一、视频学习
1、广泛应用:图像着色、图像超像素、背景模糊、人脸生成、文本生成图片、字体变换、图像风格变换、图像修复、帧预测
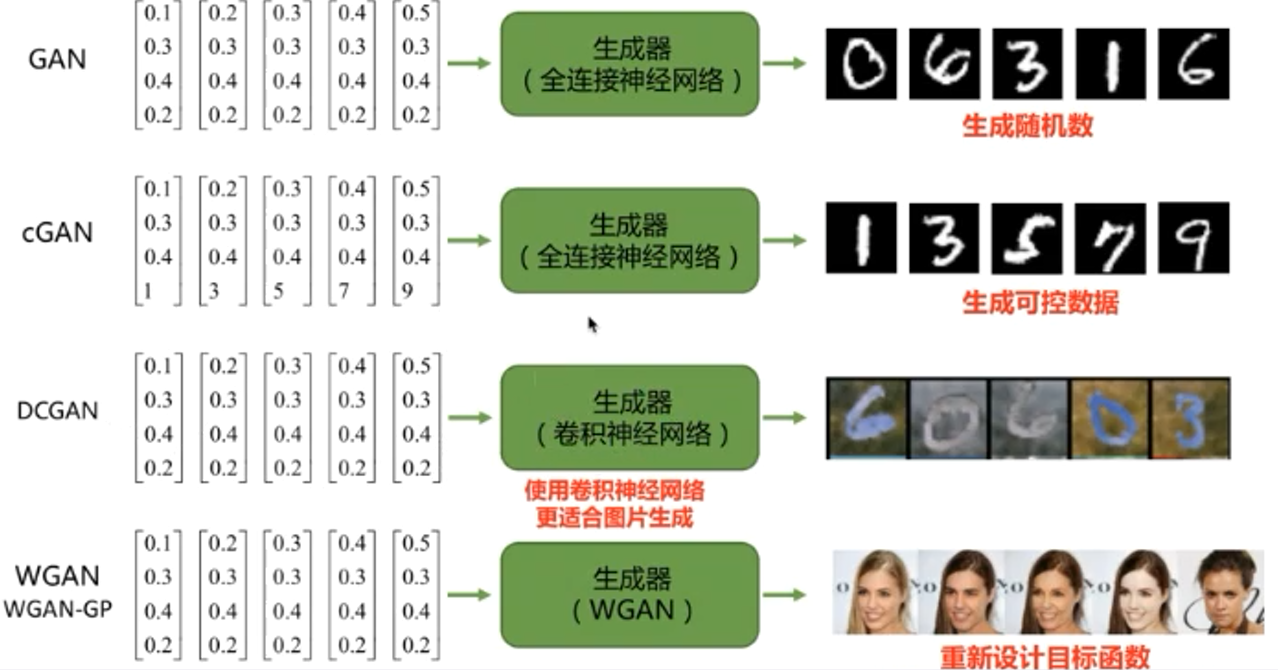
2、GAN
生成式对抗网络是用于训练生成模型从而获得想要的数据。
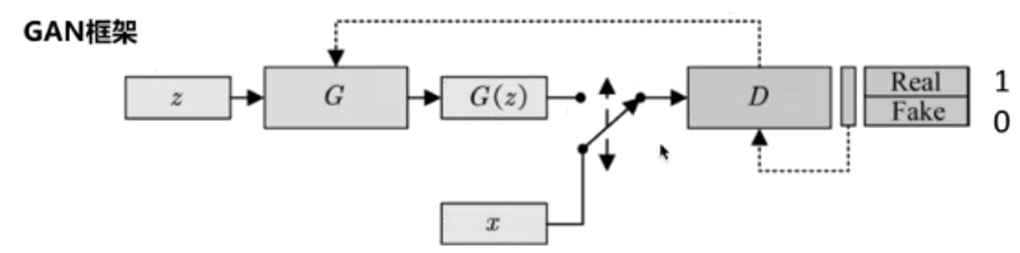
判别器D用于区分真实样本和虚假样本,real样本为1,fake样本为0;
生成器G用于生成虚假样本,欺骗判别器,尽可能让生成样本为1。
训练算法:(1)随机生成生成器和判别器
(2)交替训练生成器G和判别器D,直至收敛:
①固定生成器G,训练判别器D区分真实图像和合成图像

②固定判别器D,训练生成器G欺骗判别器D
当判别器D最优的时候,最小化生成器G的目标函数等价于最小化真实分布和生成分布的JS散度。
G的目标函数![]()
KL散度:当P1=P2时KL散度为0;KL散度具有非负性、不对称性

JS散度:具有对称性和非负性

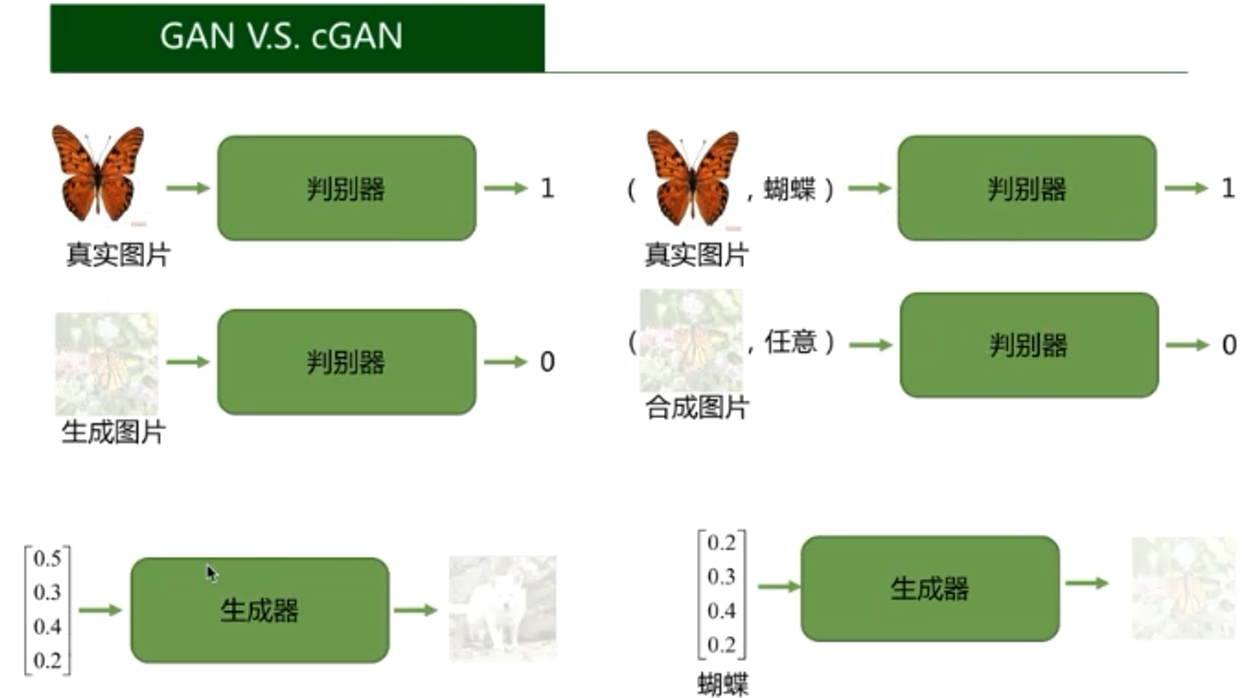
3、cGAN(条件生成式对抗网络)
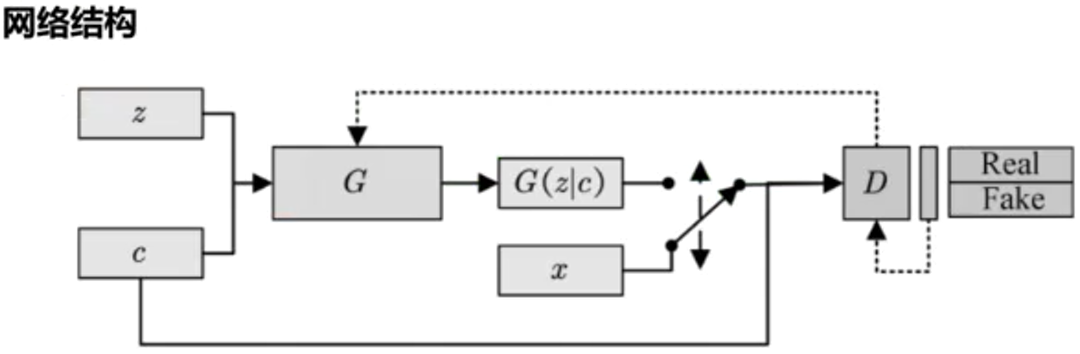
在生成器以及判别器上都多了一个标签作为输入,输出仍然跟GAN一样。
4、DCGAN(原始GAN使用全连接,DCGAN使用卷积神经网络)
判别器使用滑动卷积,由于POOLING下采样没有参数不能学习,所以采用步长大于1的滑动卷积;
生成器使用滑动反卷积,通过插值上采样不可学习的,所以将feature map用零间隔开,再使用步长为1的滑动反卷积;
采用BatchNorm的批归一化,使训练中每一层网络的输入同分布;
采用RELU或PRELU的方法;

二、代码学习
1、GAN
先定义生成器和优化器,以及优化算法:生成器的结构是32-->128-->2,判别器的结构是2-->128-->1。
生成器生成的是样本,即一组坐标(x,y),我们希望生成器能够由一组任意的 32组噪声生成座标(x,y)处于两个半月形状上。
判别器输入的是一组座标(x,y),最后一层是sigmoid函数,是一个范围在(0,1)间的数,即样本为真或者假的置信度。如果输入的是真样本,得到的结果尽量接近1;如果输入的是假样本,得到的结果尽量接近0。
z_dim = 32 hidden_dim = 128 # 定义生成器 net_G = nn.Sequential( nn.Linear(z_dim,hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 2)) # 定义判别器 net_D = nn.Sequential( nn.Linear(2,hidden_dim), nn.ReLU(), nn.Linear(hidden_dim,1), nn.Sigmoid()) # 定义网络的优化器 optimizer_G = torch.optim.Adam(net_G.parameters(),lr=0.0001) optimizer_D = torch.optim.Adam(net_D.parameters(),lr=0.0001)
对抗训练的具体过程:
batch_size = 50 nb_epochs = 1000 loss_D_epoch = [] loss_G_epoch = [] for e in range(nb_epochs): np.random.shuffle(X)#打乱顺序函数 real_samples = torch.from_numpy(X).type(torch.FloatTensor)#把数组转换成张量,且二者共享内存
loss_G = 0 loss_D = 0 for t, real_batch in enumerate(real_samples.split(batch_size)): # 固定生成器G,改进判别器D # 使用normal_()函数生成一组随机噪声,输入G得到一组样本 z = torch.empty(batch_size,z_dim).normal_().to(device) fake_batch = net_G(z) # 将真、假样本分别输入判别器,得到结果 D_scores_on_real = net_D(real_batch.to(device)) D_scores_on_fake = net_D(fake_batch) # 优化过程中,假样本的score会越来越小,真样本的score会越来越大,下面 loss 的定义刚好符合这一规律, # 要保证loss越来越小,真样本的score前面要加负号 # 要保证loss越来越小,假样本的score前面是正号(负负得正) loss = -torch.mean(torch.log(1-D_scores_on_fake) + torch.log(D_scores_on_real)) # 梯度清零 optimizer_D.zero_grad() # 反向传播优化 loss.backward() # 更新全部参数 optimizer_D.step() loss_D += loss # 固定判别器,改进生成器 # 生成一组随机噪声,输入生成器得到一组假样本 z = torch.empty(batch_size,z_dim).normal_().to(device) fake_batch = net_G(z) # 假样本输入判别器得到 score D_scores_on_fake = net_D(fake_batch) # 我们希望假样本能够骗过生成器,得到较高的分数,下面的 loss 定义也符合这一规律 # 要保证 loss 越来越小,假样本的前面要加负号 loss = -torch.mean(torch.log(D_scores_on_fake)) optimizer_G.zero_grad() loss.backward() optimizer_G.step() loss_G += loss if e % 50 ==0: print(f' Epoch {e} , D loss: {loss_D}, G loss: {loss_G}') loss_D_epoch.append(loss_D) loss_G_epoch.append(loss_G)
loss的变化情况如下图:
生成的假样本测试如下,白色的点是原来的真实样本, 黑色的点是生成器生成的样本.:

发现效果并不好,修改学习率为 0.001,batch_size为250:

2、cGAN
生成器的输入是噪声和标签,输出还是生成图;判别器的输入是生成图,真实图以及标签,输出还是真和假。先定义生成器和判别器:
#生成器:(784 + 10) ==> 512 ==> 256 ==> 1 #判别器:(100 + 10) ==> 128 ==> 256 ==> 512 ==> 784 class Discriminator(nn.Module): '''全连接判别器,用于1x28x28的MNIST数据,输出是数据和类别''' def __init__(self): super(Discriminator, self).__init__() self.model = nn.Sequential( nn.Linear(28*28+10, 512), nn.LeakyReLU(0.2, inplace=True), nn.Linear(512, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 1), nn.Sigmoid() ) def forward(self, x, c): x = x.view(x.size(0), -1) validity = self.model(torch.cat([x, c], -1)) return validity class Generator(nn.Module): '''全连接生成器,用于1x28x28的MNIST数据,输入是噪声和类别''' def __init__(self, z_dim): super(Generator, self).__init__() self.model = nn.Sequential( nn.Linear(z_dim+10, 128), nn.LeakyReLU(0.2, inplace=True), nn.Linear(128, 256), nn.BatchNorm1d(256, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 512), nn.BatchNorm1d(512, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Linear(in_features=512, out_features=28*28), nn.Tanh() ) def forward(self, z, c): x = self.model(torch.cat([z, c], dim=1)) x = x.view(-1, 1, 28, 28) return x
初始化损失函数和优化器,开始训练:
# 初始化构建判别器和生成器 discriminator = Discriminator().to(device) generator = Generator(z_dim=z_dim).to(device) # 初始化二值交叉熵损失 bce = torch.nn.BCELoss().to(device) ones = torch.ones(batch_size).to(device) zeros = torch.zeros(batch_size).to(device) # 初始化优化器,使用Adam优化器 g_optimizer = optim.Adam(generator.parameters(), lr=learning_rate) d_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate) # 开始训练,一共训练total_epochs for epoch in range(total_epochs): # torch.nn.Module.train() 指的是模型启用 BatchNormalization 和 Dropout # torch.nn.Module.eval() 指的是模型不启用 BatchNormalization 和 Dropout # 因此,train()一般在训练时用到, eval() 一般在测试时用到 generator = generator.train() # 训练一个epoch for i, data in enumerate(dataloader): # 加载真实数据 real_images, real_labels = data real_images = real_images.to(device) # 把对应的标签转化成 one-hot 类型 tmp = torch.FloatTensor(real_labels.size(0), 10).zero_() real_labels = tmp.scatter_(dim=1, index=torch.LongTensor(real_labels.view(-1, 1)), value=1) real_labels = real_labels.to(device) # 生成数据 # 用正态分布中采样batch_size个随机噪声 z = torch.randn([batch_size, z_dim]).to(device) # 生成 batch_size 个 ont-hot 标签 c = torch.FloatTensor(batch_size, 10).zero_() c = c.scatter_(dim=1, index=torch.LongTensor(np.random.choice(10, batch_size).reshape([batch_size, 1])), value=1) c = c.to(device) # 生成数据 fake_images = generator(z,c) # 计算判别器损失,并优化判别器 real_loss = bce(discriminator(real_images, real_labels).squeeze(-1), ones) fake_loss = bce(discriminator(fake_images.detach(), c).squeeze(-1), zeros) d_loss = real_loss + fake_loss d_optimizer.zero_grad() d_loss.backward() d_optimizer.step() # 计算生成器损失,并优化生成器 g_loss = bce(discriminator(fake_images, c).squeeze(-1), ones) g_optimizer.zero_grad() g_loss.backward() g_optimizer.step() # 输出损失 print("[Epoch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, total_epochs, d_loss.item(), g_loss.item()))
生成随机噪声,查看效果:

上面代码是把图像直接拉成一个向量来处理,没有考虑空间上的特性,效果并不好,接下来看DCGAN的效果。
3、DCGAN
DCGAN输入的图像被 resize 成 32*32 像素后,重新定义生成器和判别器:
class D_dcgan(nn.Module): '''滑动卷积判别器''' def __init__(self): super(D_dcgan, self).__init__() self.conv = nn.Sequential( # 第一个滑动卷积层,不使用BN,LRelu激活函数 nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True), # 第二个滑动卷积层,包含BN,LRelu激活函数 nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(32), nn.LeakyReLU(0.2, inplace=True), # 第三个滑动卷积层,包含BN,LRelu激活函数 nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(64), nn.LeakyReLU(0.2, inplace=True), # 第四个滑动卷积层,包含BN,LRelu激活函数 nn.Conv2d(in_channels=64, out_channels=128, kernel_size=4, stride=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2, inplace=True) ) # 全连接层+Sigmoid激活函数 self.linear = nn.Sequential(nn.Linear(in_features=128, out_features=1), nn.Sigmoid()) def forward(self, x): x = self.conv(x) x = x.view(x.size(0), -1) validity = self.linear(x) return validity class G_dcgan(nn.Module): '''反滑动卷积生成器''' def __init__(self, z_dim): super(G_dcgan, self).__init__() self.z_dim = z_dim # 第一层:把输入线性变换成256x4x4的矩阵,并在这个基础上做反卷机操作 self.linear = nn.Linear(self.z_dim, 4*4*256) self.model = nn.Sequential( # 第二层:bn+relu nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=3, stride=2, padding=0), nn.BatchNorm2d(128), nn.ReLU(inplace=True), # 第三层:bn+relu nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace=True), # 第四层:不使用BN,使用tanh激活函数 nn.ConvTranspose2d(in_channels=64, out_channels=1, kernel_size=4, stride=2, padding=2), nn.Tanh() ) def forward(self, z): # 把随机噪声经过线性变换,resize成256x4x4的大小 x = self.linear(z) x = x.view([x.size(0), 256, 4, 4]) # 生成图片 x = self.model(x) return x
定义损失函数和优化器:
# 构建判别器和生成器 d_dcgan = D_dcgan().to(device) g_dcgan = G_dcgan(z_dim=z_dim).to(device) def weights_init_normal(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: torch.nn.init.normal_(m.weight.data, 0.0, 0.02) elif classname.find('BatchNorm2d') != -1: torch.nn.init.normal_(m.weight.data, 1.0, 0.02) torch.nn.init.constant_(m.bias.data, 0.0) # 使用均值为0,方差为0.02的正态分布初始化神经网络 d_dcgan.apply(weights_init_normal) g_dcgan.apply(weights_init_normal) # 初始化二值交叉熵损失 bce = torch.nn.BCELoss().to(device) ones = torch.ones(batch_size).to(device) zeros = torch.zeros(batch_size).to(device) # 初始化优化器,使用Adam优化器 g_dcgan_optim = optim.Adam(g_dcgan.parameters(), lr=learning_rate) d_dcgan_optim = optim.Adam(d_dcgan.parameters(), lr=learning_rate)
开始训练:
# 开始训练,一共训练 total_epochs for e in range(total_epochs): # 给generator启用 BatchNormalization g_dcgan = g_dcgan.train() # 训练一个epoch for i, data in enumerate(dcgan_dataloader): # 加载真实数据,不加载标签 real_images, _ = data real_images = real_images.to(device) # 用正态分布中采样batch_size个噪声,然后生成对应的图片 z = torch.randn([batch_size, z_dim]).to(device) fake_images = g_dcgan(z) # 计算判别器损失,并优化判别器 real_loss = bce(d_dcgan(real_images).squeeze(-1), ones) fake_loss = bce(d_dcgan(fake_images.detach()).squeeze(-1), zeros) d_loss = real_loss + fake_loss d_dcgan_optim.zero_grad() d_loss.backward() d_dcgan_optim.step() # 计算生成器损失,并优化生成器 g_loss = bce(d_dcgan(fake_images).squeeze(-1), ones) g_dcgan_optim.zero_grad() g_loss.backward() g_dcgan_optim.step() # 输出损失 print ("[Epoch %d/%d] [D loss: %f] [G loss: %f]" % (e, total_epochs, d_loss.item(), g_loss.item()))
训练结果:

增大epoch到60的数量后的效果:

可以看到效果并没有编号,甚至模糊的形状很统一。
三、遇到疑问
1、one-hot编码是怎么个意思?
one-hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。将类别标签转换为one-hot编码,比如说第7类,就是[0,0,0,0,0,0,1,0,0,0]
2、代码运行时出现了size不匹配的问题,怎么整?
可使用squeeze将维度从(128,1)压缩为(128)。
3、epoch数量的增加并没有优化图像。