安装request库
pip --default-timeout=100 install requests -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
简单案例
import requests
url = "http://www.baidu.com"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
r = requests.get(url=url,headers=headers)
result = r.text
print(result)
请求方式
# HTTP请求类型
# get类型
r = requests.get('https://github.com/timeline.json')
# post类型
r = requests.post("http://m.ctrip.com/post")
# put类型
r = requests.put("http://m.ctrip.com/put")
# delete类型
r = requests.delete("http://m.ctrip.com/delete")
# head类型
r = requests.head("http://m.ctrip.com/head")
# options类型
r = requests.options("http://m.ctrip.com/get")
获取响应信息
#获取当前的编码
r.encoding
#设置编码
r.encoding = 'utf-8'
#以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码。
r.text
#以字节形式(二进制)返回。字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩。
r.content
#以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
r.headers
#获取响应状态码
r.status_code
#返回原始响应体,也就是 urllib 的 response 对象,使用 r.raw.read()
r.raw
# 查看r.ok的布尔值便可以知道是否登陆成功
r.ok
#Requests中内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常
r.json()
#失败请求(非200响应)抛出异常
r.raise_for_status()
#返回发送到服务器的头信息
r.requests.headers
#返回cookie值
r.cookies
#返回重定向信息;可以在request请求加上allow_redirects = false 来阻止重定向
r.history
格式化谷歌浏览器复制的请求头信息
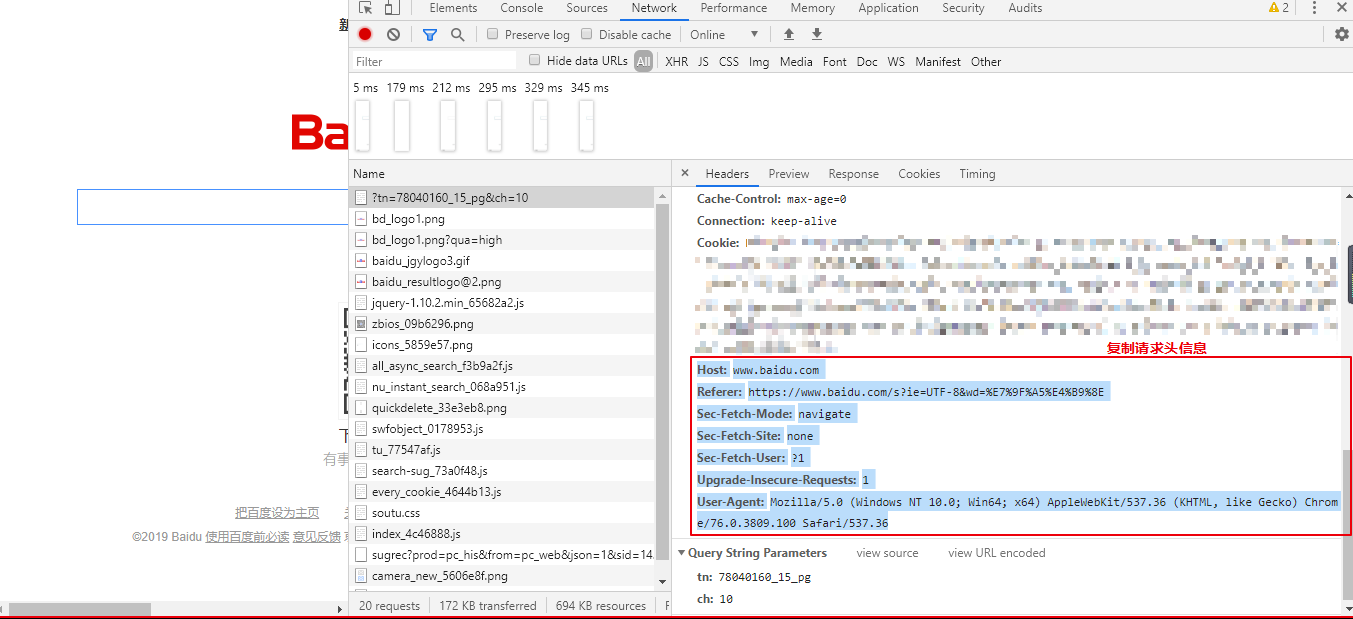
info = '''Host: www.baidu.com
Referer: https://www.baidu.com/s?ie=UTF-8&wd=%E7%9F%A5%E4%B9%8E
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'''
infoDic = {}
for e in info.split("
"):
k,v = e.split(":",1)
infoDic[k] = v.strip()
print(infoDic)
{'Host': 'www.baidu.com', 'Referer': 'https://www.baidu.com/s?ie=UTF-8&wd=%E7%9F%A5%E4%B9%8E', 'Sec-Fetch-Mode': 'navigate', 'Sec-Fetch-Site': 'none', 'Sec-Fetch-User': '?1', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}
cookies的解析和上面的思路类似。
传递请求参数
import requests
import json
url = "http://www.baidu.com"
headers = {'User-Agent' : 'Mozilla/5.0 (Linux; Android 4.2.1; en-us; Nexus 4 Build/JOP40D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Mobile Safari/535.19'}
params = {'keyword': '香港', 'salecityid': '2'}
cookies = {'BAIDUID':'88347BA2440BB05F7EF04EC4186904F4:FG=1'}
#代理IP(下面的代理IP已经失效)
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.100:4444",
}
r1 = requests.get(
url = url, #请求的URL
headers=headers, # 请求头
params=params, # 请求时携带的数据
cookies=cookies, # 发送cookie值
# proxies=proxies #设置代理IP
)
print(r1.text)
r2 = requests.post(
url = url,
headers=headers,
data=json.dumps(params) # 发送的数据,需要将字典转换为字符串类型
)
print(r2.text)