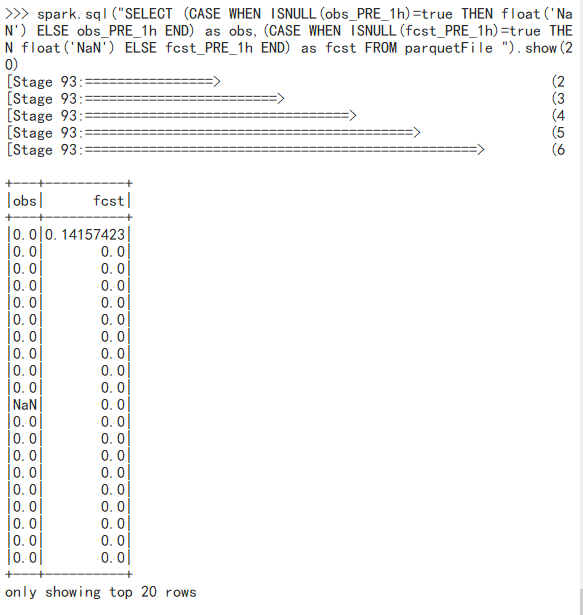
由于我要叠加rdd某列的数据,如果加数中出现nan,结果也需要是nan,nan可以做到,但我要处理的数据源中的nan是以null的形式出现的,null不能叠加,而且我也不能删掉含null的行,于是我用了sparksql 的 ISNULL和CASE WHEN方法:
Case When 方法:
如果obs_PRE_1h列有值则不变,没有则变为nan,注意这里的nan需要写成 float(‘NaN’)
SELECT (CASE WHEN ISNULL(obs_PRE_1h)=true THEN float('NaN') ELSE obs_PRE_1h END) as obs,(CASE WHEN ISNULL(fcst_PRE_1h)=true THEN float('NaN') ELSE fcst_PRE_1h END) as fcst FROM parquetFile
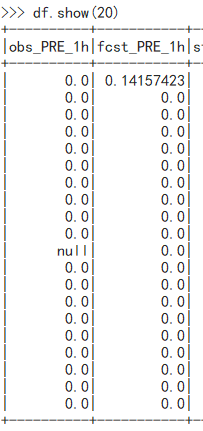
源dataframe是这样的:
结果: