor cache,中文描述就是有一块内存区域,用来存储关闭了的cursor。
当一个cursor关闭之后,oracle会检查这个cursor的request次数是否超过3次,如果超过了三次,就会放入session cursor cache。
这样在下次parse的时候,就可以从session cursor cache中找到这个statement, session cursor cache的管理也是使用LRU。
session_cached_cursors这个参数是控制session cursor cache的大小的。
session_cached_cursors定义了session cursor cache中存储的cursor的个数。这个值越大,则会消耗的内存越多。
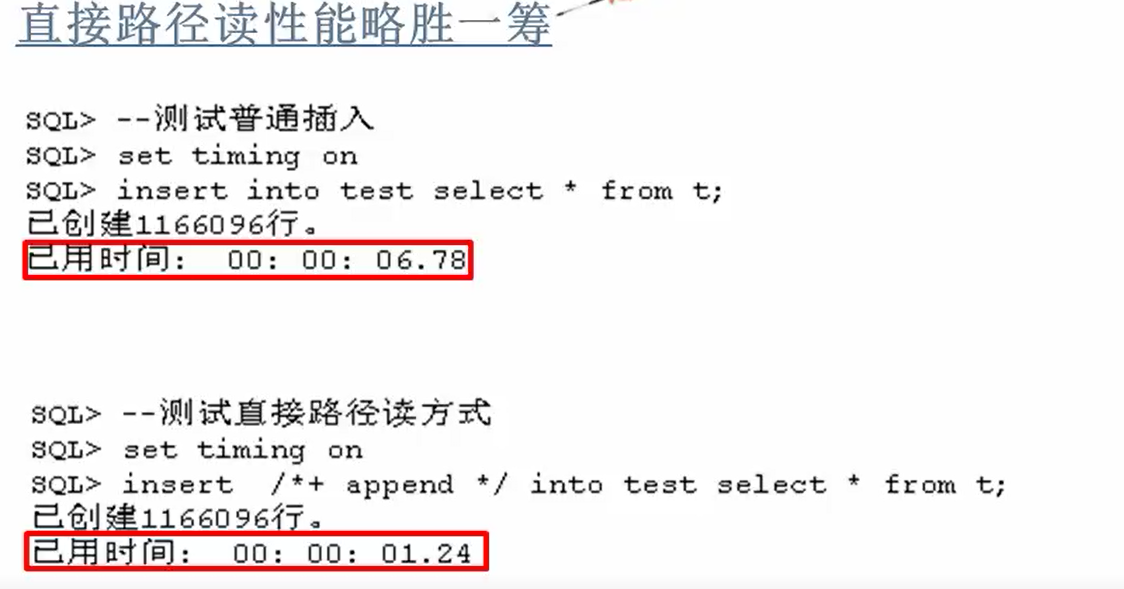
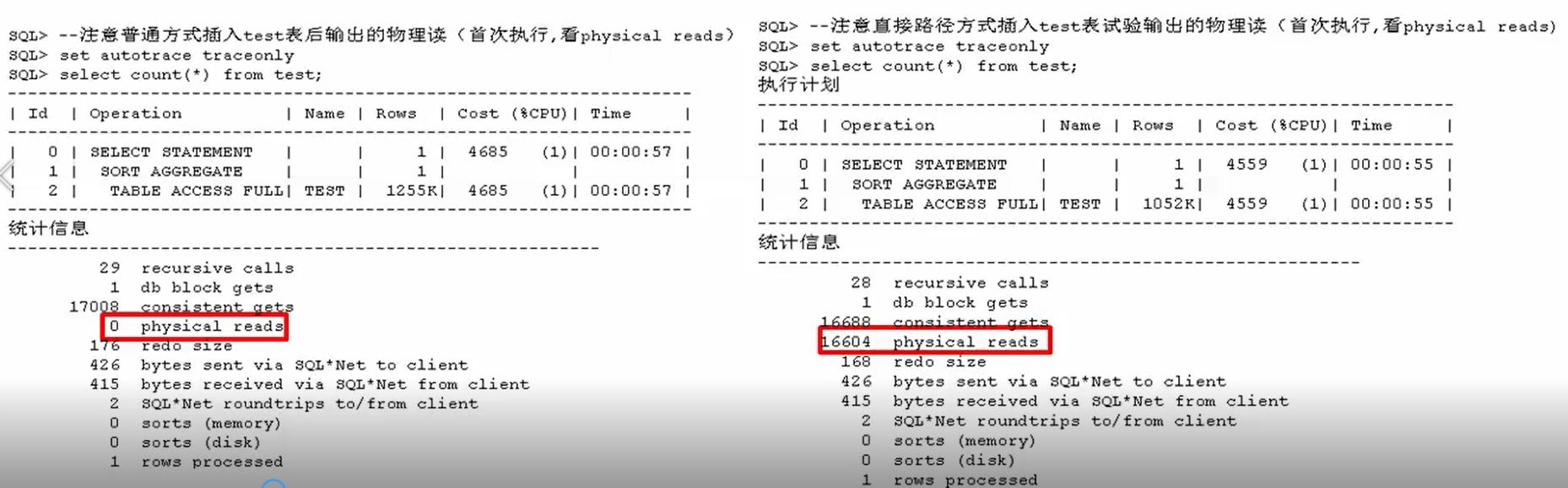
drop table t purge; create table t as select * from dba_objects; insert into t select * from t; insert into t select * from t; insert into t select * from t; insert into t select * from t; commit; --测试普通插入 drop table test; create table test as select * from dba_objects where 1=2; set timing on insert into test select * from t; commit; --注意这个普通方式插入试验输出的物理读(首次读) set autotrace traceonly select count(*) from test; --测试直接路径读方式 drop table test; create table test as select * from dba_objects where 1=2; set timing on insert /*+ append */ into test select * from t; commit; --注意这个直接路径方式插入试验输出的物理读(首次读) set autotrace traceonly select count(*) from test;
批量提交与否性能差异:

set serveroutput on size 100000
drop table t purge;
create table t(x int);
set timing on
begin
for i in 1 .. 100000 loop
insert into t1 values (i);
commit;
end loop;
end;
/
drop table t purge;
create table t(x int);
begin
for i in 1 .. 100000 loop
insert into t values (i);
end loop;
commit;
end;
/
日志关闭与否对性能的影响:

--环境准备(构造一个记录有400万左右的表) drop table t purge; create table t as select * from dba_objects; insert into t select * from t; insert into t select * from t; insert into t select * from t; insert into t select * from t; --多插几次,让数据大一点 insert into t select * from t; insert into t select * from t; commit; --测试直接路径读方式 drop table test; create table test as select * from dba_objects where 1=2; set timing on insert /*+ append */ into test select * from t; commit; --测试nolgging关闭日志+直接路径读方式 drop table test; create table test as select * from dba_objects where 1=2; alter table test nologging; set timing on insert /*+ append */ into test select * from t; commit;