Date: 2019-07-07
Author: Sun
1 定义
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者历史片(历史记录)打包等等
官方网站:http://scrapy.org
2 安装
scrapy框架的安装依赖于异步网络库twisted,安装过程很简单。
进入到python虚拟环境下:
pip install Scrapy
安装过程中可能存在如下问题?
building 'twisted.test.raiser' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
解决方案
进入下载页面:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载twisted对应版本的whl文件(如我的Twisted-17.5.0-cp36-cp36m-win_amd64.whl),cp后面是python版本,amd64代表64位,运行命令:
pip install C:\Users\CR\Downloads\Twisted-17.5.0-cp36-cp36m-win_amd64.whl
在此安装scrapy
python -m pip install --upgrade pip -i https://pypi.douban.com/simple
pip3 install Twisted-17.5.0-cp36-cp36m-win_amd64.whl -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip3 install pywin32 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip3 install scrapy -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
说明:
如果发现哪个库安装失败,则通过wget下载https://pypi.org/simple/中相应版本的库,并安装,最后安装就可以成功
3 Scrapy工作原理
Scrapy框架主要由六大组件组成,它们分别是调试器(Scheduler)、下载器(Downloader)、爬虫(Spider)、中间件(Middleware)、实体管道(Item Pipeline)和Scrapy引擎(Scrapy Engine)
3.1 组件图
下面的图表显示了Scrapy架构组件。
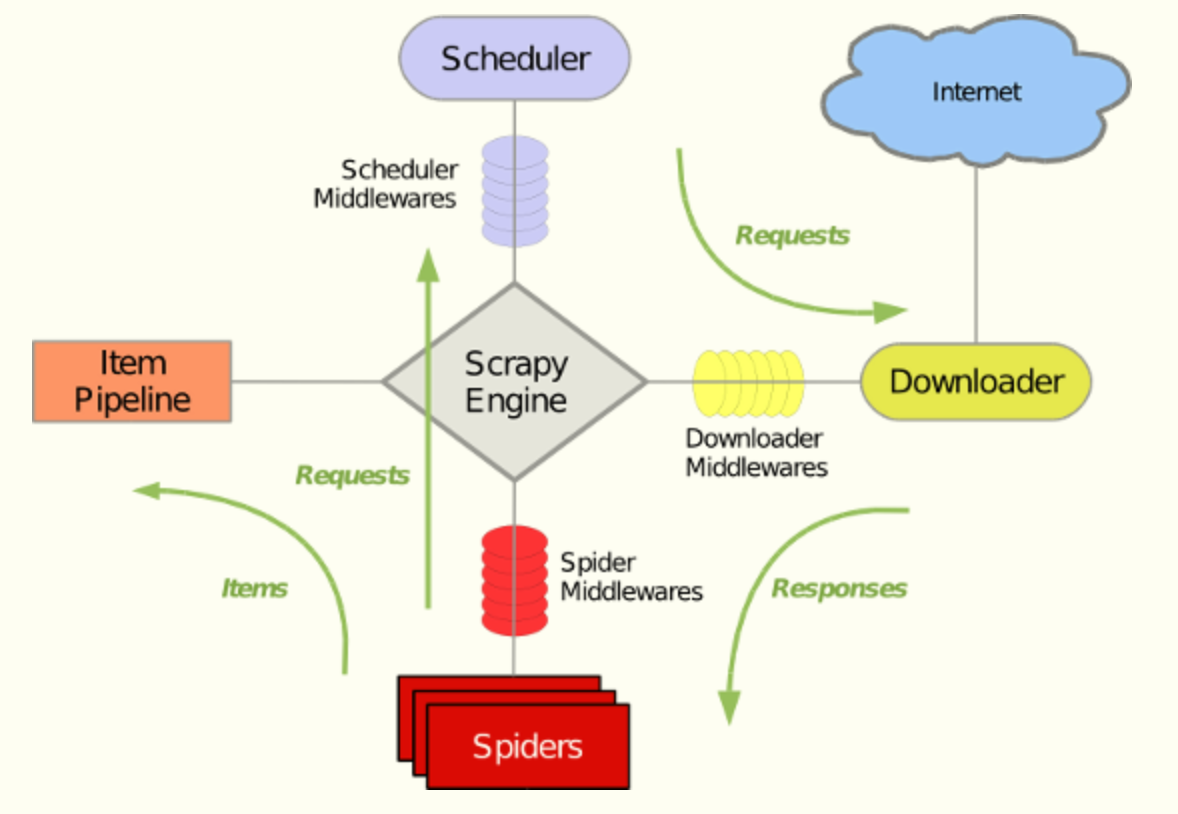
scrapy基本组件图
组件说明:
(1)Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。
(2)调度器(Scheduler)
调度器从引擎接受request对象,并将他们入队列,以便之后引擎请求他们时提供给引擎。
(3)下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spiders。
(4)Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
(5)Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline。
(6)下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response(也包括引擎传递给下载器的Request)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
一句话总结就是:处理下载请求部分
(7)Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
3.2. scrapy数据流图
数据流程图如下:
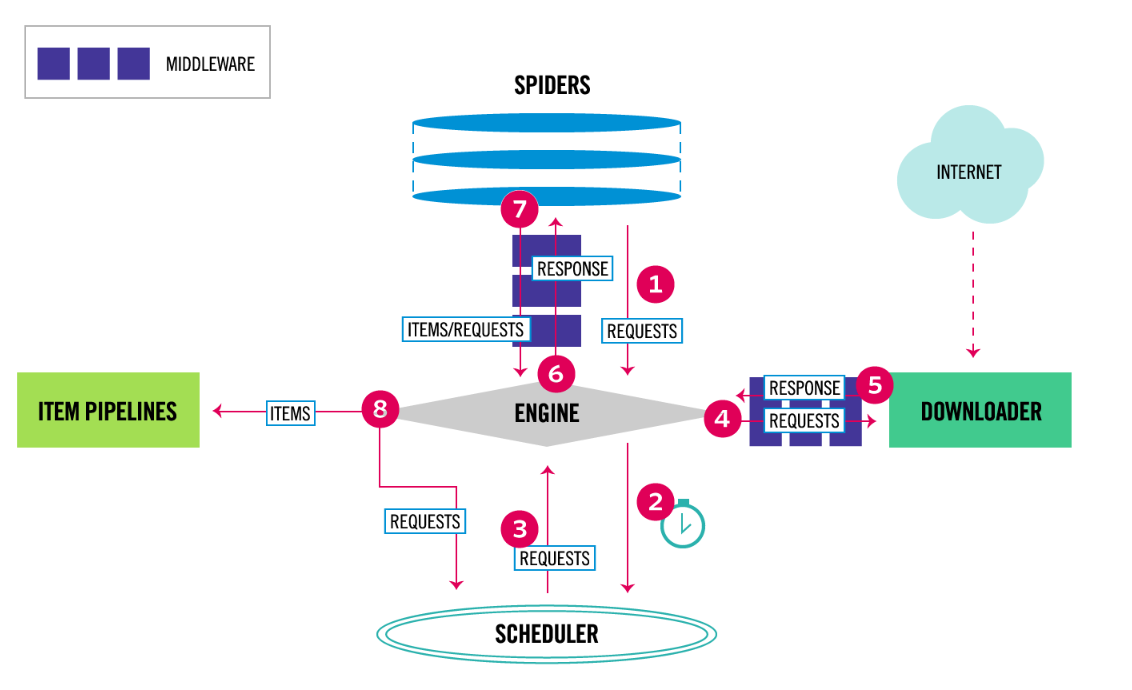
scrapy数据流图
Scrapy数据流图是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎获得初始请求开始抓取。
2、爬虫引擎开始请求调度程序,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎。
6、引擎将下载器的响应通过中间件返回给爬虫进行处理。
7、爬虫处理响应,并通过中间件返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
4. Scrapy 请求响应内部组件
4.1. 请求和响应(Request, Response)
Scrapy的Request和Response对象用于爬取web网站。
一般来说,Request对象在
spider中被生成并且最终传递到下载器(Downloader),下载器对其进行处理并返回一个Response对象,Response对象还会返回到生成request的spider中。
4.2. Request对象
一个Request对象代表一个HTTP请求,一般来讲,HTTP请求是由Spider产生并被Downloader处理进而生成一个Response。
4.2.1 构造方法:
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback, flags])
一个Request对象表示一个HTTP 请求,它通常在Spider中生成并由Downloader执行,从而生成一个。
参数:
url(string):请求的url
callback(callable):处理响应数据的回调方法,用来解析响应数据,如果没有指定,则spider的parse方法。如果在处理期间引发异常,则会调用errback。
method(string):HTTP的请求方法。默认GET。
meta(dict):Request.meta属性的初始值。一旦此参数被设置,通过参数传递的字典将会被浅拷贝。
body:请求体。
headers(dict):请求头。
cookies(dict):cookie
encoding(string):编码方式,默认utf-8。
priority(int):优先级,调度程序使用优先级来定义用于处理请求的顺序。具有较高优先级值的请求将会提前执行。默认0。
dont_filter(boolean):请求不应该被调度器过滤。False表示过滤,True表示不过滤。默认False。
errback(callable):如果在处理请求时引发异常,将会调用该函数。 这包括404 HTTP错误等失败的页面。
4.2.2. Request.meta
Request.meta在不同的请求之间传递数据使用的
Request.meta属性可以包含任意的数据,但是Scrapy和它的内置扩展可以识别一些特殊的键。
dont_redirect:不重定向
dont_retry:不重试
handle_httpstatus_list
dont_merge_cookies:不合并cookie
cookiejar:使用cookiejar
redirect_urls:重定向连接
bindaddress:绑定ip地址
dont_obey_robotstxt:不遵循反爬虫协议
download_timeout:下载超时
4.2.3. Request的子类FormRequest
FormRequest是Request的子类,一般用作表单数据提交。
FormRequest的构造:
class scrapy.http.FormRequest(url[,formdata,...])
FormRequest类除了有Request的功能
还提供一个form_response()方法:
form_response(response[,formname=None,formnumber=0,formdata=None,formxpath=None,clickdata=None,dont_click=False,...])
response:是指包含HTML表单的Response对象,该表单将用于预填充表单字段。
formname:如果给定,将使用设置为该值的name属性的表单。
formnumber:当响应包含多个表单时,要使用的表单的数量。 formnumber默认是0,表示使用第一个。
formdata:字段来覆盖表单数据。如果一个字段已经存在于响应<form>元素中,那么它的值被在这个参数中传递的值覆盖。
formxpath:如果给定,将使用与XPath匹配的第一个表单。
clickdata:查找单击控件的属性。如果没有给出,表单数据将被提交模拟点击第一个可点击的元素。
dont_click:如果为True,表单数据将被提交而不需要单击任何元素。
4.3. Response对象
HTTP请求返回的响应对象,它通常被下载(由Downloader)下载并被传送给Spider进行处理。
4.3.1. 构造函数
class scrapy.http.Response(url[,status=200,headers,body,flags])
url:响应对象response的url
headers:响应对象的响应报头
status:响应的状态码,默认200。
body:响应体
meta:为response.meta属性的初始值。如果给定的,字典将浅复制。
flags:是一个列表包含的response.flags初始值的属性。如果给定,列表将被浅拷贝。
TextResponse
class scrapy.http.TextResponse(url[,encoding[,...]])
TextResponse对象增加了编码能力的基础响应类,是指将只用于二进制数据,如图像、声音或任何媒体文件。
4.3.2 发送FormRequest表单请求
FormRequest新增加了一个参数formdata,接受包含表单数据的字典或者可迭代的元组,并将其转化为请求的body。并且FormRequest是继承Request的
# 发送FormRequest表单请求
return FormRequest.from_response(response=response,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.post_headers,
formdata={
"utf8": utf8,
"authenticity_token": authenticity_token,
"login": login,
"password": password,
"commit": commit
},
callback=self.after_login)
案例
有时候需要解析页面嵌套,可以采用callback, 解析页面page1,通过解析页面page2解析另一个url
parse_page1 由url1产生response
def parse_page1(self, response):
item = MyItem()
item['main_url'] = response.url
request = scrapy.Request("http://www.example.com/some_page.html",
callback=self.parse_page2)
request.meta['item'] = item
yield request #将request对象发送到scheduler里面 中间要经过(request --> scheduler --> engine --> downloader --> engine --> spiders(response))
def parse_page2(self, response):
item = response.meta['item']
item['other_url'] = response.url
return item #将item结果数据发送到pipeline里面去 结果数据 item --> pipeline