实现前端录音,将音频blob传给服务器,然后在服务器端使用百度AI语音识别将结果返回给前端
上一篇文章是将百度AI语音识别Nodejs SDK版的进行了一遍演示加识别结果返回给前端显示,这里是完整的进行前端录音,然后将压缩后的音频对象Blob传给服务器,在服务端使用百度AI语音识别,最后将识别结果返回给前端进行显示。
本篇调用的是第三方库Recorder.js,如何调用该库捕获HTML5中的WAV音频并将其上传到服务器或者本地下载,可以查看这篇博客,不过它讲解的是上传到PHP服务端,这里我改成了基于Node搭建的Websocket服务器。
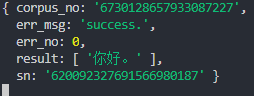
这是本篇博客的语音识别结果: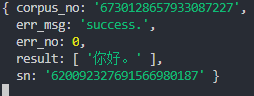
查看文档知道了我想要的信息,如果想要实现实时语音识别、长时间段的语音、唤醒词功能、语义解析功能,需要使用Android、IOS SDK或者Linux C++ SDK版本,而我使用的Nodejs SDK是不支持的。
-
语音时长上线为60s,超出讲返回错误
-
原始录音文件为
pcm、wav或者amr格式,不区分大小写,推荐使用pcm -
录音采样率为16000,声道为单通道
-
支持普通话、英文、粤语、四川话
-
项目结构
调用百度AI平台语音识别的
Nodejs SDK,查看文档快速入门,可以查看如何调用。首先将nodejs-sdk下载下来,下载后将目录里的
speech文件夹拷贝到你的项目文件夹中,其中assets是存放录音音频的地方,然后进入node文件夹下的位置进行安装依赖包:npm install我的项目文件夹目录如下:
audio_asr_baidu ├─ package-lock.json └─ speech ├─ .gitignore ├─ assets │ ├─ 16k_test.pcm │ └─ recorder.wav ├─ cpp │ ├─ .gitignore │ ├─ README.md │ ├─ build.sh │ └─ main.cpp └─ node ├─ .gitignore ├─ README.md ├─ index.html ├─ main.js ├─ node_modules ├─ package-lock.json ├─ package.json └─ style.css
然后在
node文件夹里的index.html是我的客户端文件,main.js是我的服务端文件。
在main.js文件里搭建websocket服务器,首先安装相关依赖模块:
npm i ws -S
然后搭建:
let Server = require('ws').Server;
const wss = new Server({
port: 9001
})
// 连接服务器
wss.on('connection', ws => {
console.log('server connected');
})
ws.on('error', error => {
console.log('Error:' + error);
})
ws.on('close', () => {
console.log('Websocket is closed');
})
})
// 断开连接
wss.on('disconnection', ws => {
ws.on('message', msg => {
console.log('server recived msg:' + msg);
})
})
然后在index.html中:
let ws = new WebSocket('ws://localhost:9001'); ws.onopen = e => { console.log('Connection to server opened'); }
启动服务:
node main.js
就可以在控制台看见这样的打印信息:
// 客户端的打印信息: Connection to server opened // 服务端的打印信息: server connected
客户端实现录音之后,将压缩后的音频对象Blob传给服务器:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Simple Recorder.js demo with record, stop and pause</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" type="text/css" href="style.css">
</head>
<body>
<div id="controls">
<button id="recordButton">Record</button>
<button id="stopButton" disabled>Stop</button>
</div>
<p id="out-txt">You said:</p>
<h3>Recordings</h3>
<ol id="recordingsList"></ol>
<script src="https://cdn.rawgit.com/mattdiamond/Recorderjs/08e7abd9/dist/recorder.js"></script>
//连接服务器
let ws = new WebSocket('ws://localhost:9001');
ws.onopen = e => {
console.log('Connection to server opened');
}
URL = window.URL || window.webkitURL;
var gumStream; //stream from getUserMedia()
var rec; //Recorder.js object
var input; //MediaStreamAudioSourceNode
var AudioContext = window.AudioContext || window.webkitAudioContext;
var audioContext
var recordButton = document.getElementById("recordButton");
var stopButton = document.getElementById("stopButton");
recordButton.addEventListener("click", startRecording);
stopButton.addEventListener("click", stopRecording);
// 录音
function startRecording() {
console.log("recordButton clicked");
var constraints = {
audio: true,
video: false
}
recordButton.disabled = true;
stopButton.disabled = false;
// 获取录音权限 然后开始录音
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
console.log("getUserMedia() success, stream created, initializing Recorder.js ...");
audioContext = new AudioContext();
gumStream = stream;
input = audioContext.createMediaStreamSource(stream);
rec = new Recorder(input, {
numChannels: 1 // 单声道
})
//开始录音
rec.record()
console.log("Recording started");
}).catch(function(err) {
recordButton.disabled = false;
stopButton.disabled = true;
});
}
// 停止录音
function stopRecording() {
console.log("stopButton clicked");
stopButton.disabled = true;
recordButton.disabled = false;
rec.stop();
gumStream.getAudioTracks()[0].stop();
// 创建一个blob对象让它以wav格式下载
rec.exportWAV(createDownloadLink);
}
// 接收服务端发的消息
ws.onmessage = e => {
console.log(e.data);
setTimeout(() => {
document.getElementById("out-txt").innerHTML += e.data
}, 3000);
}
// 创建下载链接
function createDownloadLink(blob) {
console.log(blob);
ws.send(blob);
var url = URL.createObjectURL(blob);
var au = document.createElement('audio');
var li = document.createElement('li');
var link = document.createElement('a');
var filename = new Date().toISOString();
au.controls = true;
au.src = url;
link.href = url;
link.download = filename + ".wav";
link.innerHTML = "Save to disk";
li.appendChild(au);
li.appendChild(document.createTextNode(filename + ".wav "))
li.appendChild(link);
}
这样,在该页面会创建下载连接,并以录音日期为文件名,可以选择下载,同时也会将音频对象传到服务器。
因为前端通过音频流文件上传到后台后,不再是保存为wav格式的音频,而是处理流的形式转为二进制数组,直接调用百度语音识别SDK方法,即可返回识别结果,不必编码后发给后端,后端然后再解码。
let AipSpeech = require("baidu-aip-sdk").speech;
let fs = require('fs');
let Server = require('ws').Server;
const wss = new Server({
port: 9001
})
let resTxt;
wss.on('connection', ws => {
console.log('server connected');
const transTxt = (resTxt) => {
ws.send(resTxt);
}
ws.on('message', data => {
console.log('server recived audio blob');
// 务必替换百度云控制台中新建百度语音应用的 Api Key 和 Secret Key
let client = new AipSpeech(0, 'Api Key', 'Secret Key');
let voiceBase64 = new Buffer(data);
client.recognize(voiceBase64, 'wav', 16000).then(function(result) {
console.log('语音识别本地音频文件结果: ' + JSON.stringify(result));
resTxt = JSON.parse(JSON.stringify(result));
// 将结果传给前端
transTxt(resTxt);
}, function(err) {
console.log(err);
});
})
ws.on('error', error => {
console.log('Error:' + error);
})
ws.on('close', () => {
console.log('Websocket is closed');
})
})
wss.on('disconnection', ws => {
ws.on('message', msg => {
console.log('server recived msg:' + msg);
})
})
这是前端说话录音传给后台语音识别的结果,将结果使用websocket传给前端,显示在标签内就可以了: