https://www.v2ex.com/t/749062
https://www.v2ex.com/t/749215
比如每个物品订单有支付和未支付两种状态。那么如何统计一个物品最新的连续未支付状态的订单数呢?数据库结构如下
| id | goodid | ordertype |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 1 | 1 |
| 3 | 2 | 1 |
| 4 | 2 | 0 |
| 5 | 2 | 0 |
| 6 | 2 | 1 |
| 7 | 2 | 0 |
| 8 | 3 | 0 |
| 9 | 3 | 0 |
id是自增主键,goodid是物品的id,ordertype是订单状态,1表示支付,0表示未支付
比如我们统计物品1,最新的连续未支付的订单数
select count(*) from tablename where goodid=1 and id > IFNULL((select id from tablename where goodid=1 and ordertype = 1 order by id desc limit 1), 0)
输出结果是0,是对的。
上面的思路就是,先找到最新的一个成功订单的id;再查找商品是1,并且id大于上面成功id的所有订单;最后统计个数。
其中的语句IFNULL是用来判断,第一个表达式如果是NULL,那么就输出第二个表达式的值。加这个是因为,如果商品从来没有付过款,那么查出来是NULL,id大于的地方判断就会失效,导致统计出来是0。比如goodid是1的时候,子查询输出的结果是2,是正确的,最后一个成功订单id是2,大于2的订单没有,所以是0。如果goodid是2,输出结果是6,大于6的有一个,所以统计结果是1。如果goodid是3,因为没查到对应结果,所以是NULL,那么通过IFNULL设置为0,所以所有goodid是3的订单都是未完成的,有两个。
IFNULL里面就是统计物品最后一次成功的订单id。
如果说要统计所有物品的最新未支付的订单数呢?这样的话,比上面少了一个条件,语句如下
select t1.goodid, count(if(t1.ordertype = 0, 1, null)) as ret
from tablename as t1
left join tablename as t2 on t2.goodid= t1.goodid and t2.ordertype = 1 and t2.id > t1.id
where t2.id is null
group by t1.goodid
上面语句的思路是,先按照条件连接,然后根据连接后的条件判断个数。
连接内部on的条件是,首先是同一个物品的内容(这个是肯定的);然后查找所有t2是成功订单的内容(这里与上面思路一样,就是查找最后一个成功订单的id,比这个id大的所有订单,就是满足条件的订单,统计个数就可以了),再查找所有t2 id比t1 id大的内容,这里与上面的条件一样。连接就是左边的每一条内容与右边每一条内容对应,产生一个虚拟的表,因为是左连接,所以以左边的表为主,就是左边表中的内容肯定会全部出现(这也是理所当然的,因为不管有没有连续未支付的订单,都需要统计出来,并且这里也是配合后面的内容使用的),按照上面的思路,在左边,最后一个成功的订单结果会怎么样?因为是最后一个成功的订单,所以t2.id > t1.id是不成立的,所以呢,右边t2对应的内容是NULL。那所有左边,大于最后一条成功订单的内容对应结果呢?也是不满足t2.id > t1.id。所以从左边最后一条成功订单开始,在右边都找不到对应的内容,那么右边的内容就是NULL,并且左边的每一条记录都只会出现一次,因为右边没对应记录,也就不会多次对应。
连接的统计结果如下
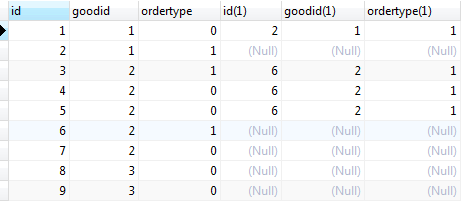
连接后面加了一个where,我们知道连接中间用on进行过滤连接的条件,得到虚拟表后,可以再用where过滤其他条件,按照上面分析,t2是NULL的才是我们关心的内容,所以用t2.id is null过滤出我们想要的内容,再通过group按照物品分组,最后通过count if过滤掉最后一个成功订单产生的记录。使用count if是因为最后一条成功的订单也满足我们连接内部的条件,所以需要去掉,并且这一条记录必须有,如果在连接中用t2.id >= t1.id,那么就会出现有的没有统计,比如物品1,因为最后一条记录也满足了,所以物品1的t2对应的表内容都是有的。