第1章 文件处理
1.1 文件操作
1.1.1 语法
f = open('yesterday','w',encoding='utf-8') #写模式,没有文件的情况下自动创建文件,有该文件的情况下清空该文件的内容,且只能写不可读, f = open('yesterday','r',encoding='utf-8') #读模式,没有文件就报错,只能读文件, f = open('yesterday','a',encoding='utf-8') #追加模式,只能追加,不能读,自动追加在源文件的后面 f = open('yesterday','r+',encoding='utf-8') #读写模式,可读写文件的内容,但是写还是会覆盖原来的内容,没有文件报错 f = open('yesterday','w+',encoding='utf-8') #写读模式,可写读,但是打开文件时,文件的内容会被清空,所以你刚打开就读什么都读不到, f = open('yesterday','rb',encoding='utf-8') #二进制文件的读,网络传输的时候会用,视频文件、音频等, print(f.readline()) f.write('我爱中国。。。') f.readline() f.readlines() f.flush() #将在内存中的数据写到磁盘中,内存的缓存机制 f.detach() #不常用,没人知道怎么用,用了可能会报错 f.fileno() #返回操作系统在内存中的编号(可以理解成:操作系统中有很多爪子,用来抓取文件的,这时候是打印那个爪子) f.tell() #在屏幕上输出打印出光标的位置 f.seek() #将光标定位到具体的位置 f.seekable() #判断文件是否可以移,比如.tty文件是不能移的 f.truncate() #截断,从头开始截! f.close() f.encoding() #打印文件输出的编码格式
1.1.2 Linux下打印进度条的小程序
import sys,time for i in range(20): #主要理解f.flush的方法,和系统的存储机制, sys.stdout.write("#") sys.stdout.flush() time.sleep(0.5)
#系统是当缓存到达某个固定值之后才开始将内存中的数据写到磁盘中。
1.1.3 替换文本中的某些字
要把《yesterday when i was young》歌词放到suchagal1文件中
f = open('suchagal','r',encoding='utf-8') f_new = open('suchagal2','w',encoding='utf-8') for line in f: if '说这辈子我干什么都可以' in line: line = line.replace('说这辈子我干什么都可以','说这辈子我不仅要能明辨是非而且事业有成') f_new.write(line) f.close() f_new.close()
1.1.4 With语句
With open('suchagal','r',encoding='utf-8') as f,open('suchagal2','r',encoding='utf-8') as f2: Print(f.readline())
在语句执行完成后自动的去关闭这个文件。同时打开两个文件
1.2 编码转换
要想把utf-8转换成gbk,就要先把utf-8转换为unicode,在编码成gbk。这就是转码应用场景。
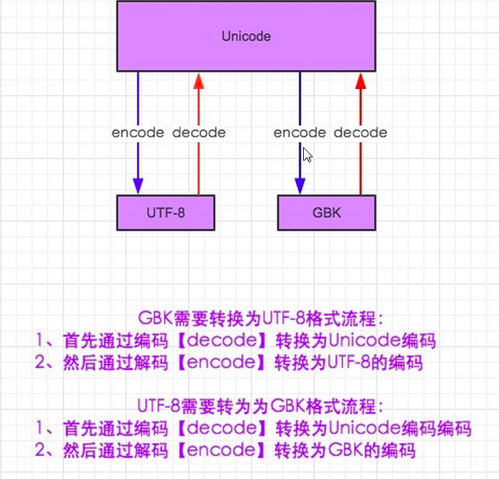
(截图来自Alex li )
如上图所示,这个只是文件的编码格式,而不是你创建的pyfile中的字符串的格式,在python2.x中默认是GBK;在python3.x中默认是unicode格式,所以在转码的时候就不需要转成unicode的了。
1.3 函数
1.3.1 函数的定义
def xuwei(x,*args): #*s是预留出的参数接口,为以后的业务扩展用的 print(x) print(args) return 0 xuwei(1,*[2,3]) ·*args试试固定格式,其他的骚操作都不要有。 def sugar(name,age=18,**kwargs): print(name) print(age) print(kwargs) return 0 sugar('xuwei',23,sex='m',hobby='python') ·**kwargs试试固定格式,其他的骚操作都不要有。 def suchagal(name,age=18,*args,**kwargs): print(name) print(age) print(args) print(kwargs) return 0 suchagal('xuwei',23,2,3,4,sex='m',hobby='python')
1.3.2 全局变量和局部变量
s = 'i love you' def func(): global s s = 'xuwei' print(s) return 0 print('before',s) func() print('behind',s)
通过global来在局部函数中改全局变量,局部变量在全局的环境中是无法调用的,所以只有global之后才可以调用。(这个方法千万不要用!)
但是,除了数字和字符串不可以改,其他的数据类型是可以改的,比如:列表,字典,类。
1.3.3 递归函数
1.3.4 递归的特性
1、必须有一个明确的结束条件
2、每次进入更深一层时,问题规模相比上次递归都应有减少
3、递归效率不高,递归层次过多回到子栈溢出(在计算机中中,函数调用时通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层帧栈。由于栈的大小不是无线的,所以递归调用的次数过多,会导致栈溢出)如下的函数就是符合递归的特性:
def calc(n): print(n) if int(n/2) >0: return calc(int(n/2)) print("->",n) calc(16)
1.3.5 高阶函数
函数可以接收变量的类型:数值,字符串,函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数为参数这种函数就称为高阶函数。如下例子:
def add(a,b,f): return f(a)+f(b) res = add(2,-4,abs) print(res) #abs是一额绝对值函数,就是将输入的参数全部绝对值。
小插曲:eval()
这个函数可以将字符串转成字典。举个例子
b = '''{'name':'xuwei','age':18,'other':{'hobby':'python'}}''' print(b) eval(b) print(b)
就是相当于去掉额注释。
The reason why a great man is great is that he resolves to be a great man.