第一部分:
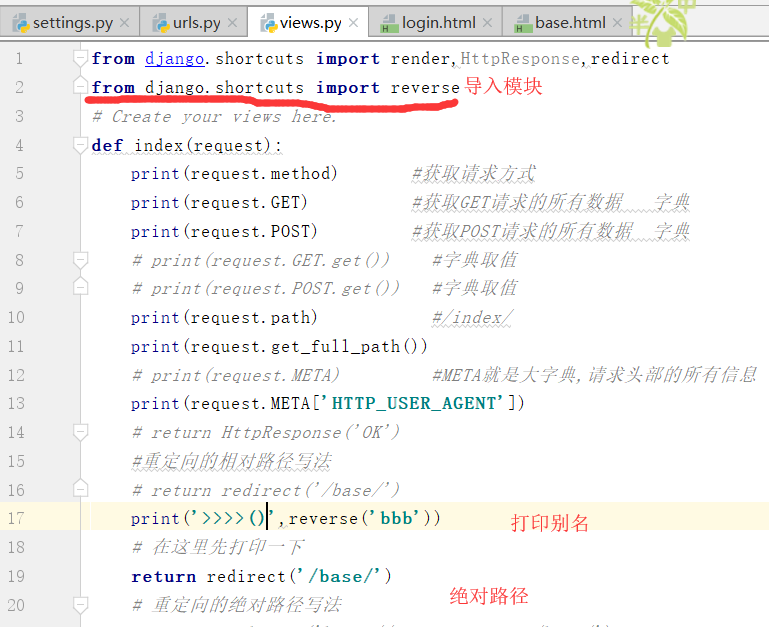
1.(1)知识点回顾:


django回顾: (1)下载安装 输入网址,a,form表单get post,爬虫 (请求)==>django项目服务端的url(r"index/",views.index,), 先匹配,再加工成httprequest对象,再给views.index (响应)==>def index(request): return Httpresponse('hello') return render(request,'index.html',{'name':'xxx'}) #字符串替换 return redirect('/login/') #redirect最终也是httpresponse,响应行+状态码是30X #相对路径就是自己的项目的路径,ip+端口 ==>这里边有三个对象:Httpresponse(字符串),render(返回页面),redirect(重定向) //(render&&request都可以用) ==>def login(request): return Httpresponse('hello') return render(request,'login.html')#django觉得你会用到login.html return redirect('/login/') #只是返回一次 network是用来监听网络请求和响应信息的 重定向,就是两次请求,两次响应.
(2).重定向只是返回一个url
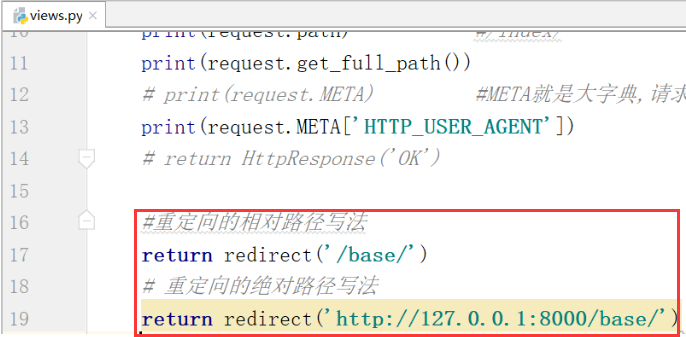
重定向,接收到了这个request东西,但是没有用request.

render中request会用到,也是接收到了request.看着没有用实际上用到了,用到了再说.
不要看源码,源码的难度太高.(各种调用,各种多重继承,继承的规则编程MRO了)
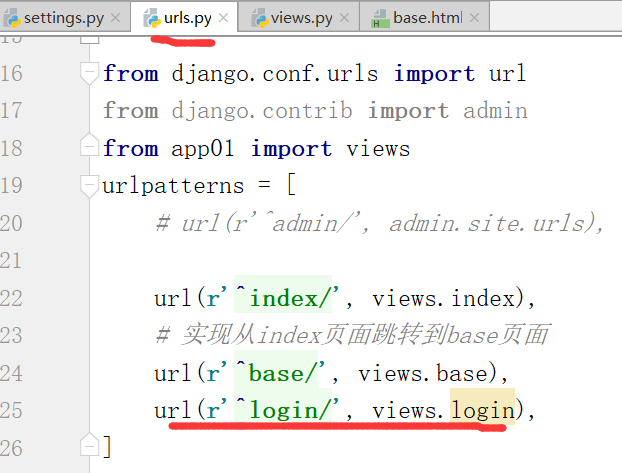
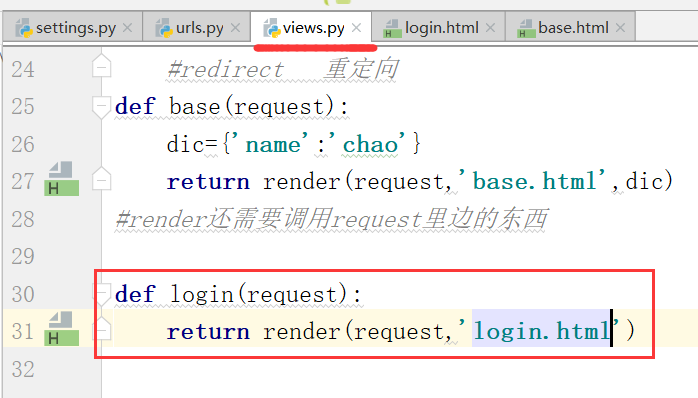
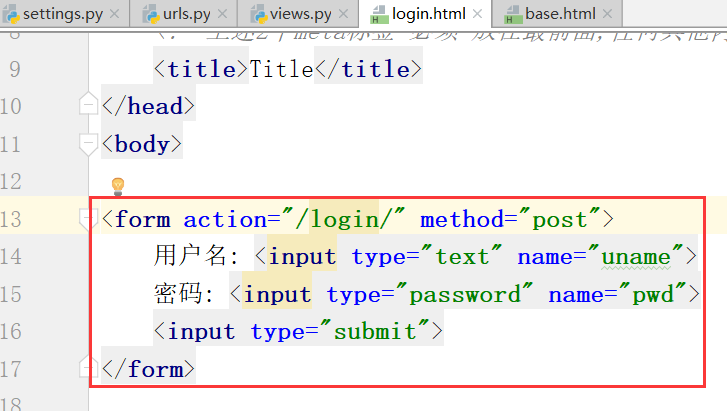
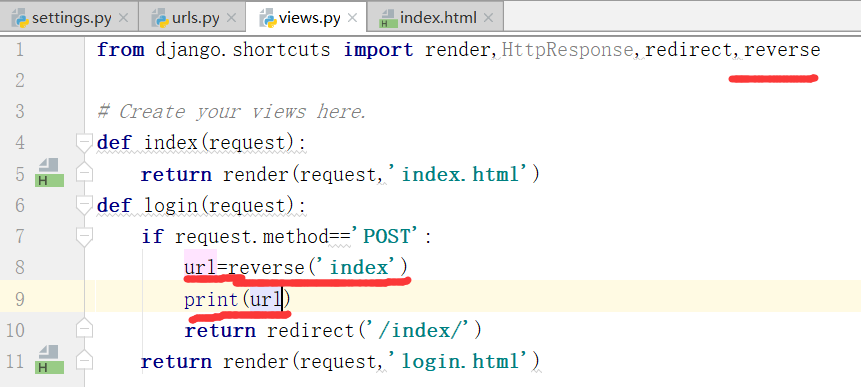
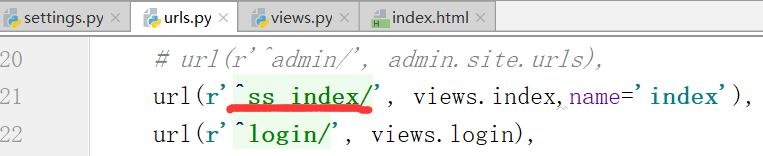
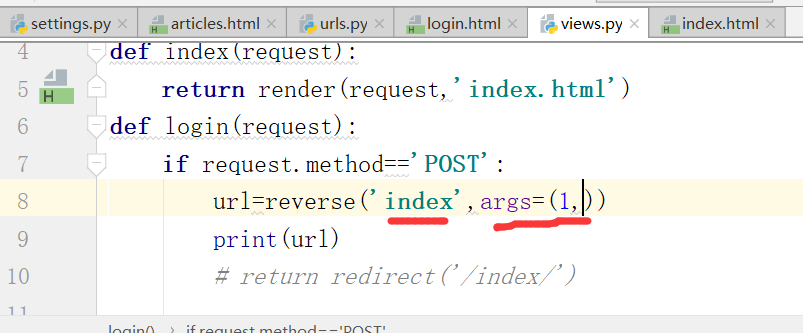
这个地方硬编码写死了action='/login/'
运行结果:

1.url反向解析图解
起别名
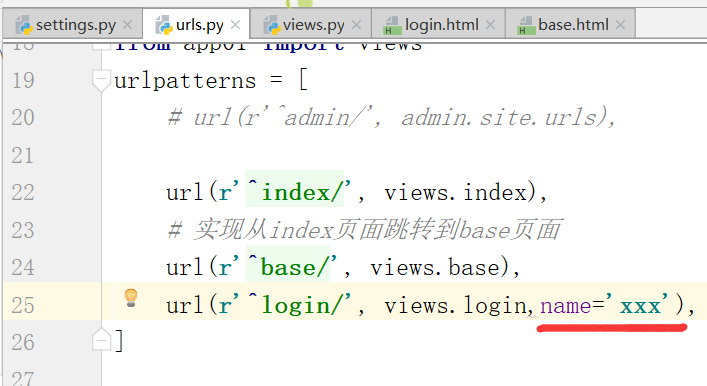
我们将上边的内容起了一个别名.
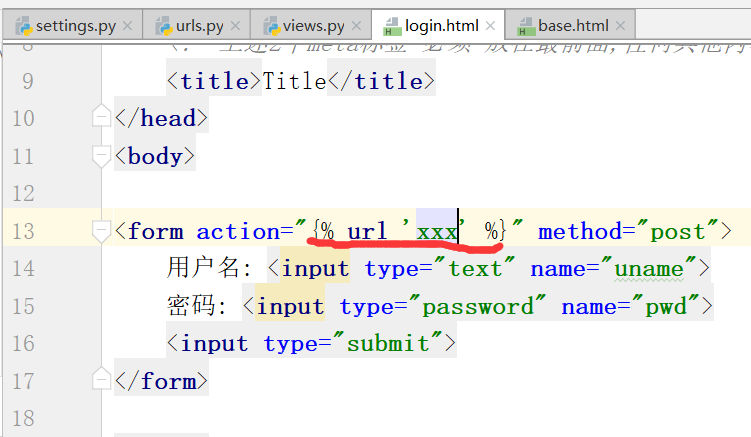
通过模板渲染写,得到结果:
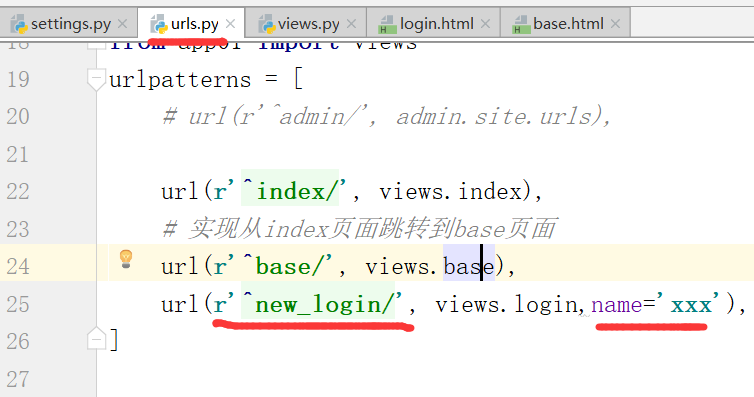

#修改urls.py文件

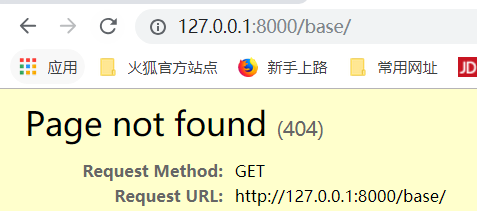
输入地址:
回车:(这时候我们找不到页面了)
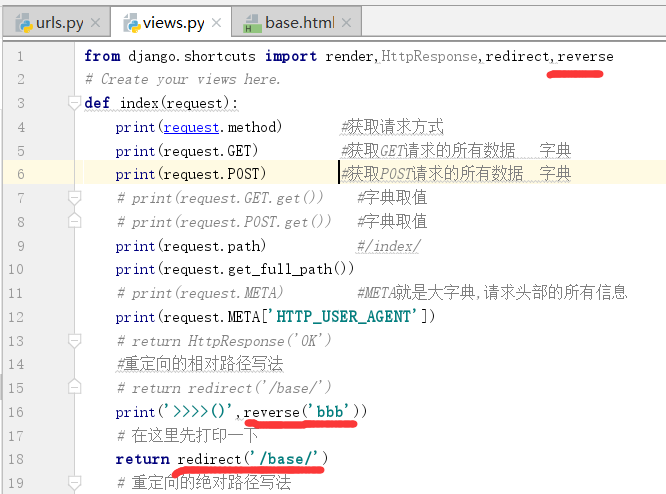
输入下面的地址就可以得到结果了,这是因为写死了这个页面,因此,我们可以在视图这里也进行反向解析
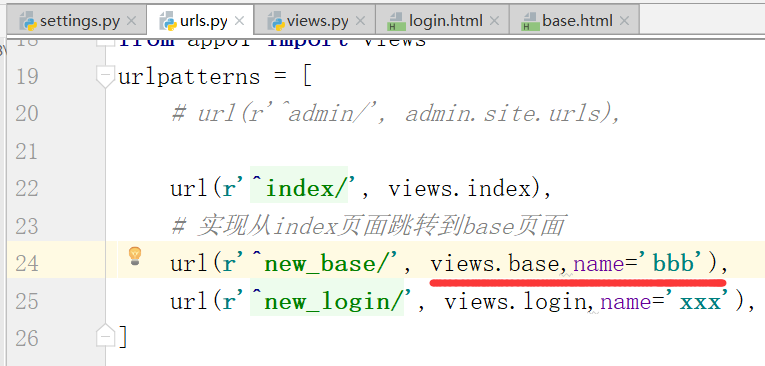
起别名:
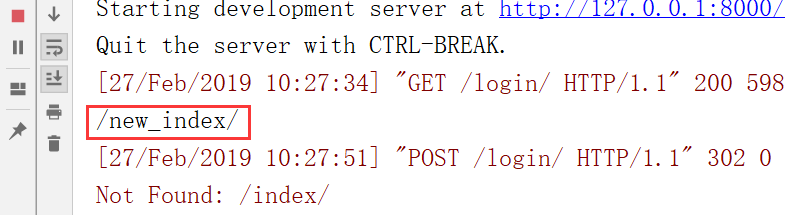
运行:(跳转之后打印的,浏览器现在的结果无所谓)
服务端打印的结果,转换成这个路径了.也就是翻转路径了
![]()
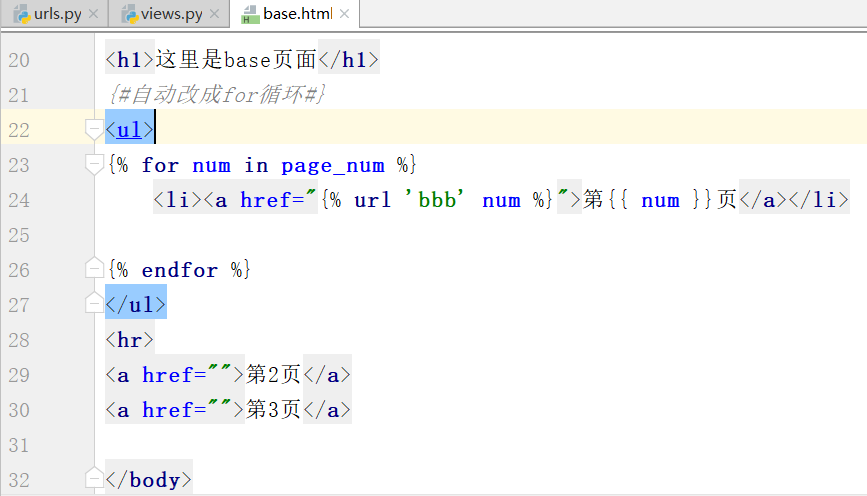
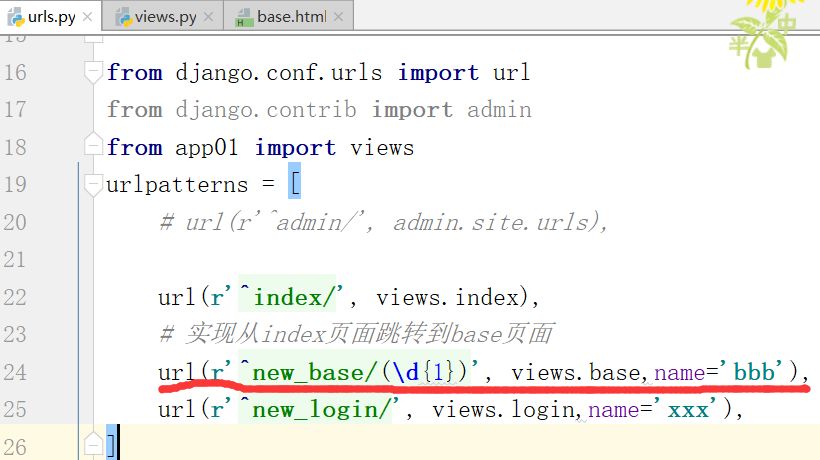
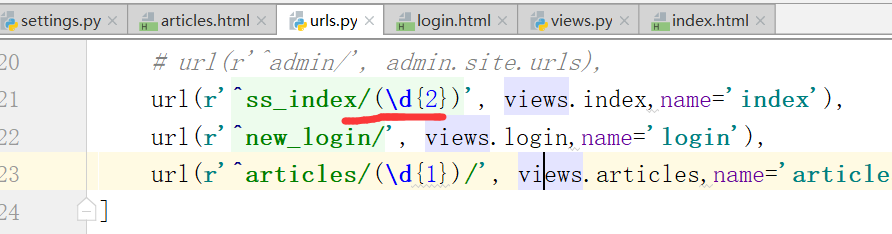
路径分组,匹配两个数字,

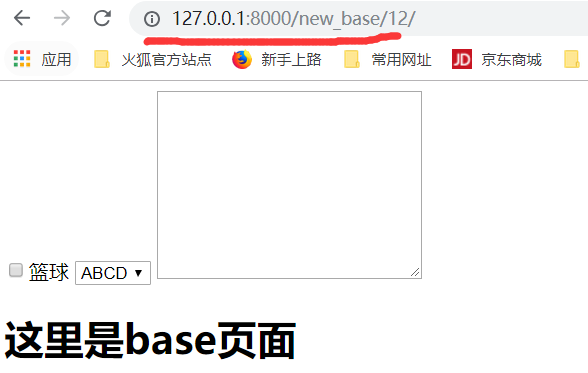
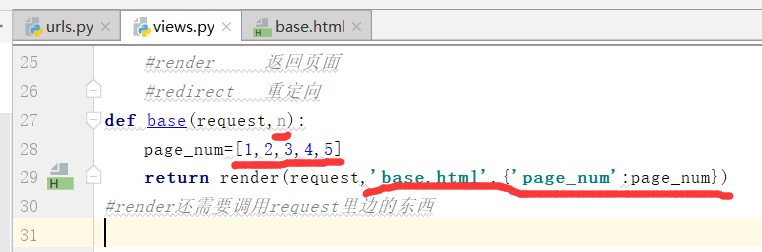
通过路径/new_base/,找到函数,需要添加一个参数,获取参数n,起别名'bbb'
运行结果如下:
运行结果:

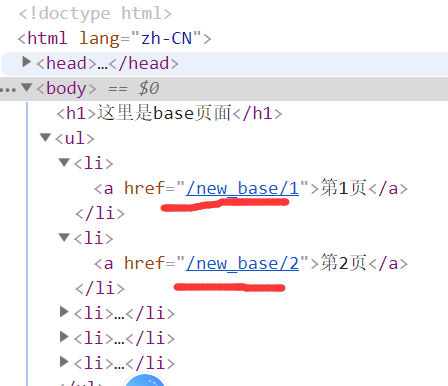

反向解析跳转的路径:

将上边的args中的参数1,改成参数2

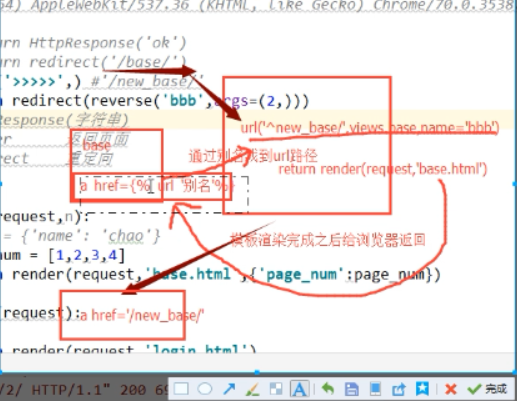
反向解析补充

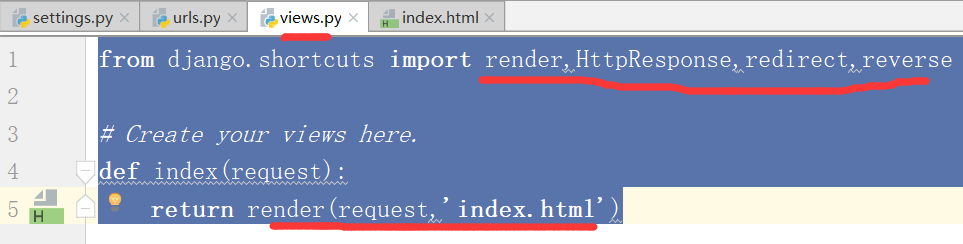
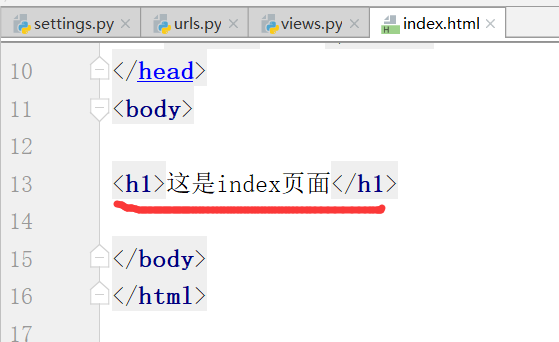
运行,得到结果:
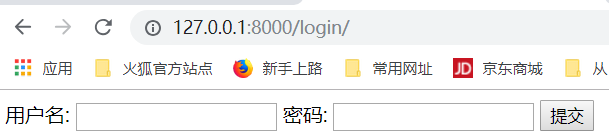
添加login页面和函数
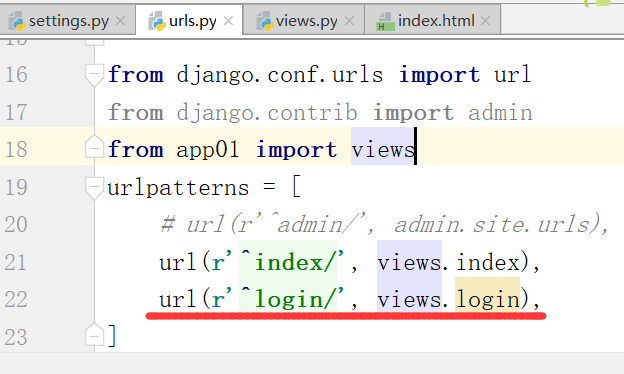
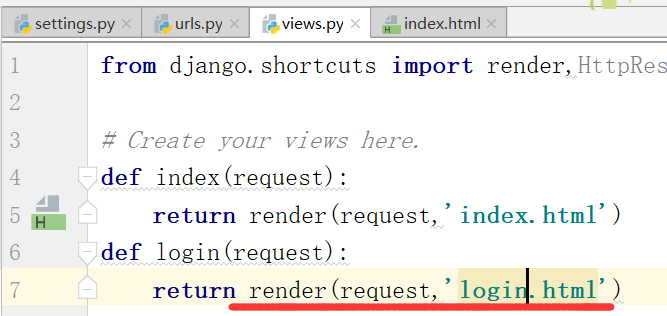
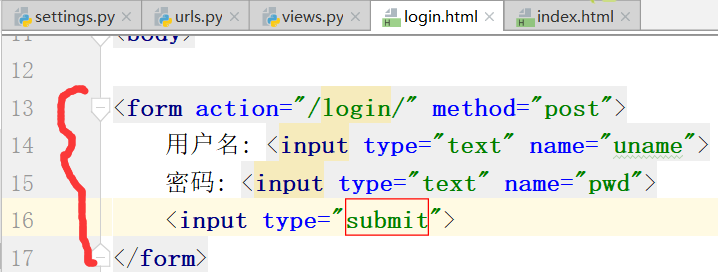
运行,得到如下结果:
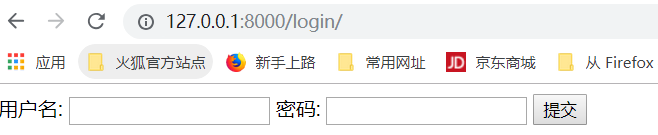
随便输入,用户名和密码,报错
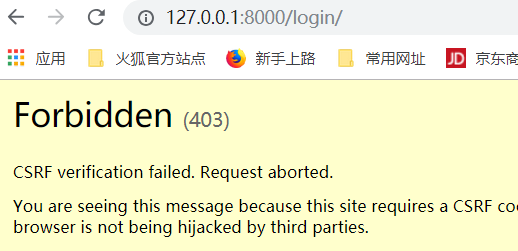
中间件,禁止访问.,需要将中间件的第四个注销掉.
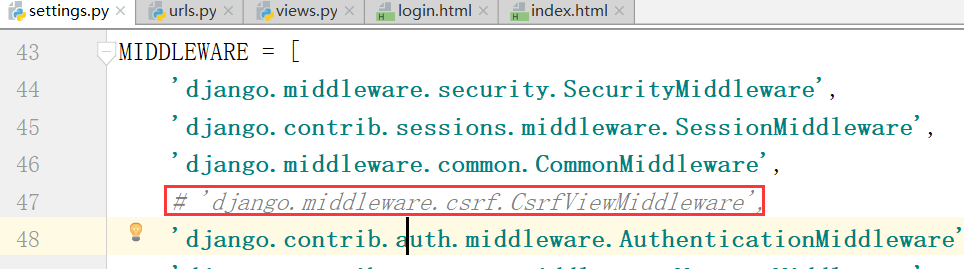
这样,再运行,随便输入用户和密码,结果又返回这个页面:
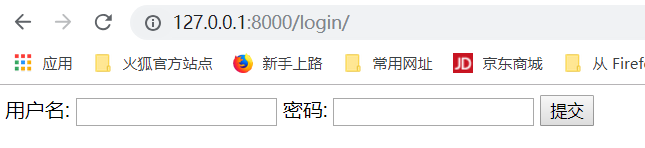
从login.html中,我们知道这是一个post提交方式:
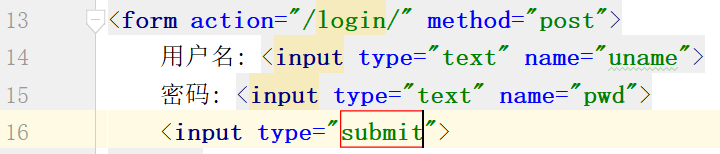
修改,第一次请求的目的是login页面,第二次请求到index页面
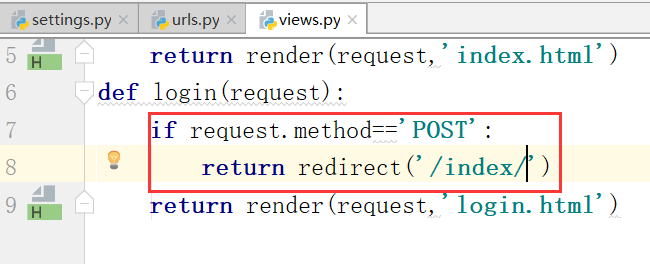
运行,
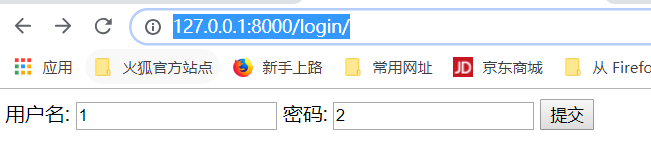
输入用户和密码,回车,得到下面的结果:
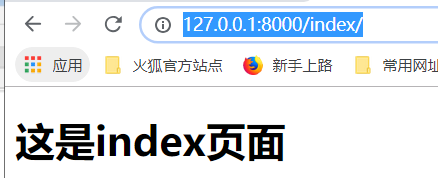
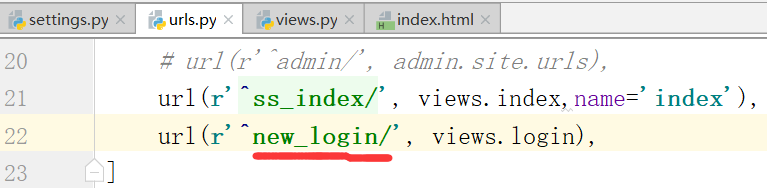
在urls.py中,修改名字为如下:

运行,
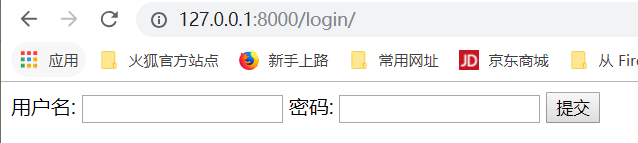
随便,输入用户和密码:这时候跳转不到下一个界面了,这时候我们需要修改别名
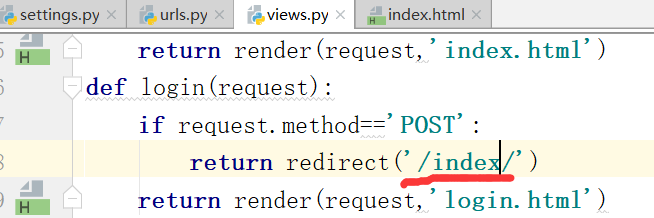
这就是硬编码的缺点,在修改urls.py文件中的路径的同时,还需要修改views.py文件里的路径,这就是写死了
django提供了一个反向解析的功能,也就是起别名.
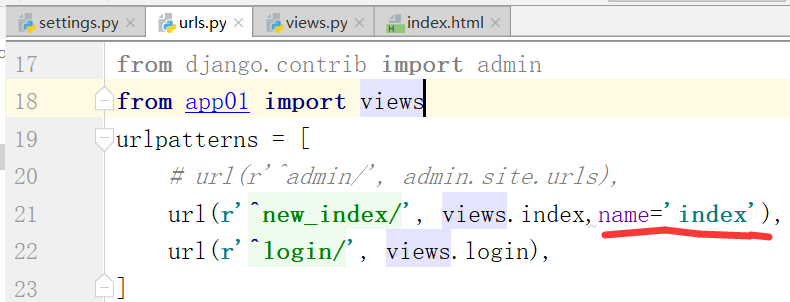
测试打印出来的url
运行
结果:

服务端得到的结果,也就是起的别名,通过别名知道修改之后的路径/new_index/
修改:

运行:
随便输入地址和密码:提交得到如下结果
服务端得到反向解析得到的路径

修改如下:

我们只需要修改,将url放在反向解析的地址里就可以在剾解析了
运行:
随便输入用户名和密码,提交得到结果:
修改:
运行:
随便输入用户和密码,

这就是通过动态解析,拿到的url
运行:登录函数发生了变化:显示下面的跳转函数没有变化

输入用户和密码,提交,找不到url,
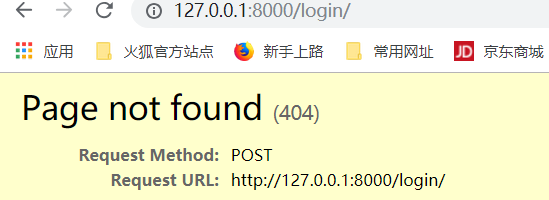
因此,我们需要起别名,给new_login地址,起login别名
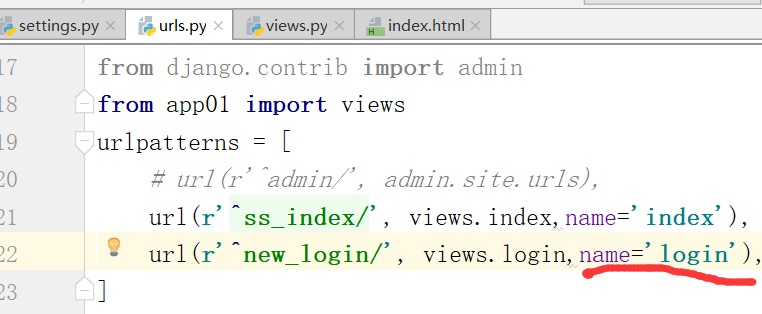
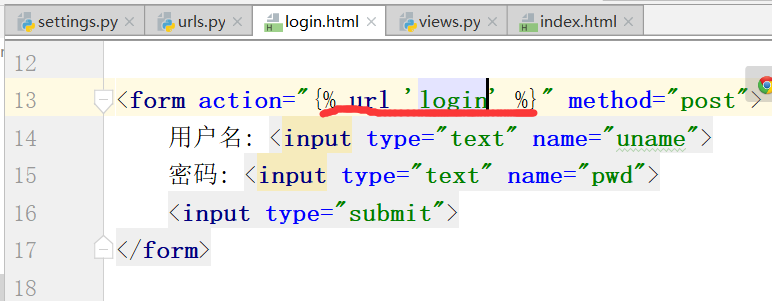
运行,输入地址,这样就得到了下面这个页面.下面的表单名字也自动发生了变化.
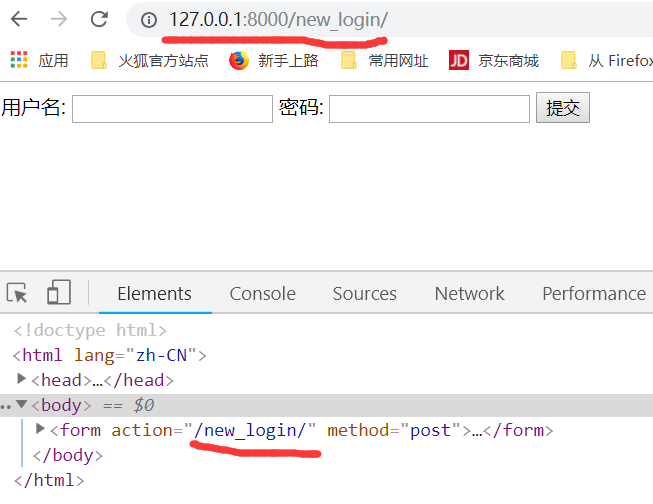
只需要修改正则匹配的路径一个就可以了,输入网址也需要和修改的正则一致.
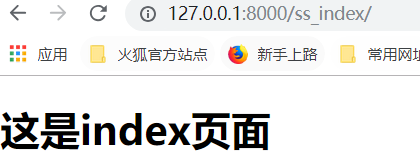
需求:访问index,列举出有几页文章.
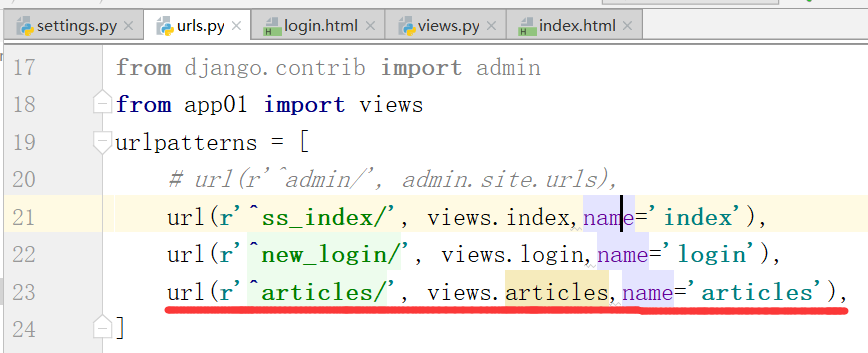

在上边的index.html页面一点击,第n页,就会访问articles的各个文章,走urls.py里的文章对应关系路径
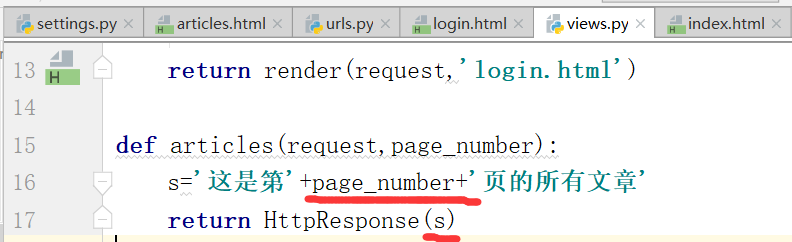
然后在views.py所有页面的文章.返回所有文章
新建articles.html文章
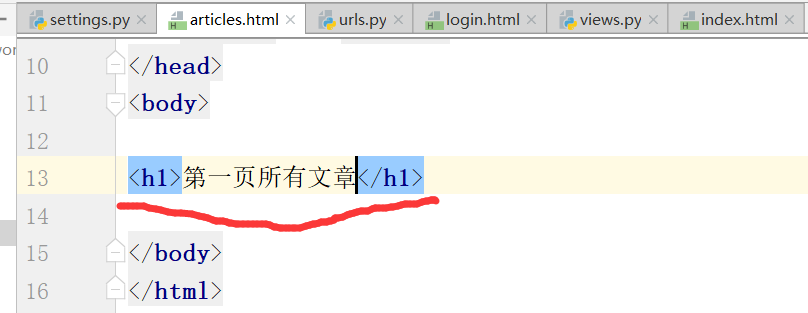
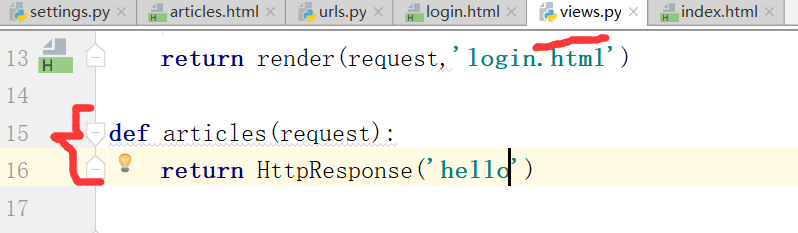
再找url的别名,通过index页面
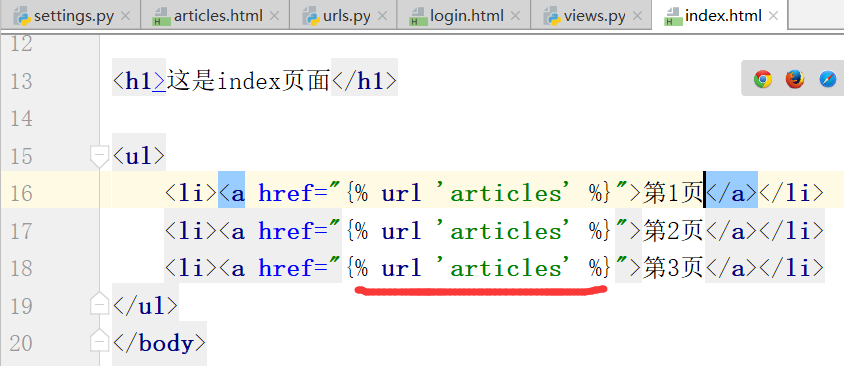
运行,反向解析的页面.

点击第123页都是'hello'
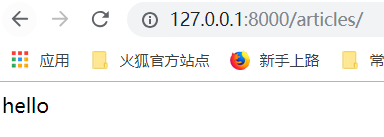
需求,点击第1页,显示第1页内容,点击第2页,显示第2页内容
思考,如何区分?
通过urls.py访问参数进行区分
运行结果:

需求,如何区分第几页所有的文章,应该作为一个参数??通过传参
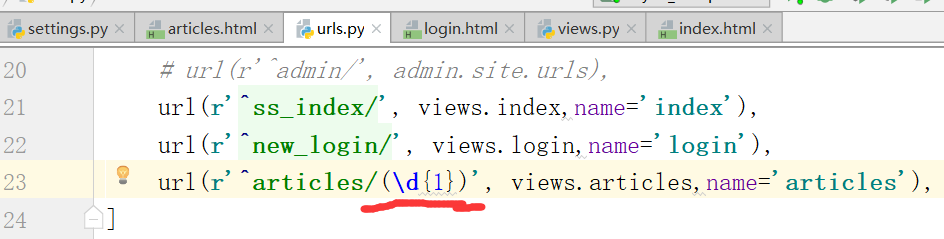
通过page_number进行返回文章.
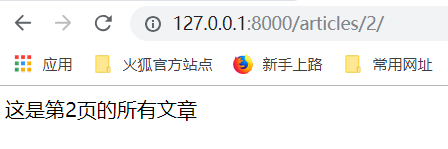
运行得到的结果:
目前的问题,不是输入网址,而是变成点击事件,

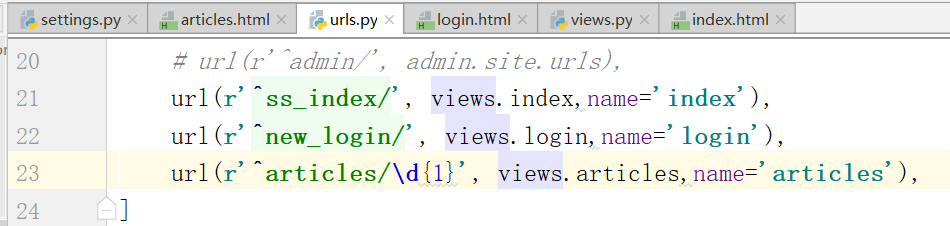
报错.通过urls.py里的 ^articles/(d{1}),找到所有文章,这时候,index.html少东西,也就是少参数,不知道参数到底是什么
(d{1})也就是传递给函数的参数,这个也就是动态参数
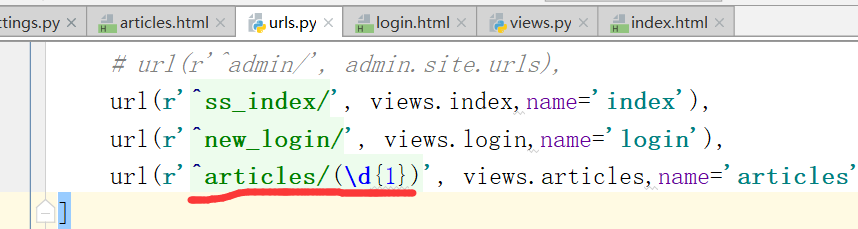
反向解析,通过下面的形式给参数.
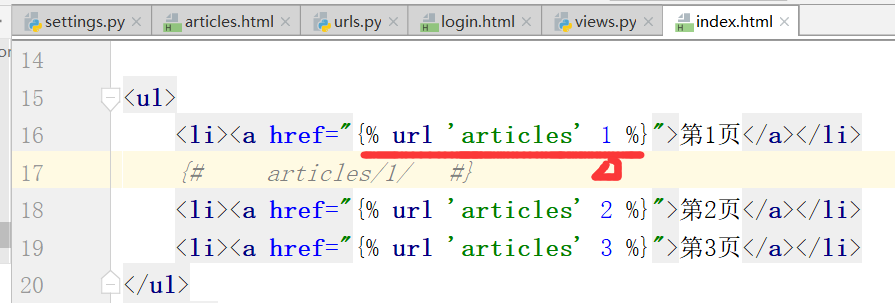
运行:
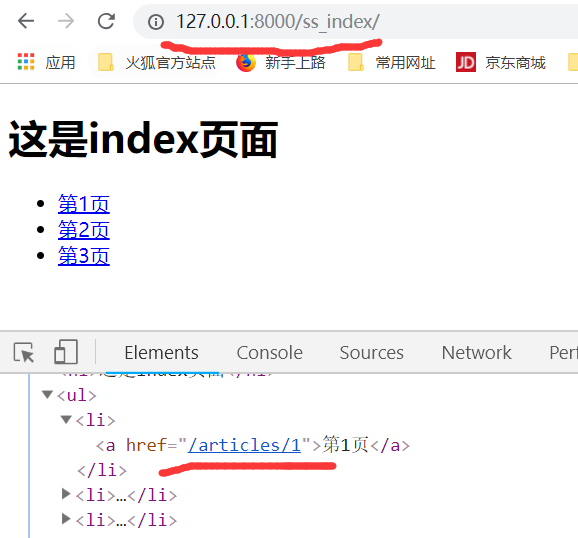
点击第一页,进入
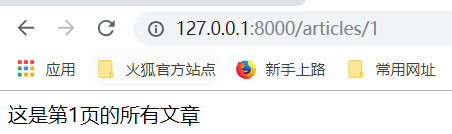
视图函数传递参数:(相当于拼到自己的路径去)
一定要集中注意力,连贯性很重要.!!!
上边整个是视图函数里的反向解析.下面是HTML里的反向解析
c
2.模板渲染
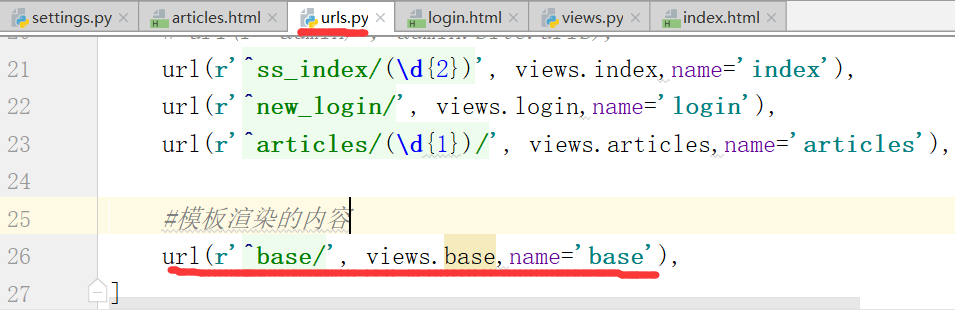
通过访问base,返回一个页面
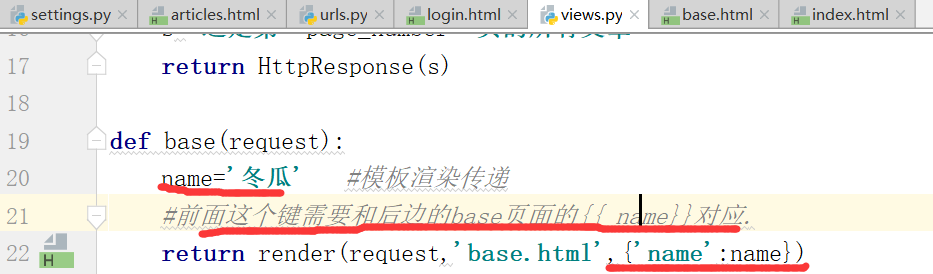
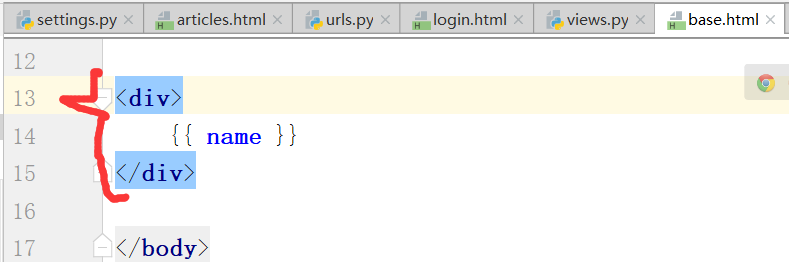
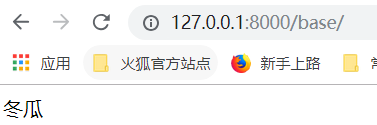
运行结果:
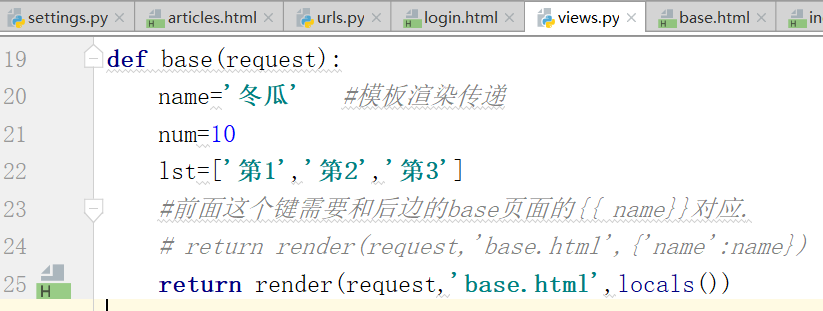
locals()是将函数内的所有的变量,作为键值对进行传递.只是测试写,不是建议的方法,查找的东西太多
一堆变量,导致效率低

运行,得到结果:
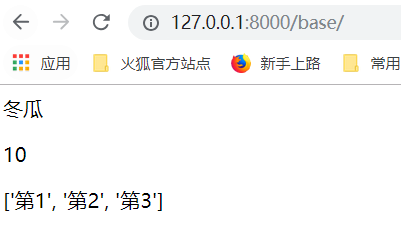
思考,怎样将lst一个一个拿出来??
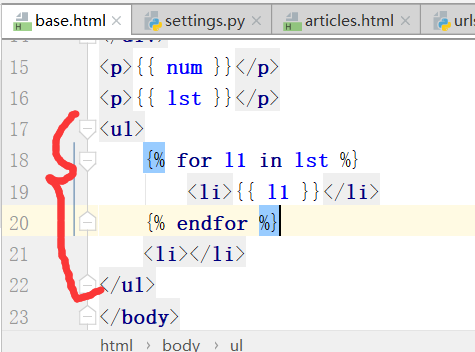
运行,循环,得到的结果?
最后有个小点,原因是for循环,后边有个<li></li>标签.
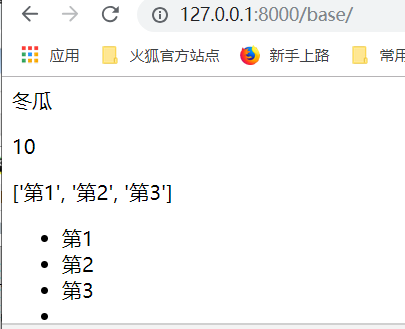
需求:思考怎样拿到类变量???
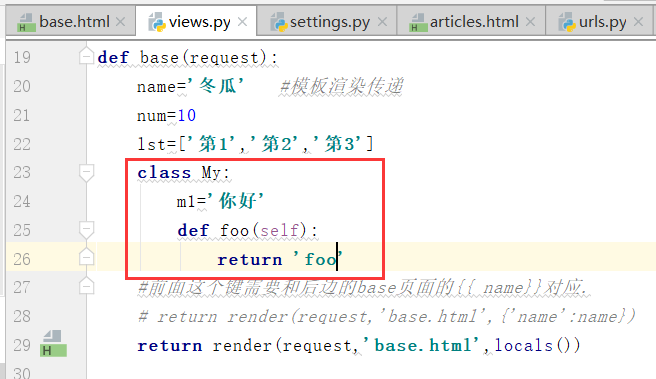
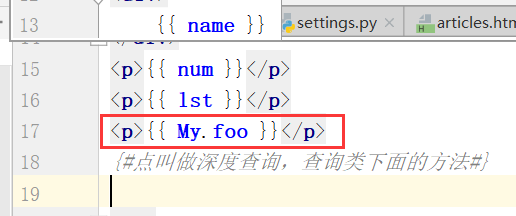
运行:
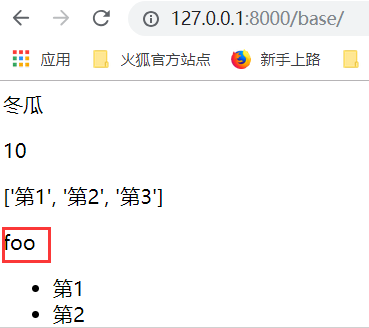
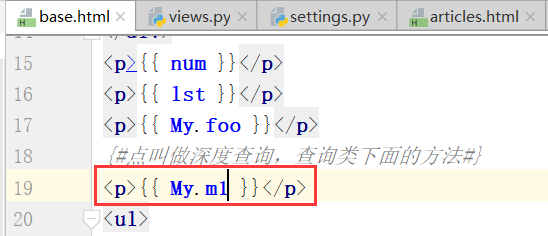
运行:
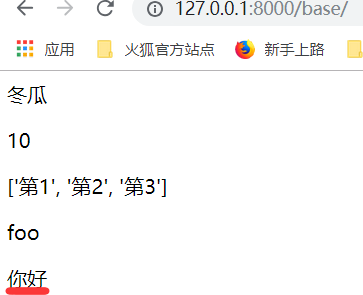
等价于下面的字典方式.

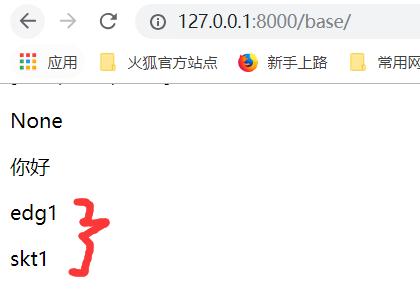
如果不写返回值,只写print
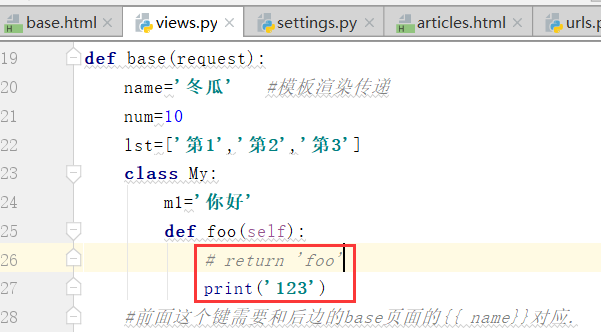
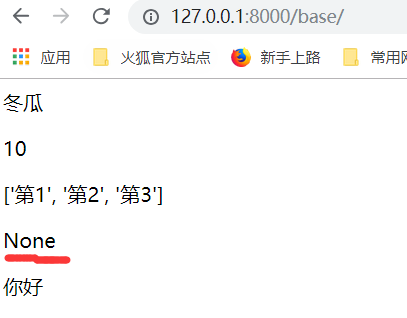
运行:没有返回值,类里边的函数得到的结果就是None.
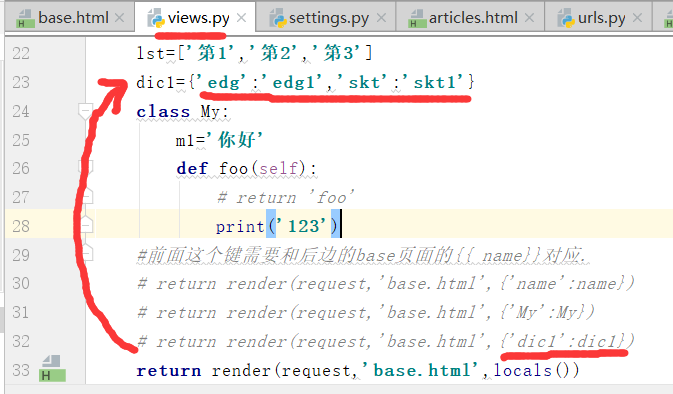
字典里面的s1值.
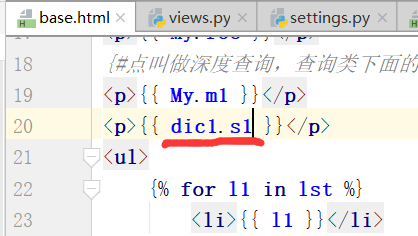

运行:得到的结果如下:

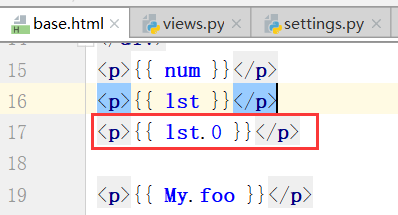
查找列表中的第几个值.
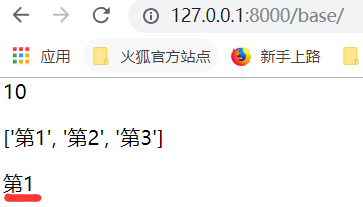
python中实例化,调用类里的方法,写法如下
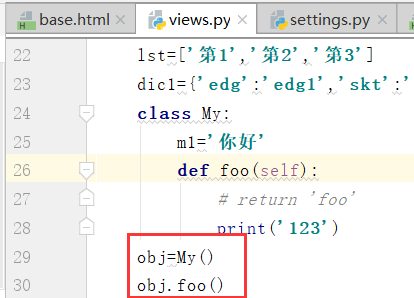
base.html中的类调用方法,类调用变量,都是没有括号的,那么怎样传递参数.
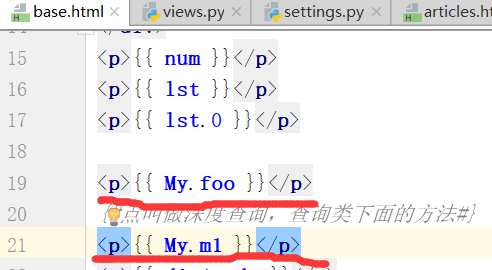
模板语言是不能传递参数的!!!
2-1变量过滤器
# 过滤器写法
{{name|lower:'ABC'}}
将views.py里边的name改成英文的donggua
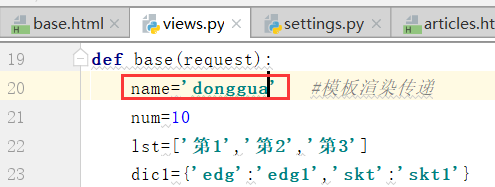
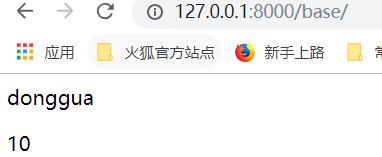
运行:
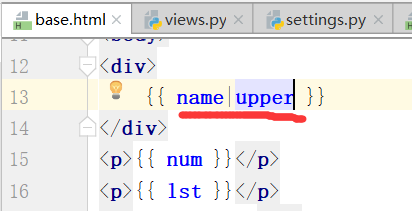
将name改成大写
运行:
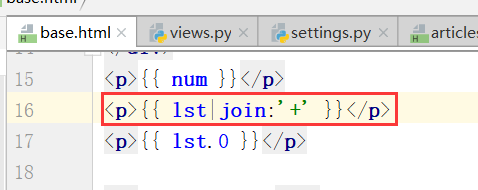
将列表拼成一项
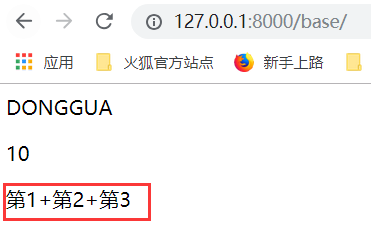
运行得到结果:
在base中修改
运行:得到结果
如何修改成能看懂的内容:
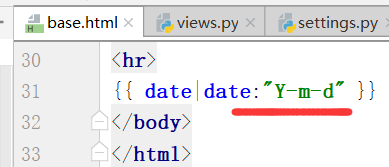
得到结果:
