一、Map集合
1.1 概述
用来存放具有一一对应这种映射关系数据的容器,即为java.util.Map集合。。
特点:
- 元素是成对存在的(key-value)。
- 双列集合,无序。
- 集合不能包含重复的键,值可以重复,每个键只能对应一个值。
1.2 Map接口中的常用方法
Map接口中定义了很多方法,常用的如下:
-
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。
ps:使用put方法时,若指定的键(key)在集合中没有,则没有这个键对应的值,返回null,并把指定的键值添加到集合中。
-
public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。 -
public V get(Object key)根据指定的键,在Map集合中获取对应的值。 -
boolean containsKey(Object key)判断集合中是否包含指定的键。 -
public Set<K> keySet() -
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的entry键值对对象的集合(Set集合)。
ps:既然Entry表示了一对键和值,那么也同样提供了获取对应键和对应值得方法:
-
- Collection<V> values():返回此映射中包含的值的
Collection视图。
ps:可以通过values方法返回的Collection对象来调用iterator()方法,从而实现取数据。(先存后取,后存先取)
1.3 Map常用子类
1.3.1
HashMap是map的子类,存储数据采用的哈希表结构,元素的key是没有顺序的,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。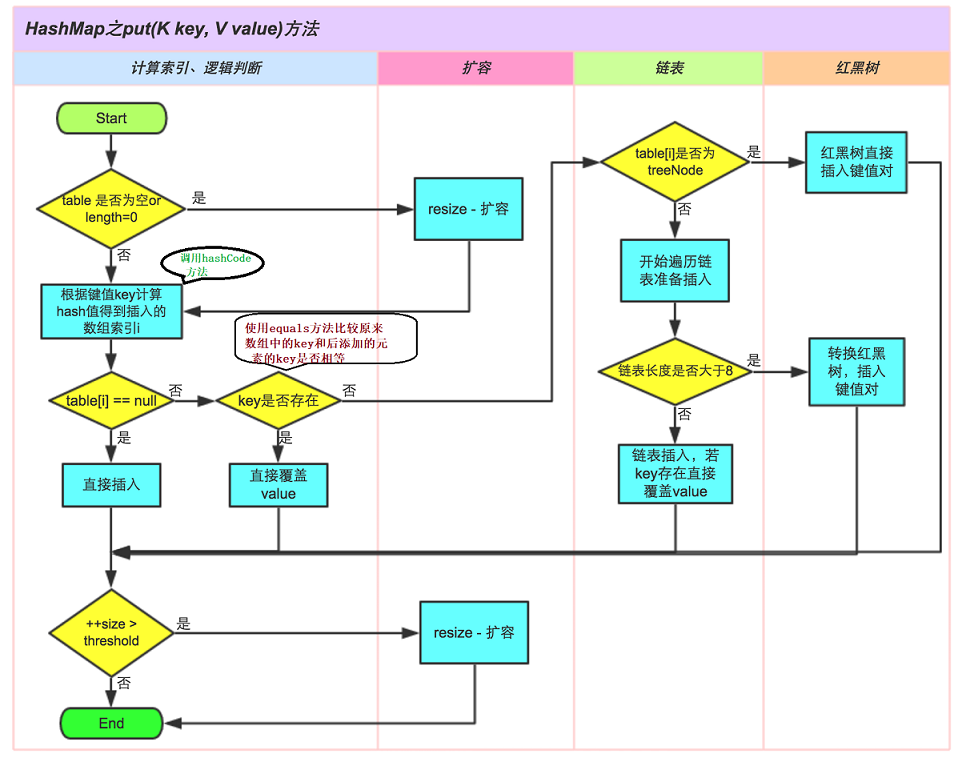
- 集合初始化时,最好指定集合初始值的大小。
比如HashMap初始化HashMap(int initialCapacity):initialCapacity=(需要存储的元素个数│负载因子)+1.注意负载因子(即loaderfactor)默认为0.75
1.3.1.2 LinkedHashMap<K,V>
LinkedHashMap是HashMap的子类,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致(有序);通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。会保存记录的插入顺序。
1.3.2 Hashtable<K,V>
存储数据采用的哈希表结构,此类实现一个哈希表,该哈希表将键映射到相应的值。任何非 null 对象都可以用作键或值。
/**
HashMap 与 HashTable 的异同:
相同点:① 都是哈希表数据结构;
不同点:① HashMap 线程不安全,效率比较高,1.2版本才有;
(如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。)
HashTable 线程安全,效率不高,1.0之前就有。
② HashMap 可以存储null;HashTable 不可以存储null。
(HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null。)
*/
1.3.3 TreeMap<K,V>
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的Comparator,否则会在运行时抛出 java.lang.ClassCastException 类型的异常。
1.3.4 ConcurrentHashMap<K,V>
1.3.4.1 并行度(默认 16)
concurrencyLevel:并行级别、并发数、Segment 数,怎么翻译不重要,理解它。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
1.3.4.2 Java8实现(引入了红黑树)
Java8 对 ConcurrentHashMap 进行了比较大的改动,Java8 也引入了红黑树。
Hashtable 是遗留类,很多映射的常用功能与 HashMap 类似,不同的是它承自 Dictionary 类,并且是线程安全的,任一时间只有一个线程能写 Hashtable,并发性不如 ConcurrentHashMap,因为 ConcurrentHashMap 引入了分段锁。Hashtable 不建议在新代码中使用,不需要线程安全的场合可以用 HashMap 替换,需要线程安全的场合可以用 ConcurrentHashMap 替换。
1.4 JDK9对集合添加的优化
Java 9,添加了几种集合工厂方法,更方便创建少量元素的集合、map实例。新的List、Set、Map的静态工厂方法可以更方便地创建集合的不可变实例。
public class HelloJDK9 {
public static void main(String[] args) {
Set<String> str1 = Set.of("a","b","c");
//str1.add("c");这里编译的时候不会错,但是执行的时候会报错,因为是不可变的集合
System.out.println(str1);
Map<String,Integer> str2 = Map.of("a",1,"b",2);
System.out.println(str2);
List<String> str3 = List.of("a","b");
System.out.println(str3);
}
}
1:of() 方法只是Map,List,Set这三个接口的静态方法,其父类接口和子类实现并没有这类方法;
2:返回的集合是不可变的。
二、
-
-
public String getProperty(String key):使用此属性列表中指定的键搜索属性值。 -
public Set<String> stringPropertyNames()
public class ProDemo {
public static void main(String[] args) throws FileNotFoundException {
// 创建属性集对象
Properties pro = new Properties();
// 加载文本中信息到属性集
pro.load(new FileInputStream("read.txt"));
// 遍历集合并打印
Set<String> strings = pro.stringPropertyNames();
for (String key : strings ) {
System.out.println(key+" -- "+pro.getProperty(key));
}
}
}
输出结果:
filename -- wfx.txt
length -- 20200819
location -- D:wfx.txt
- stroe(Writer, comments):把集合中的数据,保存到指定的流所对应的文件中,参数commonts代表描述信息
Public class PropertiesDemo {
Public static void main(String[] args) throws IOException {
//1,创建Properties集合
Properties prop = new Properties();
//2,添加元素到集合
prop.setProperty("name", "jack");
prop.setProperty("age", "25");
prop.setProperty("address", "usa");
//3,创建流
FileWriter out = new FileWriter("prop.properties");
//4,把集合中的数据存储到流所对应的文件中
prop.store(out, "save data");
//5,关闭流
out.close();
}
}
小贴士:文本中的数据,必须是键值对形式,可以使用空格、等号、冒号等符号分隔。