分库:
由单个数据库实例拆分成多个数据库实例,将数据分布到多个数据库实例中。
分表:
由单张表拆分成多张表,将数据划分到多张表内。
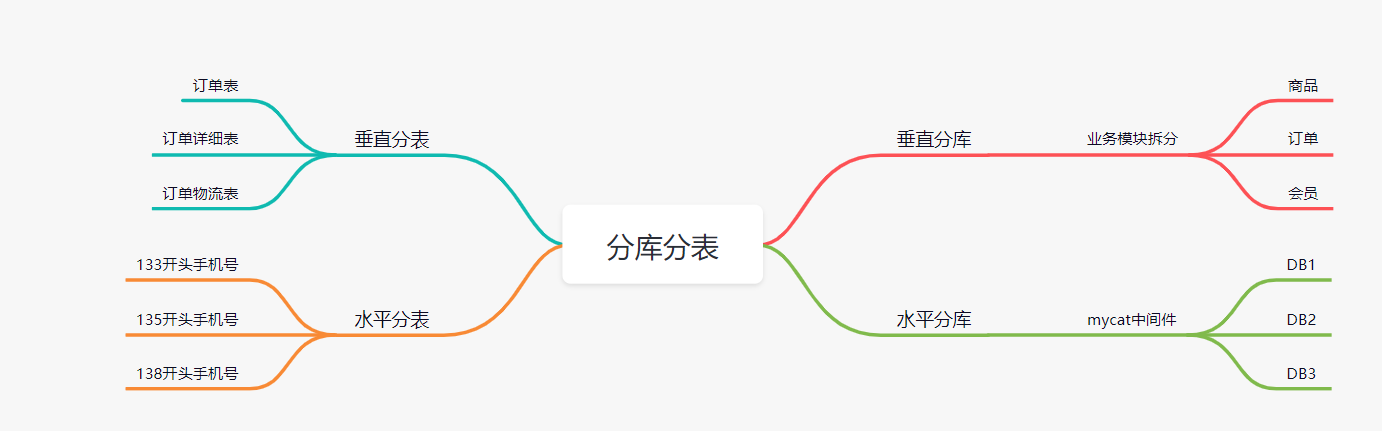
一、分库
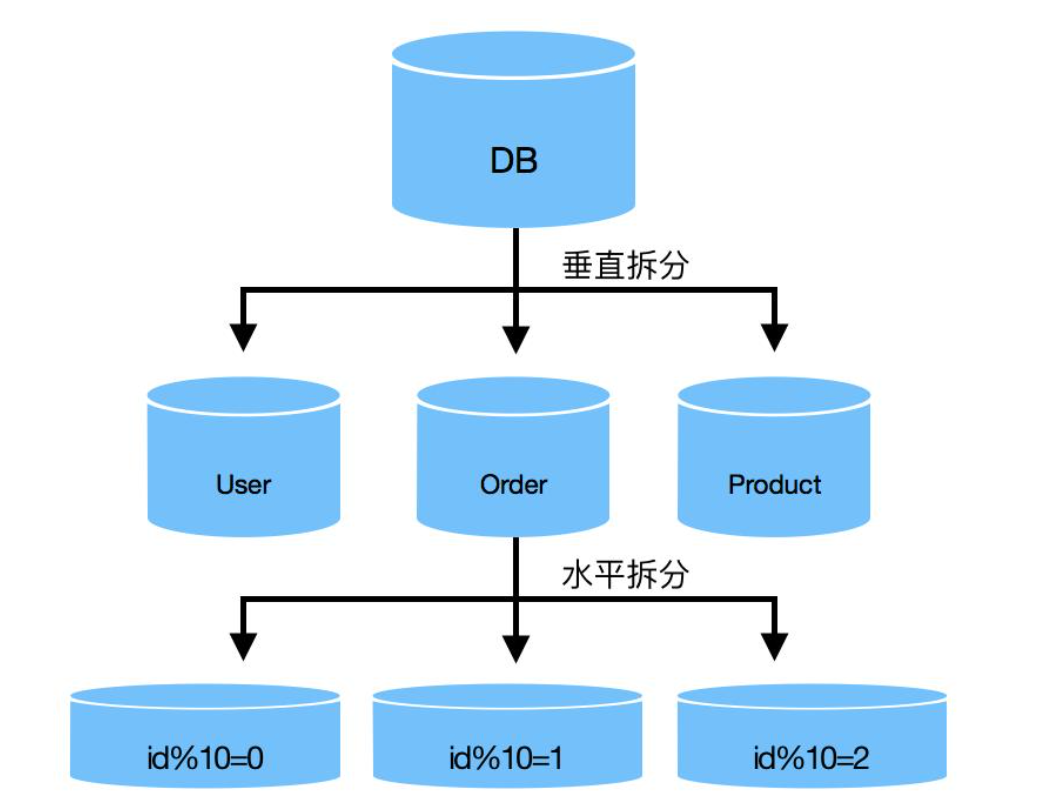
1、垂直分库
纵向切库,太经典的切分方式,基于表进行切分,通常是把新的业务模块或集成公共模块拆分出去。
特点:
每个库的表都不一样;
表不一样,数据就更不一样了~ 没有任何交集;
每个库相对独立,模块化;
场景:
可以抽象出单独的业务模块时,可以抽象出公共区时(如字典、公共时间、公共配置等),或者想有一台属于自己的服务器时?
2、水平分库
以行数据为依据,将一个库中的数据拆分到多个库中。大型分表体验一下?坦白说这种策略并不实用,因为会对后台开发很不友好,有很多坑,不建议采用,理解即可。
特点:
每个库的结构都一样;
每个库的数据都不一样,没有交集;
所有库的并集是全量数据;
场景:
系统绝对并发量上来了,CPU内存压力大。分表难以根本上解决量的问题,并且还没有明显的业务归属来垂直分库,主库磁盘接近饱和。
二、分表
1、垂直分表
垂直分表,或者叫竖着切表,是不是感受到该策略是以字段为依据的!主要按照字段的活跃性、字段长度,将表中字段拆分到不同的表(主表和扩展表)中。
特点:
每个表的结构都不一样;
每个表的数据也不一样,有一个关联字段,一般是主键或外键,用于关联兄弟表数据;
所有兄弟表的并集是该表的全量数据;
场景:
有几个字段属于热点字段,更新频率很高,要把这些字段单独切到一张表里,不然innodb行锁很恶心的,锁死你呀
有大字段,如text,存储压力很大,毕竟innodb数据和索引是同一个文件;
订单数据,可以拆分订单表,订单详细表,订单物流表等等。
2、水平分表
水平分表,也叫“横着切”。。以行数据为依据进行切分,一般按照某列的自容进行切分。
如手机号表,我们可以通过前两位或前三位进行切分,如131、132、133 → phone_131、phone_132、phone_133,手机号有11位(100亿),量大是很正常的事儿,这年头谁家老头老太太每个手机呢是吧。这样切就把一张大表切成了好几十张小表,数据量不就下来了。
有同学就问了那我怎么知道我这手机号查哪个表呢?一看你就没认真看前两行标红的点,为啥标红嘞?比如我查13100001111,那我截取前三位,动态拼接到查询的表名上,就行了。
特点:
每个表的结构都一样;
每个表的数据都不一样,没有交集;
所有表的并集是该表的全量数据;
场景:
单表的数据量过大或增长速度很快,已经影响或即将会影响SQL查询效率,加重了CPU负担,提前到达瓶颈。记得水平分表越早越好,别问我为什么。。