背景:cdh5.15.1 redhat7.3
habse的Resigion Server总是飘红,在cm的管理端界面爆出GC异常,随即Regision Server宕机。
最开始这种现象偶尔存在,调整habse Regision 的内存参数后可以缓解:
增大参数:
HBase RegionServer 的 Java 堆栈大小(字节)
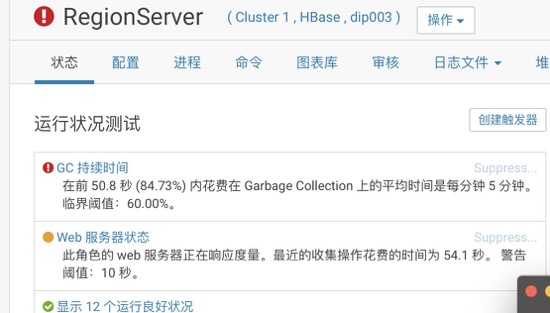
后来这个问题越来月严重,启动后不久就会自动宕掉,经过hbase老司机指点,修改了参数:HBase RegionServer 的 Java 配置选项
原参数
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
修改后
-Xmx16g -Xms8g -Xmn2g -Xss256k -XX:MaxPermSize=384m -XX:SurvivorRatio=6 -XX:+UseParNewGC -XX:ParallelGCThreads=10
-XX:+UseConcMarkSweepGC -XX:ParallelCMSThreads=16 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=70 -XX:CMSMaxAbortablePrecleanTime=500 -XX:CMSFullGCsBeforeCompaction=5 -XX:+CMSClassUnloadingEnabled -XX:+HeapDumpOnOutOfMemoryError
解析:
-Xmx:分配给JVM的最大堆内存
-Xms:分配给JVM的初始内存,此值一般和Xmx设置相同
-Xmn:分配给young区内存大小,此值的设置对系统性能影响很大,后面第二阶段将会重点讨论此值的参数的调优
-Xss:分配给每个线程的堆栈大小,在一些对线程数敏感的系统中该值设置比较重要,一般设置为256K~1M左右
-XX:MaxPermSize= M :分配给持久代的内存大小
-XX:SurvivorRatio=S : 表示young区中eden区和survivor区的内存大小比例,默认为8 该值的设置对系统性能影响很大,第三阶段会重点讨论该参数的调优
-XX:+UseConcMarkSweepGC :表示回收器使用CMS CG策略
-XX:+UseParNewGC :表示young区采用并行回收机制 推荐使用 &&&&&
-XX:+CMSParallelRemarkEnabled : 表示cms的remark阶段采用并行的方式,推荐使用 &&&&&
-XX:MaxTenuringThreshold=N : 表示young区对象晋升到Tenured区的阈值,该值的设置对系统的影响很大,在第三节点会重点讨论*****
-XX:+UseCMSCompactAtFullCollection :表示每次执行完cms gc之后执行一次碎片整合 推荐使用 &&&&&
-XX:+UseCMSInitiatingOccupancyOnly :表示cms gc只基于参数CMSInitiatingOccupancyFraction触发
-Xx:CMSInitiatingOccupancyFraction : 表示当tenured(老年代)区内存使用量超过tenured总大小的百分比超过该阈值之后会触发cms gc,该值一般设置为70%~80%
-XX:-DisableExplicitGC : 表示禁止使用命令System.gc() 该命令用于触发整个JVM的垃圾回收,一般都是长时间full gc 推荐使用 &&&&&
-XX:+PrintTenuringDistribution才能打印对应日志,强烈建议线上集群开启该参数,
待续。。。。。。