count(*)和Count(列)
drop table t purge; create table t as select * from dba_objects; --alter table T modify object_id null; update t set object_id =rownum ; set timing on set linesize 1000 set autotrace on
select count(*) from t;

select count(object_id) from t;

逻辑读和Cost是一样的。、
建索引:
create index idx_object_id on t(object_id);
select count(*) from t; 和以前一样。
select count(object_id) from t;

把列指定为非空。
alter table T modify object_id not null;
select count(*) from t;
select count(object_id) from t;

看来count(列)和count(*)其实一样快,如果索引列是非空的,count(*)可用到索引,此时一样快,有索引,列不允许为空,性能一样快。
验证脚本1 (先构造出表和数据)
SET SERVEROUTPUT ON
SET ECHO ON
---构造出有25个字段的表T
DROP TABLE t;
DECLARE
l_sql VARCHAR2(32767);
BEGIN
l_sql := 'CREATE TABLE t (';
FOR i IN 1..25
LOOP
l_sql := l_sql || 'n' || i || ' NUMBER,';
END LOOP;
l_sql := l_sql || 'pad VARCHAR2(1000)) PCTFREE 10';
EXECUTE IMMEDIATE l_sql;
END;
/
----将记录还有这个表T中填充
DECLARE
l_sql VARCHAR2(32767);
BEGIN
l_sql := 'INSERT INTO t SELECT ';
FOR i IN 1..25
LOOP
l_sql := l_sql || '0,';
END LOOP;
l_sql := l_sql || 'NULL FROM dual CONNECT BY level <= 10000';
EXECUTE IMMEDIATE l_sql;
COMMIT;
END;
/
--以下动作观察执行速度,比较发现COUNT(*)最快,COUNT(最大列)最慢
DECLARE
l_dummy PLS_INTEGER;
l_start PLS_INTEGER;
l_stop PLS_INTEGER;
l_sql VARCHAR2(100);
BEGIN
l_start := dbms_utility.get_time;
FOR j IN 1..1000
LOOP
EXECUTE IMMEDIATE 'SELECT count(*) FROM t' INTO l_dummy;
END LOOP;
l_stop := dbms_utility.get_time;
dbms_output.put_line((l_stop-l_start)/100);
FOR i IN 1..25
LOOP
l_sql := 'SELECT count(n' || i || ') FROM t';
l_start := dbms_utility.get_time;
FOR j IN 1..1000
LOOP
EXECUTE IMMEDIATE l_sql INTO l_dummy;
END LOOP;
l_stop := dbms_utility.get_time;
dbms_output.put_line((l_stop-l_start)/100);
END LOOP;
END;
/
-结论:
--原来优化器是这么搞的:列的偏移量决定性能,列越靠后,访问的开销越大。由于count(*)的算法与列偏移量无关,所以count(*)最快。

表的连接顺序:
drop table tab_big; drop table tab_small; create table tab_big as select * from dba_objects where rownum<=30000; create table tab_small as select * from dba_objects where rownum<=10; set autotrace traceonly set linesize 1000 set timing on select count(*) from tab_big,tab_small ; select count(*) from tab_small,tab_big ;
以上实验发现性能是一样的。
*+rule*回到规则的时代
select /*+rule*/ count(*) from tab_big,tab_small ; select /*+rule*/ count(*) from tab_small,tab_big ;
上一条性能好于下一条
结论:原来表连接顺序的说法早就过时了,那是基于规则的时代,现在我们是基于代价的。
与表顺序条件有关:
drop table t1 purge;
drop table t2 purge;
create table t1 as select * from dba_objects;
create table t2 as select rownum id ,dbms_random.string('b', 50) n ,data_object_id data_id from dba_objects where rownum<=10000;
set autotrace traceonly
set linesize 1000
set timing on
select /*+rule*/ * from t1,t2 where t1.object_id=29 and t2.data_id>8;
select /*+rule*/ * from t1,t2 where t2.data_id>8 and t1.object_id=29 ;
加个关联条件看看,看看
select /*+rule*/ * from t1,t2 where t1.object_id=t2.id and t1.object_id=29 and t2.data_id>8;
select /*+rule*/ * from t1,t2 where t1.object_id=t2.id and t2.data_id>8 and t1.object_id=29 ;
in与exists(10g)
select * from v$version; drop table emp purge; drop table dept purge; create table emp as select * from scott.emp; create table dept as select * from scott.dept; set timing on set linesize 1000 set autotrace traceonly select * from dept where deptno NOT IN ( select deptno from emp ) ; select * from dept where not exists ( select deptno from emp where emp.deptno=dept.deptno) ; select * from dept where deptno NOT IN ( select deptno from emp where deptno is not null) and deptno is not null; --结论:10g与空值有关,如果确保非空,可以用到anti的半连接算法
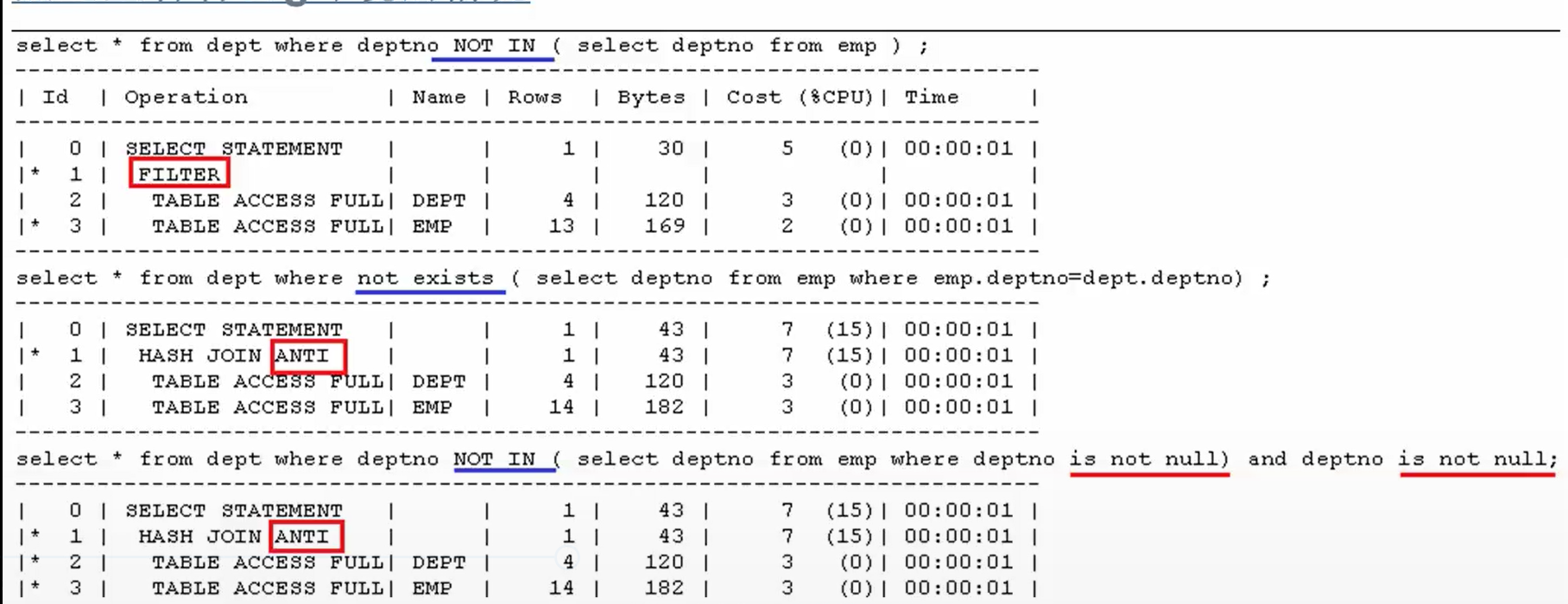
11g:
select * from v$version; drop table emp purge; drop table dept purge; create table emp as select * from scott.emp; create table dept as select * from scott.dept; set timing on set linesize 1000 set autotrace traceonly explain select * from dept where deptno NOT IN ( select deptno from emp ) ; select * from dept where not exists ( select deptno from emp where emp.deptno=dept.deptno) ; select * from dept where deptno NOT IN ( select deptno from emp where deptno is not null) and deptno is not null; --结论:11g与空值有关,都可以用到anti的半连接算法,执行计划一样,性能一样

全局临时表的特性:
--构造基于SESSION的全局临时表(退出session该表记录就会自动清空)
drop table ljb_tmp_session; create global temporary table ljb_tmp_session on commit preserve rows as select * from dba_objects where 1=2; select table_name,temporary,duration from user_tables where table_name='LJB_TMP_SESSION';
--构造基于事务的全局临时表(commit提交后,不等退出session,在该表记录就会自动清空)
drop table ljb_tmp_transaction; create global temporary table ljb_tmp_transaction on commit delete rows as select * from dba_objects where 1=2; select table_name, temporary, DURATION from user_tables where table_name='LJB_TMP_TRANSACTION';
插入语句:
insert all into ljb_tmp_transaction into ljb_tmp_session select * from dba_objects;
统计表的记录
select session_cnt,transaction_cnt from (select count(*) session_cnt from ljb_tmp_session), (select count(*) transaction_cnt from ljb_tmp_transaction);
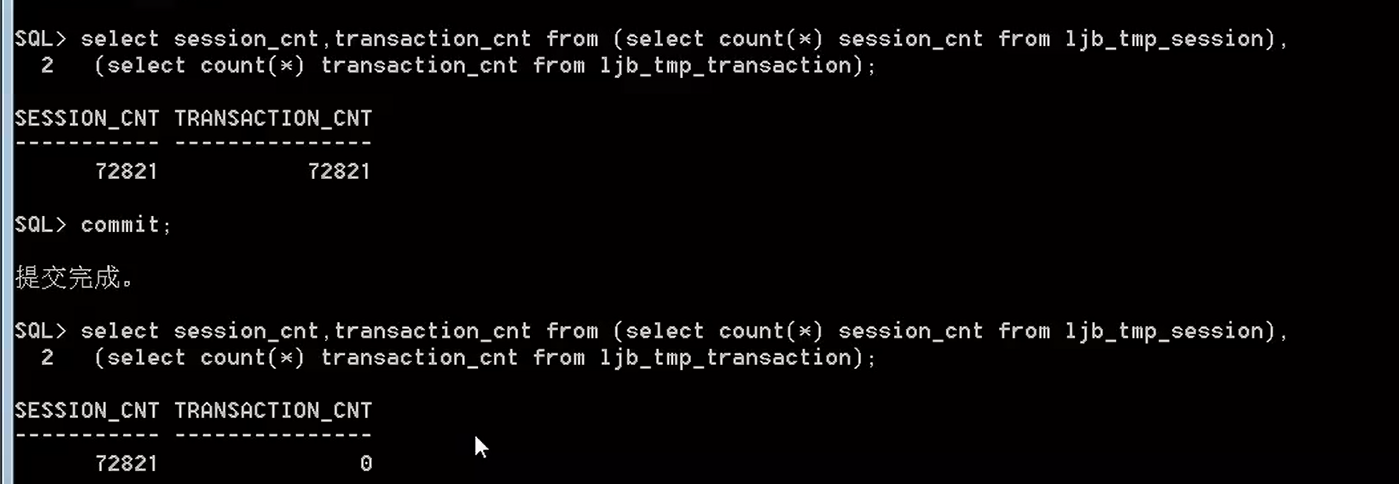
退出来,在进去,就全没有了。