1、二进制安全的动态字符串,简单动态字符串(simple dynamic string,SDS)的抽象类型。大于1M数据就扩容两倍扩容字符串长度,否则扩容SDS_MAX_PREALLOC(1M)
SDS结构如下:
struct sdshdr{
int len; // 记录buf数组中已使用字节的数量
int free; // 记录buf中未使用字节数量
char buf[]; // 保存字符串的数组
}
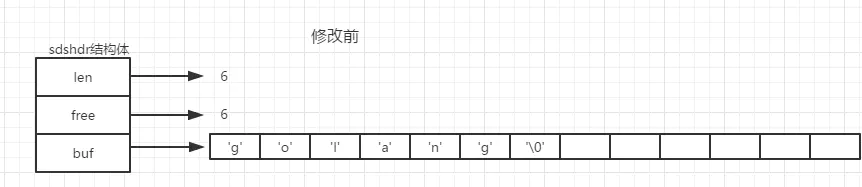
- 如果 SDS 修改后的长度小于 1MB,那么程序将会分配 len 字段值同样大小的未使用空间,这也是为什么我上面给出的例图中 len 的值是 6,free 值也是 6 的原因。对于上面那个例子,SDS 的总占用大小为:6(len) + 6(free) + 1('�') = 13 字节的容量。
2. 如果 SDS 修改后的长度大于 1MB,那么 SDS 将会为 SDS 分配 1MB 的未使用空间。如果一个 SDS len 值修改后的容量为 2MB,那么 redis 将会为 SDS 分配 1MB 的未使用空间。则此时 SDS 的总占用大小为:2MB(len) + 1MB(len) + 1byte('�') =3073 byte 容量。
这种扩容算法,减少了频繁的向系统申请内存的操作。SDS 的空间释放并不是实时的,而是惰性释放:redis 认为如果一个 SDS 的容量到达过 N 大小,则极有可能在其缩小后也有可能到达 N,且惰性释放也减少了下次内存分配的可能,假如现在有一个'golang'字符串存储在 redis 中, 现在我们需要将'golang'修改为'go',那么 redis 将会对 SDS 结构体将会是这样的:
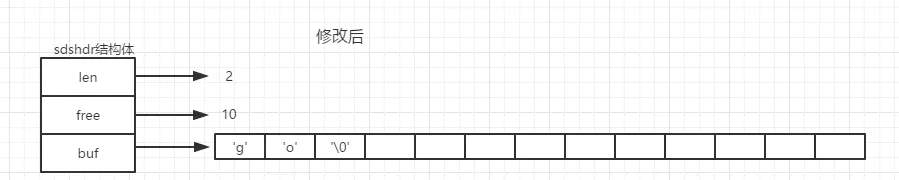
那么 SDS 提供了清理内存的 API,我们可以在有需要时,调用该 API 以便真正的释放内存。
总结
1. redis 只会使用 C 字符串作为字面量使用,大多数情况都使用 SDS 来表示字符串。
2. 能够使用常数级复杂度获取字符串的长度。
3. 杜绝了缓冲区溢出。
4. 减少了字符串所需内存重新分配的次数。以及对于二进制数据安全,且兼容部分 C 字符串函数。
2、list 有序列表双向链表又是,双端链表同时也是ziplist压缩链表,最后组合成quicklist快速链表。
3、hash 又叫字典,redis的哈希对象的底层存储可以使用ziplist(压缩链表)和hashtabl,通过挂链解决冲突问题。
4、set 底层使用了intset和hashtable两种数据结构存储的,intset我们可以理解为数组,hashtable就是普通的哈希表
5、zset score,value结构,ziplist 压缩链表+跳跃表.