一、论文阅读
1、《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
这篇论文介绍了适用于移动端和嵌入端的MobileNets,MobileNets在物体识别、细粒度分类、人脸属性和大规模的地理定位的应用上具有高效性。该网络架构的突出特点是一个网络架构和两个超参数:网络架构是基于深度卷积和1x1的点卷积;两个超参数是width multiplier和resolution multiplier,用于均衡延迟latency和正确性accuracy,在优化延迟的同时生成小型网络。
在介绍MobileNets之前,作者先是介绍了构建小型网络的几种方法:①使用bottleneck设计;②使用shrinking设计,分解压缩网络和训练网络,常用压缩方法有product quantization、hashing、pruning、vector quantization和Huffman coding;③使用蒸馏(distillation)设计,用大型网络训练小型网络;④使用low bit networks设计。
接下来是对MobileNets的具体介绍:
(1)MobileNet模型基于深度可分离卷积建立,是一种分解卷积的形式,把标准卷积分解成了一种深度卷积(depthwise convolution)和一个1x1的逐点卷积(pointwise convolution),深度卷积在每个通道(channel)上应用一个卷积核,逐点卷积应用1x1卷积把输出和深度卷积结合起来。标准卷积在一个步骤把卷积核和输入结合为新的输出,而深度可分离卷积将其分为两层,一层用于滤波(filtering),一层用于结合,这个分解过程极大地减少了计算量和模型的大小。标准卷积操作具有基于卷积核的滤波特征和结合特征从而产生新的特征,滤波和结合步骤可以通过使用分解卷积(也叫做深度可分离卷积)分为两个步骤以降低计算成本。
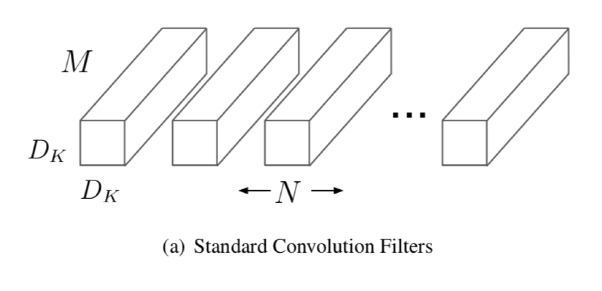
一个标准的卷积层把一个DF*DF*M的特征图(feature map)F作为输入,生成一个DG*DG*N的特征图G,DF是输入特征图的正方形宽度和高度,M是输入通道(input channels或者input depth)的数目,DG是输出特征图的正方形的宽度和高度,N是输出通道的数目。标准卷积层由大小为DK*DK*M*N的卷积核K参数化,如下图所示(a)。DK是正方形卷积核的空间维度,M是输入通道的数目,N是输出通道的数目。
标准卷积假设步长为1,并且考虑padding,输出特征图feature map计算如下:
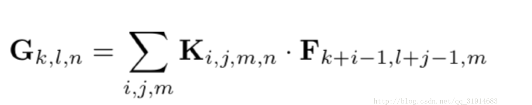
标准卷积的计算代价为:DK· DK· M · N · DF· DF
深度可分离卷积由两层组成:深度卷积和逐点卷积。作者使用深度卷积为每一个输出通道应用单个滤波器,逐点卷积被用来创建深度层的输出的线性叠加。MobileNets对两个层都使用batchnorm和ReLU。
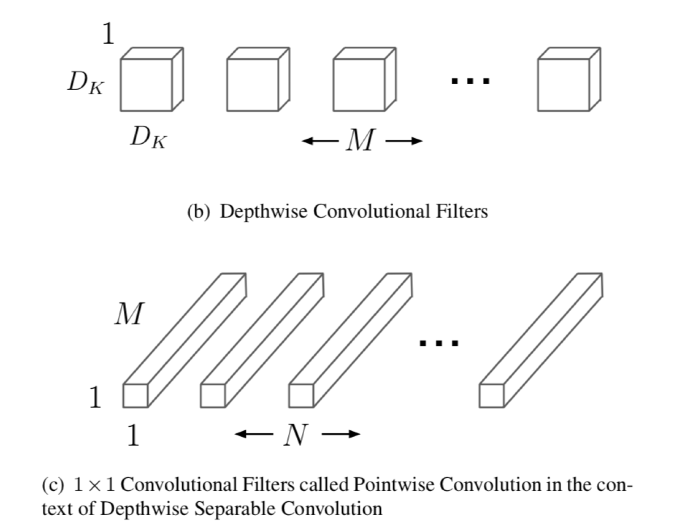
每个输入通道一个滤波器的深度卷积(输入深度)可以写成:
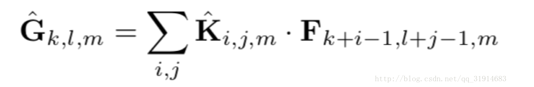
深度卷积计算代价:DK· DK· M · DF· DF
深度卷积只过滤输入通道,不会将它们结合起来创建新特性,所以通过1×1卷积计算深度卷积输出的线性组合来产生这些新的特征,将深度卷积与1×1(点态)卷积的结合称为深度可分离卷积。
深度可分离卷积计算代价(深度卷积代价+逐点卷积代价):DK· DK· M · DF· DF+ M · N · DF· DF
MobileNet使用3×3深度可分离卷积,与标准卷积相比,在精度上略有降低但是减少了8到9倍的计算量。
(2)MobileNet结构是建立在深度可分离的卷积,架构定义如下表,第一层是一个完整的卷积,最后是没有线性激活函数的全连接层,直接输入到softmax层进行分类,其余所有层之后都有batchnorm和ReLU非线性。s2在深度卷积和第一层中指的是处理下行采样,在全连接层之前的平均池化将空间维度降低到1。将深度卷积和点卷积作为单独的层,MobileNet有28层。
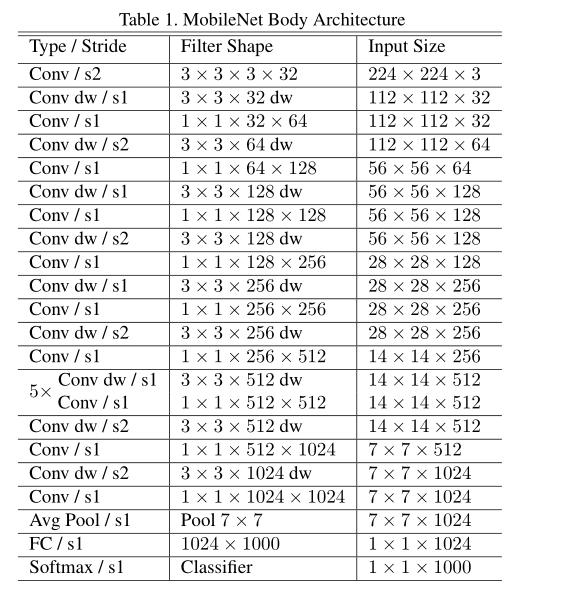
接着看参数,作者的模型结构几乎把全部的计算复杂度放到了1x1卷积中,1x1卷积不要求内存的排序而且可以直接由GEMM实现。MobileNet在1*1卷积花费了95%的计算时间,也有75%的参数量,几乎所有的额外参数都在全连接层。
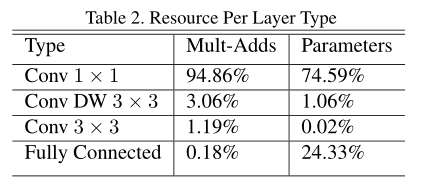
与训练大模型相反,由于小模型不容易过拟合,作者使用较少的正则化和数据增加技术。当训练MobileNets的时候,作者没有使用side heads或者label smoothing,而是通过在大型Inception训练中使用的限制小的cropping的尺寸来减少图片扭曲。同样,深层卷积核的参数量很少,所以要放置较少或者不放置weight decay。
(3)这部分主要讲解两个超参数:width multiplier和resolution multiplier
为了构造更小更少计算开销的模型,引入了一个非常简单的参数——width multiplier α,α作用是在每一层均匀地减负网络,典型数值为1、0.75、0.5、0.25。
带有α的深度可分离卷积的计算代价:DK· DK· αM · DF· DF+ αM · αN · DF· DF
resolution multiplier ρ应用在输入图片,每个层的内部特征被减去相同的乘数,典型隐式设置以使网络输入分辨率是224,192,160,128。
带有α和ρ的深度可分离卷积网络核心层的计算复杂度为:DK· DK· αM · ρDF· ρDF+ αM · αN · ρDF· ρDF
(4)最后是实验部分,作者通过比较不同的MobileNets和流行的模型展示了其大小、速度和准确度的特性
①Model Choices进行模型比较
首先是进行深度可分离卷积的MobileNet和全卷积的模型结果比较,准确率相差不大,但是Mult-Adds和参数都减少了很多:

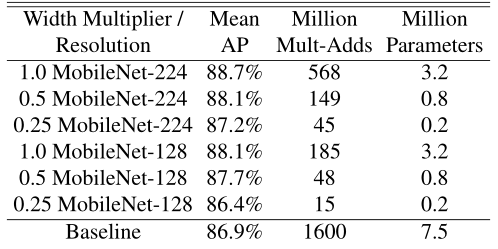
接着进行带有width multiplier的深度可分离卷积和层数更少的模型进行比较,在计算量和参数差不多的情况下,可以发现thinner比shallow准确率更高:

②Model Shrinking Hyperparameters
用width multiplier α收缩MobileNet架构之后准确度、计算量以及尺寸之间的折中,可以发现准确度随着模型的变小而下降:

用reduced input resolutions训练MobileNets时,不同的resolution multiplier ρ值准确度、计算量和尺寸的折中,可以发现准确度随着分辨率变低而下降:
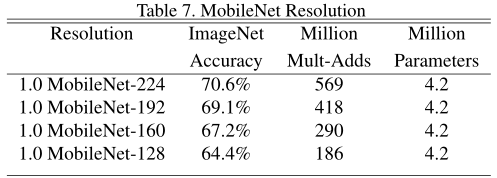
由width multiplier α∈{1,0.75,0.5,0.25}和resolution{224,192,160,128}的cross product生成的16个模型时在ImageNet准确度和计算量的折中,α=0.25模型非常小的时候结果是对数线性跳跃:
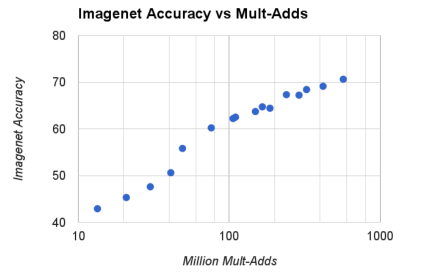
由width multiplier α ∈{1,0.75,0.5,0.25}和resolution{224,192,160,128}的cross product生成的16个模型时在ImageNet准确度和参数量的折中:

比较了full MobileNet、GoogleNet和VGG16,MobileNet的正确率还是很不错的在,但是在计算量和参数量上十分优越:

比较了Reduced MobileNet、AlexNet和SqueezeNet,性能十分优越:

③Fine Grained Recognition细粒度识别
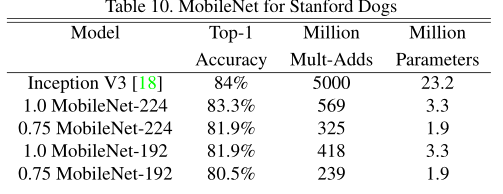
使用噪声更大的Stanford Dogs dataset训练细粒度狗的识别模型,在Stanford Dogs训练集上进行微调,可以发现正确率几乎可以与Inception V3相媲美。
④Large Scale Geolocation大范围的地理位置识别
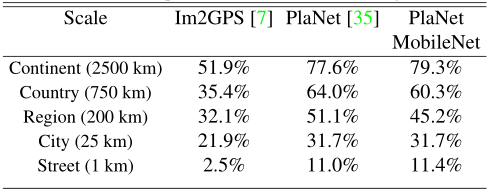
PlaNet把地球分成了一个个单元格集合到目标类别,用百万个地理位置标记图片训练卷积神经网络,作者在相同的数据使用MobileNet架构预训练PlaNet,性能只是略有降低,但是规模小了很多:
⑤ Face Attributes
作者采用MobileNet架构提取一个人脸特征分类器,利用蒸馏法通过训练分类器来仿真一个更大的模型的输出而不是采用人工标注,因而能够从大型(可能无限大)的未标注的数据集中进行训练。结合蒸馏训练的可扩展性和MobileNet的简洁参数化,最终系统不仅不需要正则化,而且还演示了增强的性能。
⑥Object Detection
MobileNet与在Faster-RCNN和SSD框架下的VGG和Inception V2进行比较,SSD以300输入分辨率(SSD 300)进行评估,fast - rcnn与300和600输入分辨率(FasterRCNN 300, Faster-RCNN 600)进行比较Faster-RCNN模型评估每幅图像300个RPN proposal boxes,模型在除去了8000最小图片的COCO训练集并在最小值上进行评估。
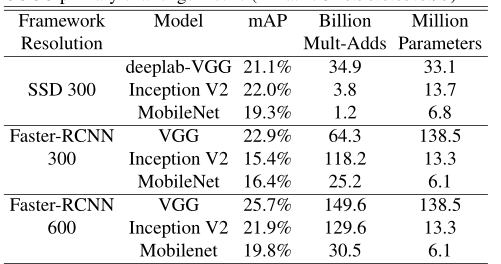
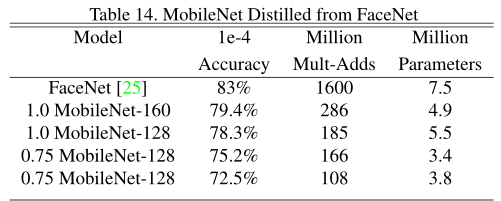
⑦ Face Embeddings
为了建立一个移动的FaceNet模型,作者使用了蒸馏法通过最小化FaceNet和MobileNet在训练集输出结果的平方差进行训练。
2、《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
这篇文章介绍了新的网络架构MobileNetV2,MobileNetV2 的重要特征是带有线性瓶颈结构的反向残差结构,主要的改动是添加了线性Bottleneck和将skip-connection转移到低维bottleneck层。最后作者通过实验ImageNet分类,COCO目标检测,VOC图像分割验证性能。
(1)MobileNetV2的架构思路
MobileNetV2该技术最创新的点是包括线性瓶颈的反向残差结构,该模块以一个低维压缩的特征表达作为输入,先将其扩展到高维,然后用一个轻量级的深度卷积进行滤波,得到的特征随后通过线性卷积被投影回低维空间。此外,这个卷积模块特别适合于移动设计,因为它可以通过不产生大型中间张量来显著减少内存占用。
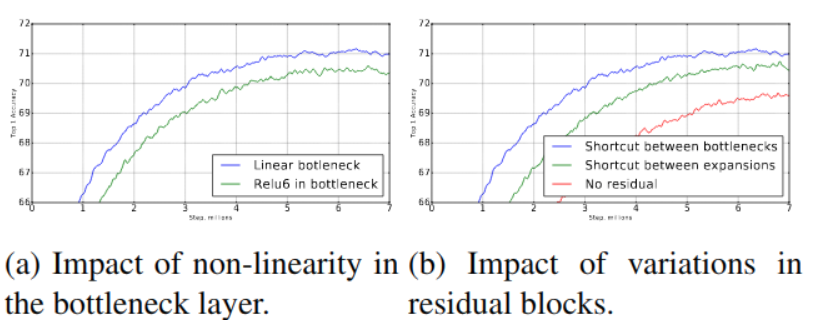
经过激活层后的张量被称为兴趣流形。在MobileNetV1中使用width multiplier参数进行计算量与精确度的权衡,简单的降低层的维度从而降低操作空间的维度,当神经网络中有ReLU非线性时这种方法是不可行的。比如说一个变换层ReLU(Bx)结果有非零成员S可以看到,映射到S内部的点是通过输入的线性变化B得到的,这意味着受限于线性变换,部分输入空间对应着全出的输入维度。换句话说,深度网络只有在输出非零部分才有线性分类的能力。如下图所示,低维使用随机矩阵T和ReLU变换到高维,再使用T^(-1)投射回低维,可以看到会出现信息的丢失。当ReLU分解通道的时候,会造成通道信息的损失。然而如果我们有许多通道,并且有一个结构在激活通道分流的时候信息保留在其他通道中,那么ReLU变换在引入可表达函数集的同时保留信息。

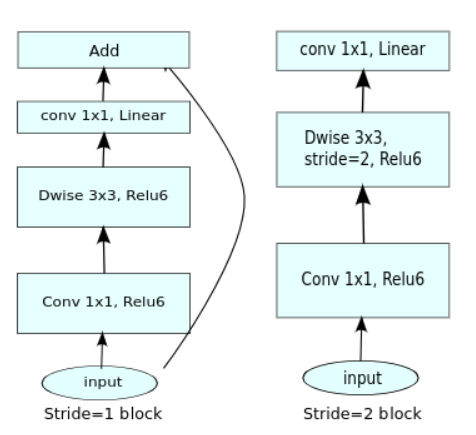
下图中左图的传统的residual block,先用1x1卷积将输入的feature map的维度降低,然后进行3x3的卷积操作,最后再用1x1的卷积将维度变大。右图即为本文提出的结构,先用1x1卷积将输入的feature map维度变大,然后用3x3 depthwise convolution方式做卷积运算,最后使用1x1的卷积运算将其维度缩小,其中使用的是ReLU6激活函数。注意,此时的1x1卷积运算后,不再使用ReLU激活函数,而是使用线性激活函数,以保留更多特征信息,保证模型的表达能力。针对manifold of interest对位于高维激活空间的低维子空间的要求,强调了两个特性:①如果manifold of interest在ReLU变换后任然保持非零值,那么对应线性变换。②ReLU可以在输入manifold分布在输入空间的低维子空间时保持完整的信息。通过这两个特性,作者提出通过插入线性瓶颈到卷积块去捕获manifold of interest,防止非线性破坏太多信息。
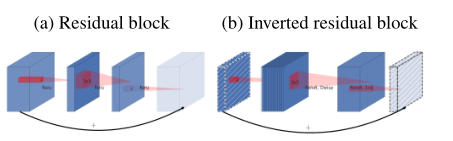
瓶颈结构模块与残差模块类似,每个模块包含一个输入紧接着几个瓶颈结构,最后跟着一个扩张结构。受到瓶颈结构实际上包含了所有必要信息的启发,而膨胀层只是作为一个伴随tensor非线性变化的实现细节,我们在瓶颈结构件直接使用shortcut。本文提出使用线性变换替代Bottleneck的激活层,而在需要激活的卷积层中,使用较大的M使张量在进行激活前先扩张,整个单元的输入输出是低维张量,而中间的层则用较高维的张量。
图a中普通卷积将channel和spatial的信息同时进行映射,参数量较大;图b为可分离卷积,解耦了channel和spatial,化乘法为加法,有一定比例的参数节省;图c中进行可分离卷积后又添加了bottleneck,映射到低维空间中;图d则是从低维空间开始,进行可分离卷积时扩张到较高的维度(前后维度之比被称为expansion factor,扩张系数),之后再通过1x1卷积降到原始维度。
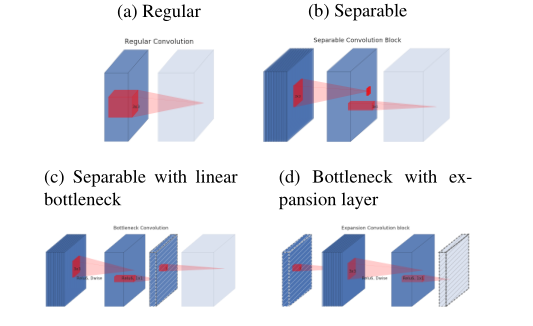
标准卷积取input张量Li计算代价hi*wi*di,利用卷积核K∈R^(k *k*di*dj)来生成output张量Lj计算代价hi*wi*dj。标准卷积层的计算代价为hi·wi·di·dj·k·k。深度可分离卷积划分成两层后计算代价为hi· wi· di(k2+ dj),深度可分离卷积以系数k^2降低传统卷积的计算量。MobileNetV2使用k=3(3×3深度可分离卷积),因此计算量比传统卷积要小8到9倍,精度上有微小的损失。
瓶颈卷积的实现如下表所示。对于一个大小为h×w的模块来说,膨胀系数为t、kernel size为 k,输入通道为d',输出通道为d'',所有的乘加需求为h · w · d‘· t(d’+ k^2+ d‘’),与之前的式子相比有一个额外的项,是由于一次额外的1×1卷积,然而网络的特性允许利用更小的输入和输出维数。当stride s=1时,block有shortcut,当s=2时,block没有shortcut。

(2)MobileNetsV2架构实现
下图中,t代表单元的扩张系数,c代表channel数,n为单元重复个数,s为stride数。可见,网络整体上遵循了重复相同单元和加深则变宽等设计范式。
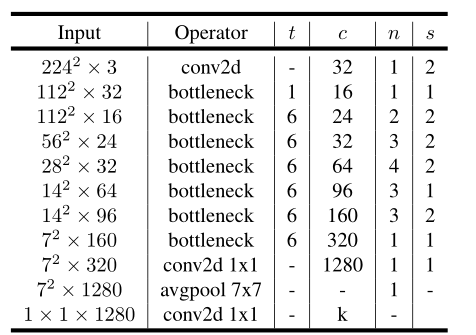
卷积块架构,文末指出这种设计将层输入、输出空间跟层变换分离,即网络容量(capacity)和表达力(expressIveness)的解耦。可以看出架构中加入了1×1升维,引入Shortcut并且去掉了最后的ReLU,改为Linear。步长为1时,先进行1×1卷积升维,再进行深度卷积提取特征,再通过Linear的逐点卷积降维,将input与output相加,形成残差结构。步长为2时,因为input与output的尺寸不符,因此不添加shortcut结构:
关于线性变换bottleneck替代ReLU和skip-connection位置的实验:
(3)MobileNetV2的实验
①ImageNet Classification
作者使用标准的RMSPropOptimizer,MobileNetV2 vs MobileNetV1(MobileNetV2集成V1的两个超参数), ShuffleNet, NAS的性能曲线,可以看到v1版本的性能优越:

②Object Detection
作者介绍了一种修改版的SSDLite,在SSD预测层中,将所有的规则卷积替换为可分离卷积:
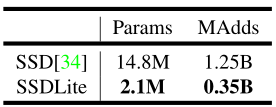
然后使用MobileNetV2 + SSDLite和其他实时检测器在COCO数据集对象检测任务上进行性能比较,可以看到精度方面跟YOLOv2和SSD300相差不大,但模型参数和运算复杂度都有一个数量级的减少。
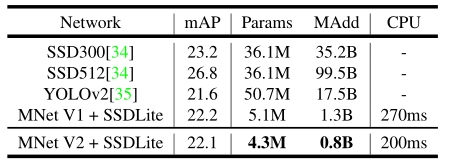
③Semantic Segmentation
为了构建一个移动模型,作者尝试了三种设计变体:(1)不同的特征提取器;(2)简化DeepLabv3头部以提高计算速度;(3)不同的推理策略以提高性能。作者将MobileNetV1和MobileNetV2模型作为特征提取器,与DeepLabv3进行移动语义分割的比较,在PASCAL VOC 2012数据集进行实验:
2-D-CNN无法从光谱维数中提取出具有良好鉴别能力的特征图,3-D-CNN增加了计算的复杂性,而提出的混合光谱CNN(HybridSN),充分利用光谱和空间特征图,以达到最大可能的精度。 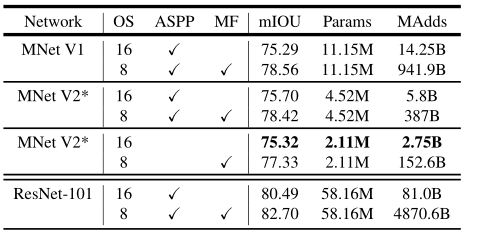
(4)与MobileNetV1的比较
主要区别有两点:
①Depth-wise convolution之前多了一个1*1的“扩张”层,目的是为了提升通道数,获得更多特征;
②最后不采用Relu,而是Linear,目的是防止Relu破坏特征。
3、《HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification》
(1)这篇论文较短,首先要了解一下高光谱:
高光谱图像(HSI)分类广泛应用于遥感图像分析,且性能高度依赖于空间信息和光谱信息。卷积神经网络(CNN)常用于进行HSI分类,但多基于2-D CNN,少有使用3-D-CNN的。HSI分类有两种处理方式:一种是基于手工的特征提取技术和另一种是基于学习的特征提取技术。本篇论文提出了混合光谱CNN(HybridSN),组合了2-D-CNN和3-D-CNN,降低模型复杂性。作者还在印第安松、帕维亚大学和萨利纳斯场景遥感数据集上进行了非常严格的HSI分类实验。
2-D-CNN无法从光谱维数中提取出具有良好鉴别能力的特征图,3-D-CNN增加了计算的复杂性,而提出的混合光谱CNN(HybridSN),充分利用光谱和空间特征图,以达到最大可能的精度。
(2)提出HybridSN模型
空间光谱高光谱数据立方体表示为: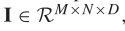 ,I为原始输入,M为宽度,N为高度,D为光谱带数/深度,I中的每个HSI像素包含D个光谱测度,形成一个one-hot向量。
,I为原始输入,M为宽度,N为高度,D为光谱带数/深度,I中的每个HSI像素包含D个光谱测度,形成一个one-hot向量。 ,C是land-cover的类别。
,C是land-cover的类别。
为了去除光谱冗余,首先对原始HSI数据沿光谱波段进行传统的主成分分析(PCA),主成分分析在保持空间维数不变(即宽度M,高度N)的情况下,将光谱频带从D减少到B,只减少了光谱频带,从而保留了识别物体的空间信息。PCA之后的数据立方表示为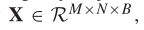 其中X为PCA后的输入,M为宽度,N为高度,B为PCA后的光谱带数。
其中X为PCA后的输入,M为宽度,N为高度,B为PCA后的光谱带数。
为了利用图像分类技术,将HSI数据立方体分成重叠的三维小块,小块的ruth label由中心像素的label决定,从X开始,创建以空间位置(α,β)为中心的三维相邻块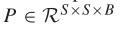 ,覆盖了S×S的窗口或者是空间范围和所有B光谱波段,在(α,β)上的三维块覆盖了宽度从α-(S-1)/2到α+(S-1)/2,高度从β-(S-1)/2到β+(S-1)/2和所有的PCA简化立体数据X的B光谱波段。在二维卷积中,第j个特征图的i层中(x,y)位置的激活值公式为
,覆盖了S×S的窗口或者是空间范围和所有B光谱波段,在(α,β)上的三维块覆盖了宽度从α-(S-1)/2到α+(S-1)/2,高度从β-(S-1)/2到β+(S-1)/2和所有的PCA简化立体数据X的B光谱波段。在二维卷积中,第j个特征图的i层中(x,y)位置的激活值公式为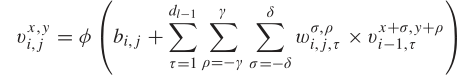 ,其中φ是激活函数,b(i, j)是第j个特征图的i层的偏差参数,d(l−1)是第(l−1)层特征图的数量和第i层j个特征图的数量,2γ+ 1是卷积核的宽度,2δ +1 是卷积核的高度,wi,j 为第i层j个特征图权重指数的值。在三维卷积中,生成第i层第j个feature map空间位置(x, y,z)的激活值公式为
,其中φ是激活函数,b(i, j)是第j个特征图的i层的偏差参数,d(l−1)是第(l−1)层特征图的数量和第i层j个特征图的数量,2γ+ 1是卷积核的宽度,2δ +1 是卷积核的高度,wi,j 为第i层j个特征图权重指数的值。在三维卷积中,生成第i层第j个feature map空间位置(x, y,z)的激活值公式为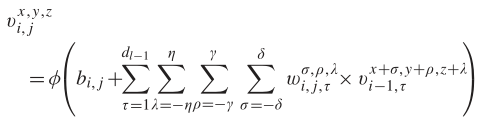 ,2η + 1 为卷积核沿光谱维数的深度,其他参数不变。
,2η + 1 为卷积核沿光谱维数的深度,其他参数不变。
为了充分利用二维和三维cnn的特征自动学习能力,作者提出了一种名为HybridSN的混合特征学习框架用于HSI分类。所提出的HybridSN网络流程图如图所示,它包括三个三维卷积、一个二维卷积和三个完全连接的层。
- 三维卷积中,卷积核的尺寸为8×3×3×7×1、16×3×3×5×8、32×3×3×3×16(16个三维核,3×3×5维)
- 二维卷积中,卷积核的尺寸为64×3×3×576(576为二维输入特征图的数量)

从层类型、输出映射尺寸和参数数量等方面对所提模型的详细总结如下,可以看出,参数数量最多的是第一密集层(dense layer):

(3)HybridSN实验
实验使用三种开源高光谱图像数据集,Indian Pines(IP), University of Pavia(UP) and Salinas Scene(SA)。IP图像空间维度为:145×145,波长范围为400-2500nm,共有224个光谱波段,UP图像空间维度为:610×340,波长范围430-860nm,共有103个光谱波段,SA图像空间维度为:512×217,波长范围360-2500nm,共有224个光谱波段。
实验结果如下:
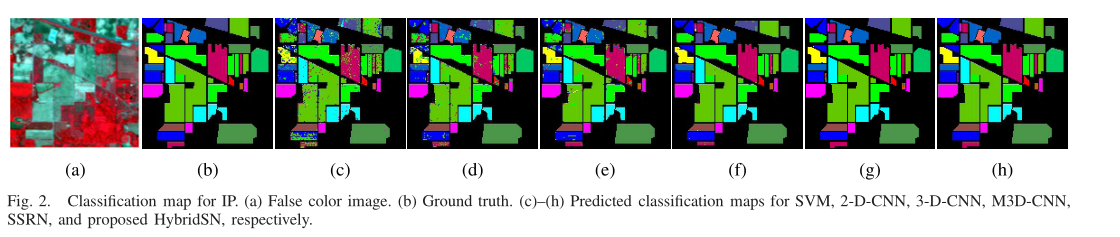 上图中作者使用SVM, 2-D-CNN, 3-D-CNN, M3D-CNN,SSRN, and HybridSN进行分类,SSRN和hybrid的分类图质量明显优于其他方法。
上图中作者使用SVM, 2-D-CNN, 3-D-CNN, M3D-CNN,SSRN, and HybridSN进行分类,SSRN和hybrid的分类图质量明显优于其他方法。
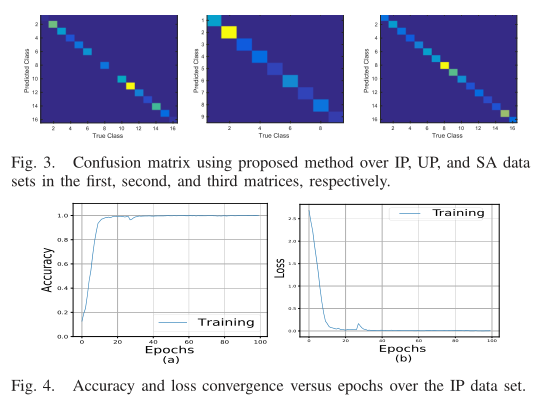
图3给出了HybridSN分别在IP、UP和SA数据集上的HSI分类性能的混淆矩阵,图4展示了训练集和验证集100个epoch的准确性和损失收敛,可以看出,收敛时间约为50个epoch。
作者使用了overall accuracy (OA), average accuracy (AA), Kappa coefficient (Kappa)评价指标来判断HSI的分类性能。其中OA表示测试样本总数中正确分类的样本数;AA为分类分类准确率的平均值;和Kappa是一个统计测量的度量,它提供了关于在地面真实地图和分类地图之间的一个强有力的协议的相互信息。
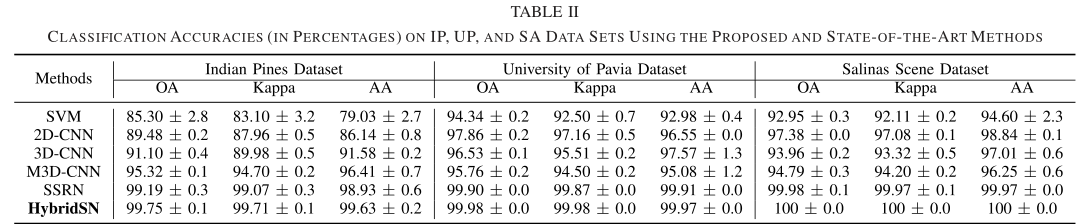
从上表可以看出HybridSN保持最小标准差的同时,在每个数据集上都是最优的。
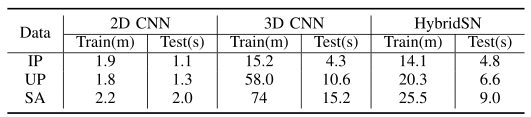
上表是三种CNN的训练和测试次数,用以观察HybridSN模型的计算效率。

上表可以看到空间维度对HybridSN模型性能的影响,window size越大性能越好。
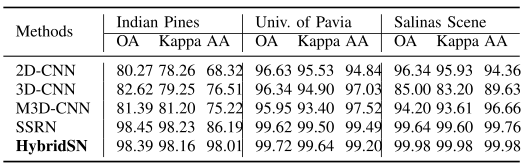
上表是训练数据值提取10%的结果,HybridSN性能仍然是最优越的。所以HybridSN在大型数据和小型数据上都能显示优越的性能。
二、代码实践
1、MobileNetV1
定义Block模块,包括深度(Depthwise)卷积和点(Pointwise)卷积,其中深度卷积是3*3的卷积核,点卷积是1*1的卷积核且padding为0。
class Block(nn.Module): '''Depthwise conv + Pointwise conv''' def __init__(self, in_planes, out_planes, stride=1): super(Block, self).__init__() # Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积 self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False) self.bn1 = nn.BatchNorm2d(in_planes) # Pointwise 卷积,1*1 的卷积核 self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, padding=0, bias=False) self.bn2 = nn.BatchNorm2d(out_planes) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) return out
定义MobileNetV1模块:
# 32×32×3 ==> # 32×32×32 ==> 32×32×64 ==> 16×16×128 ==> 16×16×128 ==> # 8×8×256 ==> 8×8×256 ==> 4×4×512 ==> 4×4×512 ==> # 2×2×1024 ==> 2×2×1024 # 接下来为均值 pooling ==> 1×1×1024 # 最后全连接到 10个输出节点 class MobileNetV1(nn.Module): # (128,2) means conv planes=128, stride=2 cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1), (1024,2), (1024,1)] def __init__(self, num_classes=10): super(MobileNetV1, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.linear = nn.Linear(1024, num_classes) def _make_layers(self, in_planes): layers = [] for x in self.cfg: out_planes = x[0] stride = x[1] layers.append(Block(in_planes, out_planes, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.avg_pool2d(out, 2) out = out.view(out.size(0), -1) out = self.linear(out) return out
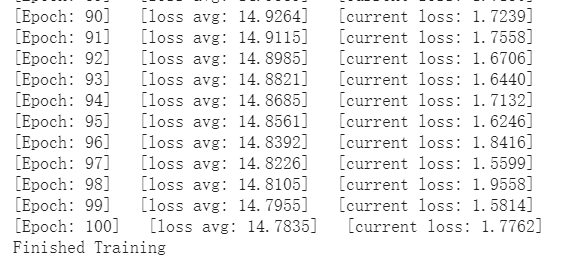
训练结果:

运行结果:
2、MobileNetV2
如果in_planes和out_planes不等的话, 需要加一个1x1的卷基层使输入的x经过shortcut后和输出是相同的shape, 才能相加。
class Block(nn.Module): '''expand + depthwise + pointwise''' def __init__(self, in_planes, out_planes, expansion, stride): super(Block, self).__init__() self.stride = stride # 通过 expansion 增大 feature map 的数量 planes = expansion * in_planes self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False) self.bn3 = nn.BatchNorm2d(out_planes) # 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数 if stride == 1 and in_planes != out_planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(out_planes)) # 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入 if stride == 1 and in_planes == out_planes: self.shortcut = nn.Sequential() def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) # 步长为1,加 shortcut 操作 if self.stride == 1: return out + self.shortcut(x) # 步长为2,直接输出 else: return out
最后的ReLU已经换成Linear
class MobileNetV2(nn.Module): # (expansion, out_planes, num_blocks, stride) cfg = [(1, 16, 1, 1), (6, 24, 2, 1), (6, 32, 3, 2), (6, 64, 4, 2), (6, 96, 3, 1), (6, 160, 3, 2), (6, 320, 1, 1)] def __init__(self, num_classes=10): super(MobileNetV2, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False) self.bn2 = nn.BatchNorm2d(1280) self.linear = nn.Linear(1280, num_classes) def _make_layers(self, in_planes): layers = [] for expansion, out_planes, num_blocks, stride in self.cfg: strides = [stride] + [1]*(num_blocks-1) for stride in strides: layers.append(Block(in_planes, out_planes, expansion, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.relu(self.bn2(self.conv2(out))) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out
训练结果:

测试结果:
3、HybridSN
HybridSN的代码就是三次三维卷积加上一次二维卷积,最后实现三次的全连接层
class HybridSN(nn.Module): def __init__(self, num_classes=class_num): super(HybridSN,self).__init__() #先进行三维卷积 #conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23) self.conv1 = nn.Conv3d(1, 8, kernel_size=(7,3,3)) self.bn1 = nn.BatchNorm3d(8) #self.layers = self._make_layers(in_planes=32) #conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21) self.conv2 = nn.Conv3d(8, 16, kernel_size=(5,3,3)) self.bn2 = nn.BatchNorm3d(16) #conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19) self.conv3 = nn.Conv3d(16, 32, kernel_size=(3,3,3)) self.bn3 = nn.BatchNorm3d(32) #二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17) self.conv4 = nn.Conv2d(576, 64, kernel_size=(3,3)) self.bn4 = nn.BatchNorm2d(64) #依次为256,128节点的全连接层,都使用比例为0.4的 Dropout self.fc1 = nn.Linear(18496,256) self.fc2 = nn.Linear(256,128) self.dropout = nn.Dropout(p = 0.4) self.fc3 = nn.Linear(128,num_classes) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = F.relu(self.bn3(self.conv3(out))) #进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19) out = out.reshape(out.shape[0],-1,19,19) out = F.relu(self.bn4(self.conv4(out))) #接下来是一个 flatten 操作,变为 18496 维的向量 out = out.view(out.size(0), -1) out = F.relu(self.dropout(self.fc1(out))) out = F.relu(self.dropout(self.fc2(out))) out = self.fc3(out) return out
实现PCA变换:
# 对高光谱数据 X 应用 PCA 变换 def applyPCA(X, numComponents): newX = np.reshape(X, (-1, X.shape[2])) pca = PCA(n_components=numComponents, whiten=True) newX = pca.fit_transform(newX) newX = np.reshape(newX, (X.shape[0], X.shape[1], numComponents)) return newX # 对单个像素周围提取 patch 时,边缘像素就无法取了,因此,给这部分像素进行 padding 操作 def padWithZeros(X, margin=2): newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2])) x_offset = margin y_offset = margin newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X return newX # 在每个像素周围提取 patch ,然后创建成符合 keras 处理的格式 def createImageCubes(X, y, windowSize=5, removeZeroLabels = True): # 给 X 做 padding margin = int((windowSize - 1) / 2) zeroPaddedX = padWithZeros(X, margin=margin) # split patches patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2])) patchesLabels = np.zeros((X.shape[0] * X.shape[1])) patchIndex = 0 for r in range(margin, zeroPaddedX.shape[0] - margin): for c in range(margin, zeroPaddedX.shape[1] - margin): patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1] patchesData[patchIndex, :, :, :] = patch patchesLabels[patchIndex] = y[r-margin, c-margin] patchIndex = patchIndex + 1 if removeZeroLabels: patchesData = patchesData[patchesLabels>0,:,:,:] patchesLabels = patchesLabels[patchesLabels>0] patchesLabels -= 1 return patchesData, patchesLabels def splitTrainTestSet(X, y, testRatio, randomState=345): X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y) return X_train, X_test, y_train, y_test
训练和测试:
# 地物类别 class_num = 16 X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected'] y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt'] # 用于测试样本的比例 test_ratio = 0.90 # 每个像素周围提取 patch 的尺寸 patch_size = 25 # 使用 PCA 降维,得到主成分的数量 pca_components = 30 print('Hyperspectral data shape: ', X.shape) print('Label shape: ', y.shape) print(' ... ... PCA tranformation ... ...') X_pca = applyPCA(X, numComponents=pca_components) print('Data shape after PCA: ', X_pca.shape) print(' ... ... create data cubes ... ...') X_pca, y = createImageCubes(X_pca, y, windowSize=patch_size) print('Data cube X shape: ', X_pca.shape) print('Data cube y shape: ', y.shape) print(' ... ... create train & test data ... ...') Xtrain, Xtest, ytrain, ytest = splitTrainTestSet(X_pca, y, test_ratio) print('Xtrain shape: ', Xtrain.shape) print('Xtest shape: ', Xtest.shape) # 改变 Xtrain, Ytrain 的形状,以符合 keras 的要求 Xtrain = Xtrain.reshape(-1, patch_size, patch_size, pca_components, 1) Xtest = Xtest.reshape(-1, patch_size, patch_size, pca_components, 1) print('before transpose: Xtrain shape: ', Xtrain.shape) print('before transpose: Xtest shape: ', Xtest.shape) # 为了适应 pytorch 结构,数据要做 transpose Xtrain = Xtrain.transpose(0, 4, 3, 1, 2) Xtest = Xtest.transpose(0, 4, 3, 1, 2) print('after transpose: Xtrain shape: ', Xtrain.shape) print('after transpose: Xtest shape: ', Xtest.shape) """ Training dataset""" class TrainDS(torch.utils.data.Dataset): def __init__(self): self.len = Xtrain.shape[0] self.x_data = torch.FloatTensor(Xtrain) self.y_data = torch.LongTensor(ytrain) def __getitem__(self, index): # 根据索引返回数据和对应的标签 return self.x_data[index], self.y_data[index] def __len__(self): # 返回文件数据的数目 return self.len """ Testing dataset""" class TestDS(torch.utils.data.Dataset): def __init__(self): self.len = Xtest.shape[0] self.x_data = torch.FloatTensor(Xtest) self.y_data = torch.LongTensor(ytest) def __getitem__(self, index): # 根据索引返回数据和对应的标签 return self.x_data[index], self.y_data[index] def __len__(self): # 返回文件数据的数目 return self.len # 创建 trainloader 和 testloader trainset = TrainDS() testset = TestDS() train_loader = torch.utils.data.DataLoader(dataset=trainset, batch_size=128, shuffle=True, num_workers=2) test_loader = torch.utils.data.DataLoader(dataset=testset, batch_size=128, shuffle=False, num_workers=2)

训练结果:
测试结果:
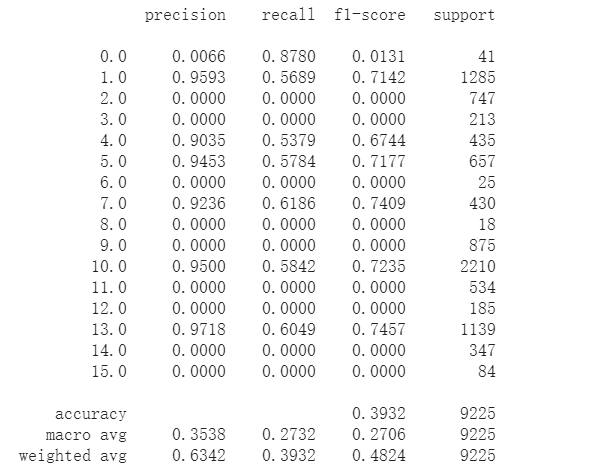
发现我是在fc3的时候复制fc1、fc2的时候复制了dropout,导致最后的结果有丢失,最终的结果如下: