1 需求分析
想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称、职位名称、薪资待遇、学历要求、岗位需求等信息。该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息,并将爬取下来的信息存入数据库。
2 目标站点分析
目标站点:https://www.lagou.com/。可以看见在左上角可以切换搜索城市,在正中央可以输入搜索职位关键字,选择好城市和输入搜索职位关键字后点击搜索按钮,就可以跳转到相应职位的列表页,每个列表页有15个详情项(最后一页可能不足15个)。点击每个详情项,就可以跳转到对应公司的详情页,而要爬取的数据就在详情页中。
Tips:有可能同一个公司会由不同的HR发出相同的招聘信息,例如搜索Python爬虫,会发现公司Eigen发布了两条招聘信息,分别由云衫和Casey分别发布。
3 流程分析
为了复习Scrapy和Selenium,没有使用requests库来实现这个爬虫,具体流程:
1.切换城市和输入搜索关键字:用Selenium驱动浏览器模拟点击左上角的切换城市,然后输入搜索关键字,最后点击搜索按钮,跳转到相应职位的列表页。
2.解析列表页并模拟翻页:解析首个列表页,拿到整个职位列表页的页码数,用Selenium模拟翻页,在翻页的同时拿到各个详情页的url。
3.解析详情页并提取数据:解析每个公司的详情页,用Scrapy的ItemLoader来获取各个字段信息,并进行相应的数据处理工作。
4.存储数据到MongoDB:将获取到的每个公司详情信息存储到MongoDB数据库。
4 代码实现
用Scrapy框架来组织整个代码。整个程序流程图:
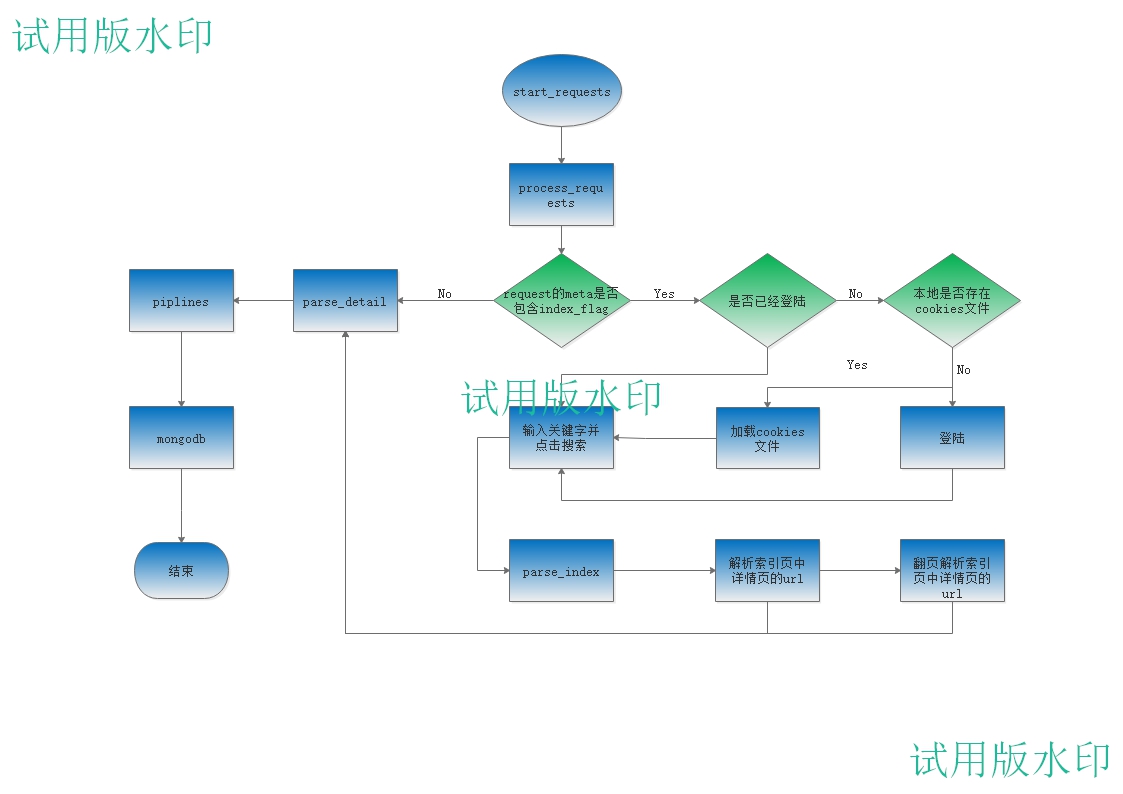
大致的流程图是这样的,拉钩网的数据爬取是不需要Cookie的,加了Cookie反而会被识别出来是爬虫。流程图中关于模拟登陆、保存cookie到本地和从本地加载cookie只是加强https://www.cnblogs.com/strivepy/p/9233389.html的练习。
4.1 在Scrapy中一个Request是如何在DownloadMiddleware传递的
Scrapy官方文档https://doc.scrapy.org/en/master/topics/settings.html#std:setting-DOWNLOADER_MIDDLEWARES_BASE对于DOWNLOADER_MIDDLEWARES_BASE的说明:
1 { 2 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100, 3 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300, 4 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350, 5 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400, 6 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500, 7 'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550, 8 'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560, 9 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580, 10 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590, 11 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600, 12 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700, 13 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750, 14 'scrapy.downloadermiddlewares.stats.DownloaderStats': 850, 15 'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900, 16 }
序号越小说明这个中间件离引擎越近,序号越大说明这个中间件离下载器越近。
每个Middleware都有process_request(request, spider)、prcess_response(request, response, spider)、process_exception(request, exception, spider)三个函数(哪怕没有实现)。
当一个request由调度器调度经过各个下载器中间件时(没有异常的情况下),request依次穿过序号从小到大的每个Middleware的process_request()函数到达下载器Downloader,下载器完成下载后即获取到response后,response依次穿过序号从大到小的每个Middleware的process_response()函数到达引擎。
而Scrapy项目setting.py中DOWNLOADER_MIDDLEWARES自定义的各个Middleware会在项目运行时,框架自动和DOWNLOADER_MIDDLEWARES_BASE进行合并而得到一个完成的下载中间件列表。
4.2 实现城市切换和输入搜索关键字
基本思路:由start_request()函数发出带有flag的的初始请求,该flag只为在middleware中筛选出最初始的request,然后在process_request()函数中实现模拟登陆、加载本地cookie、切换城市、输入搜索关键字然后点击搜索按钮跳转到职位列表页。
4.2.1 start_request()发起的带有flag的请求
在meta中设置属性index_flag来在middleware中过滤出初始请求,brower来接收Chrome实例,wait来接收WebDriverWait实例,pagenumber来接收整个列表页的页数。
1 # Location: LagouCrawler.spider.lagoucrawler.LagouCrawlerSpder 2 3 def start_requests(self): 4 base_url = 'https://www.lagou.com' 5 index_flag = {'index_flag': 'fetch index page', 'brower': None, 'wait': None, 'pagenumber': None} 6 yield scrapy.Request(url=base_url, callback=self.parse_index, meta=index_flag, dont_filter=True)
4.2.2 process_request()函数过滤出初始请求
在process_request()函数中过滤出初始请求后,判断是否已经登陆,若已经登陆,则直判断是否需要切换城市,然后输入搜索关键字最后点击搜索跳转到列表页,否则判断本地是否存在cookie文件,如果存在则直接加载本地cookie文件,否则进行模拟登陆并将cookie保存为本地文件,然后再判断是否需要切换城市,并输入搜索关键字然后点击搜索跳转到列表页。
1 # Location: LagouCrawler.middlewares.LagoucrawlerDownloaderMiddleware 2 def process_request(self, request, spider): 3 """ 4 middleware的核心函数,每个request都会经过该函数。此函数过滤出初始request和详情页request, 5 对于初始request进行验证登陆、cookies等一系列操作,然后将最后获取到的索引页response返回,对 6 于详情页的request则,不做任何处理。 7 :param request: 8 :param spider: 9 :return: 10 """ 11 # 过滤出初始的登陆、切换索引页的request 12 if 'index_flag' in request.meta.keys(): 13 # 判断是否为登陆状态,若未登陆则判断是否有cookies文件存在 14 if not self.is_logined(request, spider): 15 path = os.getcwd() + '/cookies/lagou.txt' 16 # 若cookies文件存在,则加载cookie文件,否则进行登陆操作 17 if os.path.exists(path): 18 self.load_cookies(path) 19 else: 20 # 登陆lagou网 21 self.login_lagou(spider) 22 # 登陆成功后的索引页的响应体,若不登录,请求响应提详情页面的url时,会重定向到登陆页面 23 response = self.fetch_index_page(request, spider) 24 return response
用Chrome驱动浏览器时,总会先弹出切换城市的窗口,所以需要先将其关掉,再通过获取右上角的登陆状态元素的为本内容,来判断是否已经为登陆状态。
1 # Location: LagouCrawler.middlewares.LagoucrawlerDownloaderMiddleware 2 def is_logined(self, request, spider): 3 """ 4 初始请求时,总会弹出切换城市的窗口,所以先关掉它,然后通过判断右上角是否显示 5 用户名判断是否为登陆状态,并初始化整个程序的brower实例 6 :param request: 初始请求request,其meta包含index_page属性 7 :param spider: 8 :return: 已经登陆返回True, 否则返回False 9 """ 10 self.brower.get(request.url) 11 try: 12 # 关掉城市选择窗口 13 box_close = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="cboxClose"]'))) 14 box_close.click() 15 # 获取右上角的登录状态 16 login_status = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="lg_tbar"]/div/ul/li[1]/a'))) 17 # 若右上角显示为登陆,则说明用户还没有登陆 18 if login_status.text == '登录': 19 return False 20 else: 21 return True 22 except TimeoutException as e: 23 # 二次请求,不会出现地址框,需要重新设计 24 spider.logger.info('Locate Username Element Failed:%s' % e.msg) 25 return False
加载本地cookie文件到Chrome实例中。
1 # Location: LagouCrawler.middlewares.LagoucrawlerDownloaderMiddleware 2 def load_cookies(self, path): 3 """ 4 加载本地cookies文件,实现免登录访问 5 :param path: 本地cookies文件路径 6 :return: 7 """ 8 with open(path, 'r') as f: 9 cookies = json.loads(f.read()) 10 for cookie in cookies: 11 cookies_dict = {'name': cookie['name'], 'value': cookie['value']} 12 self.brower.add_cookie(cookies_dict)
若没有本地cookie文件,则需要登录拉钩网,并将cookie保存为本地文件,待以后使用:
1 # Location: LagouCrawler.middlewares.LagoucrawlerDownloaderMiddleware 2 def login_lagou(self, spider): 3 """ 4 用selenium模拟登陆流程,并将登陆成功后的cookies保存为本地文件。 5 :param spider: 6 :return: 7 """ 8 try: 9 # 设置等待时间,否则会出现登陆元素查找不到的异常 10 time.sleep(2) 11 # 点击进入登录页面 12 login_status = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="loginToolBar"]//a[@class="button bar_login passport_login_pop"]'))) 13 login_status.click() 14 # 输入用户名 15 username = self.wait.until(EC.visibility_of_element_located((By.XPATH, '//*[@data-propertyname="username"]/input'))) 16 username.send_keys(self.username) 17 # 输入用户密码 18 password = self.wait.until(EC.visibility_of_element_located((By.XPATH, '//*[@data-propertyname="password"]/input'))) 19 password.send_keys(self.password) 20 # 点击登陆按钮 21 submit_button = self.wait.until(EC.visibility_of_element_located((By.XPATH, '//*[@data-propertyname="submit"]/input'))) 22 submit_button.click() 23 # time.sleep(1) 24 # 获取登录成功后的cookies 25 cookies = self.brower.get_cookies() 26 # 保存登陆后的cookies 27 self.save_cookies(cookies) 28 except TimeoutException as e: 29 spider.logger.info('Locate Login Element Failed: %s' % e.msg)
在完成登陆后使用save_cookies()函数将cookie保存为本地文件:
1 # Location: LagouCrawler.middlewares.LagoucrawlerDownloaderMiddleware 2 @staticmethod 3 def save_cookies(cookies): 4 """ 5 登陆成功后,将cookie保存为本地文件,供下次程序运行或者以后使用 6 :param cookies: 7 :return: 8 """ 9 path = os.getcwd() + '/cookies/' 10 if not os.path.exists(path): 11 os.mkdir(path) 12 with open(path + 'lagou.txt', 'w') as f: 13 f.write(json.dumps(cookies))
最后在完成所有关于cookie的操作后,进行城市切换和输入搜索关键字并点击搜索按钮,使用WebDriverWait后,有些元素获取还是会报元素不可点击的异常,所以在前面加上time.sleep(1):
1 # Location: LagouCrawler.middlewares.LagoucrawlerDownloaderMiddleware 2 def fetch_index_page(self, request, spider): 3 """ 4 该函数使用selenium完成城市切换,搜索关键字输入并点击搜索按钮操作。如果点击搜索按钮后, 5 页面没有成功跳转,则会因为31行的代码,抛出NoSuchElementException,而在load_cookies() 6 函数报一个NoneType没有get_cookies()的错误。原因是response是空的。 7 :param request: 8 :param spider: 9 :return: 10 """ 11 try: 12 # 判断是否需要切换城市 13 city_location = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="lg_tnav"]/div/div/div/strong'))) 14 if city_location.text != self.city: 15 time.sleep(1) 16 city_change = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="changeCity_btn"]'))) 17 city_change.click() 18 # 根据搜索城市定位到相应元素并点击切换 19 # time.sleep(1) 20 city_choice = self.wait.until(EC.presence_of_element_located((By.LINK_TEXT, self.city))) 21 city_choice.click() 22 time.sleep(1) 23 # 定位关键字输入框并输入关键字 24 keywords_input = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="search_input"]'))) 25 keywords_input.send_keys(self.job_keywords) 26 # time.sleep(1) 27 # 定位搜索按钮并点击,有时候点击后页面不会发生跳转,原因是被重定向了。 28 keywords_submit = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="search_button"]'))) 29 keywords_submit.click() 30 # 跳转到列表页等待待抓取的内容元素加载完成,如果被重定向,则跳转不到该页面,会报NoSuchElementException 31 self.wait.until(EC.visibility_of_all_elements_located((By.XPATH, '//*[@id="s_position_list"]'))) 32 pagenumber = self.wait.until(EC.presence_of_element_located(( 33 By.XPATH, '//*[@id="s_position_list"]/div[@class="item_con_pager"]/div/span[@class="pager_next "]/preceding-sibling::span[1]' 34 ))) 35 # 获取一共有多少页,供通过response传递到parse_detail函数,进行后续的翻页解析使用 36 request.meta['pagenumber'] = pagenumber.text 37 # 将brower和wait通过response传递到parse_detail函数,进行后续的翻页解析使用 38 request.meta['brower'] = self.brower 39 request.meta['wait'] = self.wait 40 body = self.brower.page_source 41 # 返回初始搜索页面,在parse_detail函数中进行相关信息的解析 42 response = HtmlResponse( 43 url=self.brower.current_url, 44 body=body, 45 encoding='utf-8', 46 request=request 47 ) 48 return response 49 except TimeoutException: 50 spider.logger.info('Locate Index Element Failed And Use Proxy Request Again') 51 # except NoSuchElementException: 52 # 如果捕捉到该异常,说明页面被重定向了,没有正常跳转,重新请求输入关键字页面 53 return request
在跳转到列表页后,将brower(Chrome实例), wait(WebDriverWait实例)和pagenumber放入request.meta中。然后返回response(HtmlResponse实例),该response由start_request()函数指定的回调函数parse_index()进行解析,在该函数中通过response.meta取出刚刚存放进request.meta中的brower,wait和pagenumber,来进行接下来的翻页操作。
4.3 实现解析列表页和模拟翻页
当Selenium驱动Chrome完成切换城市、输入搜索关键字、点击搜索按钮并成功跳转到列表页后,会将第一页列表页的response传递到parse_index()回调函数进行解析:
1 # Location: LagouCrawler.spider.lagoucrawler.LagouCrawlerSpder 2 def parse_index(self, response): 3 """ 4 解析第一页列表页,拿到各个招聘详情页url,并发起请求;然后进行翻页做操,拿到每页 5 列表页各个详情页的url,并发起请求。注意:以杭州Python爬虫职位为例详情页请求发起 6 大概55个后(抓取的时候,一共有4页,每页15个招聘,供60个招聘详情),最后5个总是 7 被重定向到最初始输入搜索关键字的页面,即使设置了DOWNLOAD_DELAY也是没用。应该是 8 被服务器识别出了是机器人了,初步思路是在middlewares的process_response()函数中, 9 通过判断response的status_code,对重定向的request加上代理后,再次发起request, 10 但是这个思路没能实现,需要更深层次的理解框架,所以使用了阿布云代理的动态代理, 11 让每个request都通过代理服务器发出请求。 12 :param response: 经middleware筛选并处理后的第一页详情页response 13 :return: 14 """ 15 self.pagenumber = response.meta['pagenumber'] 16 # 初始化spider中的brower和wait 17 self.brower = response.meta['brower'] 18 self.wait = response.meta['wait'] 19 # 解析索引页各项招聘详情页url 20 for url in self.parse_url(response): 21 yield scrapy.Request(url=url, callback=self.parse_detail, dont_filter=True) 22 # 翻页并解析 23 for pagenumber in range(2, int(self.pagenumber) + 1): 24 response = self.next_page() 25 for url in self.parse_url(response): 26 yield scrapy.Request(url=url, callback=self.parse_detail, dont_filter=True)
在parse_index()函数中有两个函数,一个是解析单个列表页中各个详情项url的parse_url()函数,和模拟翻页的next_page()函数。在解析出详情项的url后,发起请求。Scrapy会对request的url去重(RFPDupeFilter),将dont_filter设置为True,则告诉Scrapy这个url不参与去重。
解析详情项url的parse_url()函数,返回详情项url列表:
1 # Location: LagouCrawler.spider.lagoucrawler.LagouCrawlerSpder 2 @staticmethod 3 def parse_url(response): 4 """ 5 解析出每页列表页各项招聘信息的url 6 :param response: 列表页response 7 :return: 该列表页各项招聘详情页的url列表 8 """ 9 url_selector = response.xpath('//*[@id="s_position_list"]/ul/li') 10 url_list = [] 11 for selector in url_selector: 12 url = selector.xpath('.//div[@class="p_top"]/a/@href').extract_first() 13 url_list.append(url) 14 return url_list
模拟翻页的next_page()函数,返回下一页列表页的response。将翻页速速控制为2秒,在寻找下一页这个元素时,需要注意的地方如代码所示:
1 # Location: LagouCrawler.spider.lagoucrawler.LagouCrawlerSpder 2 def next_page(self): 3 """ 4 用selenium模拟翻页动作。用xpath获取next_page_button控件时,花了很久时间,原因是 5 span标签的class="pager_next "后引号前面有一个空格!!! 6 :return: 7 """ 8 try: 9 # 用xpath找这个下一页按钮居然花了半天的时间居然是这个程序员大哥在span标签的class="pager_next "加了个空格,空格!!! 10 next_page_button = self.wait.until(EC.presence_of_element_located(( 11 By.XPATH, '//*[@id="s_position_list"]/div[@class="item_con_pager"]/div/span[@class="pager_next "]' 12 ))) 13 next_page_button.click() 14 self.wait.until(EC.visibility_of_all_elements_located((By.XPATH, '//*[@id="s_position_list"]'))) 15 # 控制翻页速度 16 time.sleep(2) 17 body = self.brower.page_source 18 response = HtmlResponse(url=self.brower.current_url, body=body, encoding='utf-8') 19 return response 20 except TimeoutException: 21 pass
每解析完一个列表页,都会对解析出来url发起请求,来请求详情页。
4.4 实现详情页解析并提取数据
每个详情项的url请求返回的response都会由parse_detail()函数来解析,使用ItemLoader完成数据提取和格式化操作:
1 # Location: LagouCrawler.spider.lagoucrawler.LagouCrawlerSpder 2 @staticmethod 3 def parse_detail(response): 4 """ 5 解析每一页各个招聘信息的详情 6 :param response: 每个列表页的HtmlResponse实例 7 :return: 各个公司招聘详情生成器 8 """ 9 item_loader = CompanyItemLoader(item=CompanyItem(), response=response) 10 item_loader.add_xpath('company_name', '//*[@id="job_company"]/dt/a/div/h2/text()') 11 item_loader.add_xpath('company_location', 'string(//*[@id="job_detail"]/dd[@class="job-address clearfix"]/div[@class="work_addr"])') 12 item_loader.add_xpath('company_website', '//*[@id="job_company"]/dd/ul/li[5]/a/@href') 13 item_loader.add_xpath('company_figure', '//*[@id="job_company"]/dd/ul//i[@class="icon-glyph-figure"]/parent::*/text()') 14 item_loader.add_xpath('company_square', '//*[@id="job_company"]/dd/ul//i[@class="icon-glyph-fourSquare"]/parent::*/text()') 15 item_loader.add_xpath('company_trend', '//*[@id="job_company"]/dd/ul//i[@class="icon-glyph-trend"]/parent::*/text()') 16 item_loader.add_xpath('invest_organization', '//*[@id="job_company"]/dd/ul//p[@class="financeOrg"]/text()') 17 item_loader.add_xpath('job_position', '//*[@class="position-content-l"]/div[@class="job-name"]/span/text()') 18 item_loader.add_xpath('job_salary', '//*[@class="position-content-l"]/dd[@class="job_request"]/p/span[@class="salary"]/text()') 19 item_loader.add_xpath('work_experience', '//*[@class="position-content-l"]/dd[@class="job_request"]/p/span[3]/text()') 20 item_loader.add_xpath('degree', '//*[@class="position-content-l"]/dd[@class="job_request"]/p/span[4]/text()') 21 item_loader.add_xpath('job_category', '//*[@class="position-content-l"]/dd[@class="job_request"]/p/span[5]/text()') 22 item_loader.add_xpath('job_lightspot', '//*[@id="job_detail"]/dd[@class="job-advantage"]/p/text()') 23 item_loader.add_xpath('job_description', 'string(//*[@id="job_detail"]/dd[@class="job_bt"]/div)') 24 item_loader.add_xpath('job_publisher', '//*[@id="job_detail"]//div[@class="publisher_name"]/a/span/text()') 25 item_loader.add_xpath('resume_processing', 'string(//*[@id="job_detail"]//div[@class="publisher_data"]/div[2]/span[@class="tip"])') 26 item_loader.add_xpath('active_time', 'string(//*[@id="job_detail"]//div[@class="publisher_data"]/div[3]/span[@class="tip"])') 27 item_loader.add_xpath('publish_date', '//*[@class="position-content-l"]/dd[@class="job_request"]/p[@class="publish_time"]/text()') 28 item = item_loader.load_item() 29 yield item
Item字段和ItemLoader的定义,此处定义中完成提取字段的格式化处理(去掉空格、换行符等):
1 # Location: LagouCrawler.items 2 # -*- coding: utf-8 -*- 3 4 # Define here the models for your scraped items 5 # 6 # See documentation in: 7 # https://doc.scrapy.org/en/latest/topics/items.html 8 9 import datetime 10 from scrapy import Item, Field 11 from scrapy.loader import ItemLoader 12 from scrapy.loader.processors import TakeFirst, MapCompose, Join 13 14 15 def formate_date(value): 16 """ 17 根据提取到的发布时间,若是当天发布则是H:M格式,则获取当天日期的年月日然后返回,否则是Y:M:D格式, 18 则直接返回该年月日 19 :param value: 提取到的时间字符串 20 :return: 格式化后的年月日 21 """ 22 if ':' in value: 23 now = datetime.datetime.now() 24 publish_date = now.strftime('%Y-%m-%d') 25 publish_date += '(今天)' 26 return publish_date 27 else: 28 return value 29 30 31 class CompanyItemLoader(ItemLoader): 32 default_output_processor = TakeFirst() 33 34 35 class CompanyItem(Item): 36 # define the fields for your item here like: 37 # name = scrapy.Field() 38 39 # 公司名称 40 company_name = Field( 41 input_processor=MapCompose(lambda x: x.replace(' ', ''), lambda x: x.strip()) 42 ) 43 # 公司地址 44 company_location = Field( 45 input_processor=MapCompose(lambda x: x.replace(' ', ''), lambda x: x.replace(' ', ''), lambda x: x[:-4]) 46 ) 47 # 公司官网 48 company_website = Field() 49 # 公司规模 50 company_figure = Field( 51 input_processor=MapCompose(lambda x: x.replace(' ', ''), lambda x: x.replace(' ', '')), 52 output_processor=Join('') 53 ) 54 # 公司领域 55 company_square = Field( 56 input_processor=MapCompose(lambda x: x.replace(' ', ''), lambda x: x.replace(' ', '')), 57 output_processor=Join('') 58 ) 59 # 公司阶段 60 company_trend = Field( 61 input_processor=MapCompose(lambda x: x.replace(' ', ''), lambda x: x.replace(' ', '')), 62 output_processor=Join('') 63 ) 64 # 投资机构 65 invest_organization = Field() 66 67 # 岗位名称 68 job_position = Field() 69 # 岗位薪资 70 job_salary = Field( 71 input_processor=MapCompose(lambda x: x.strip()) 72 ) 73 # 经验需求 74 work_experience = Field( 75 input_processor=MapCompose(lambda x: x.replace(' /', '')) 76 ) 77 # 学历需求 78 degree = Field( 79 input_processor=MapCompose(lambda x: x.replace(' /', '')) 80 ) 81 # 工作性质 82 job_category = Field() 83 84 # 职位亮点 85 job_lightspot = Field() 86 # 职位描述 87 job_description = Field( 88 input_processor=MapCompose(lambda x: x.replace('xa0xa0xa0xa0', '').replace('xa0', ''), lambda x: x.replace(' ', '').replace(' ', '')) 89 ) 90 91 # 职位发布者 92 job_publisher = Field() 93 # 发布时间 94 publish_date = Field( 95 input_processor=MapCompose(lambda x: x.replace('xa0 ', '').strip(), lambda x: x[:-6], formate_date) 96 ) 97 # # 聊天意愿 98 # chat_will = Field() 99 # 简历处理 100 resume_processing = Field( 101 input_processor=MapCompose(lambda x: x.replace('xa0', '').strip()) 102 ) 103 # 活跃时段 104 active_time = Field( 105 input_processor=MapCompose(str.strip) 106 )
ItemLoader的具体使用可以参考https://blog.csdn.net/zwq912318834/article/details/79530828
4.5 存储数据到MongoDB
通过使用itempipline将抓取到的数据存储到MongoDB:
1 # Location: LagouCrawler.piplines 2 3 # -*- coding: utf-8 -*- 4 5 # Define your item pipelines here 6 # 7 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 8 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 9 10 from pymongo import MongoClient 11 12 13 class LagoucrawlerPipeline(object): 14 15 def __init__(self, host=None, db=None, collection=None): 16 self.mongo_uri = host 17 self.mongo_db = db 18 self.mongo_collection = collection 19 self.client = None 20 self.db = None 21 self.collection = None 22 23 @classmethod 24 def from_crawler(cls, crawler): 25 """ 26 通过该函数,获取在settings.py文件中定义的Mongodb地址、数据库名称和表名 27 :param crawler: 28 :return: 29 """ 30 return cls( 31 host=crawler.settings.get('MONGO_URI'), 32 db=crawler.settings.get('MONGO_DB'), 33 collection=crawler.settings.get('MONGO_COLLECTION') 34 ) 35 36 def open_spider(self, spider): 37 """ 38 在spider打开时,完成mongodb数据库的初始化工作。 39 :param spider: 40 :return: 41 """ 42 self.client = MongoClient(host=self.mongo_uri) 43 self.db = self.client[self.mongo_db] 44 self.collection = self.db[self.mongo_collection] 45 46 def process_item(self, item, spider): 47 """ 48 pipeline的核心函数,在该函数中执行对item的一系列操作,例如存储等。 49 :param item: parse_detail函数解析出来的item 50 :param spider: 抓取该item的spider 51 :return: 返回处理后的item,供其它pipeline再进行处理(如果有的话) 52 """ 53 # 以公司名称做为查询条件 54 condition = {'company_name': item.get('company_name')} 55 # upsert参数设置为True后,若数据库中没有该条记录,会执行插入操作; 56 # 同时,使用update_one()函数,也可以完成去重操作。 57 result = self.collection.update_one(condition, {'$set': item}, upsert=True) 58 spider.logger.debug('The Matched Item is: {} And The Modified Item is: {}'.format(result.matched_count, result.modified_count)) 59 return item 60 61 def close_spider(self, spider): 62 """ 63 在spider关闭时,关闭mongodb数据连接。 64 :param spider: 65 :return: 66 """ 67 self.client.close()
Tips:在查看MongoDB数据时,会发现数据数量会比抓取下来的数据数量少,原因是数据插入是用MongoDB的更新函数update_one()以公司名称为查询条件完成的,而所有详情项中会出现同一个公司不同的hr发布相同职位的招聘信息。
然后在setting.py文件中配置一下该pipline:
1 # Location: LagouCrawler.settings 2 3 # Configure item pipelines 4 # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 5 ITEM_PIPELINES = { 6 'LagouCrawler.pipelines.LagoucrawlerPipeline': 300, 7 } 8 9 # Mongodb地址 10 MONGO_URI = 'localhost' 11 # Mongodb库名 12 MONGO_DB = 'job' 13 # Mongodb表名 14 MONGO_COLLECTION = 'works'
到此,运行爬虫,不出意外的话,程序能够完成城市的切换、搜索关键字的输入、索引页的翻页以及详情项的字段提取。事实是能到一部分数据,然后就是302重定向和各种40X和50X响应。原因是拉钩网的反爬虫措施。
4.6 爬取拉钩网IP被禁解决方案
如上所诉,在整个程序框架完成后,并没有如愿的拿到完整数据,而是在拿到部分数据后,请求被重定向,最后IP被禁。所以需要采取一些措施。
4.6.1 爬取拉钩网不需要cookie
拉钩网的爬取不是不需要cookie,而是不能有cookie,拉钩网根据cookie来识别是否是爬虫在访问,所以在settings.py中禁掉cookie:
1 # Location: LagouCrawler.settings 2 3 # Disable cookies (enabled by default) 4 COOKIES_ENABLED = False
4.6.2 爬取拉钩网的请求头Headers
需要在settings.py中配置一下请求头,来伪装成浏览器(此处没有配置User-Agent):
1 # Location: LagouCrawler.settings 2 3 # Override the default request headers: 4 DEFAULT_REQUEST_HEADERS = { 5 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 6 'Accept-Encoding': 'gzip, deflate, br', 7 'Accept-Language': 'zh-CN,zh;q=0.9', 8 'Host': 'www.lagou.com', 9 'Referer': 'https://www.lagou.com/', 10 'Connection': 'keep-alive' 11 }
4.6.3 给每个request配置随机User-Agent
为了防止IP因为User-Agent被禁,所以定义一个下载中间件,用fake_useragent第三方包来给每个request添加一个随机的User-Agent:
1 # Location: LagouCrawler.middlewares 2 3 class RandomUserAgentMiddleware(object): 4 """ 5 给每一个request添加随机的User-Agent 6 """ 7 8 def __init__(self, ua_type=None): 9 super(RandomUserAgentMiddleware, self).__init__() 10 self.ua = UserAgent() 11 self.ua_type = ua_type 12 13 @classmethod 14 def from_crawler(cls, crawler): 15 """ 16 获取setting.py中配置的RANDOM_UA_TYPE,如果没有配置,则使用默认值random 17 :param crawler: 18 :return: 19 """ 20 return cls( 21 ua_type=crawler.settings.get('RANDOM_UA_TYPE', 'random') 22 ) 23 24 def process_request(self, request, spider): 25 """ 26 UserAgentMiddleware的核心方法,getattr(A, B)相当于A.B,也就是获取A 27 对象的B属性,在这就相当于ua.random 28 :param request: 29 :param spider: 30 :return: 31 """ 32 request.headers.setdefault('User-Agent', getattr(self.ua, self.ua_type)) 33 # 每个请求禁止重定向 34 request.meta['dont_redirect'] = True 35 request.meta['handle_httpstatus_list'] = [301, 302] 36 spider.logger.debug('The <{}> User Agent Is: {}'.format(request.url, getattr(self.ua, self.ua_type)))
在settings.py中配置一下该下载中间件,注意需要禁掉Scrapy框架自带的UserAgentMiddleWare:
1 # Location: LagouCrawler.settings 2 3 DOWNLOADER_MIDDLEWARES = { 4 # 启用阿布云代理服务器中间件 5 'LagouCrawler.middlewares.AbuYunProxyMiddleware': 1, 6 # 在DownloaderMiddleware之前启用自定义的RandomUserAgentMiddleware 7 'LagouCrawler.middlewares.RandomUserAgentMiddleware': 542, 8 # 禁用框架默认启动的UserAgentMiddleware 9 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, 10 'LagouCrawler.middlewares.LagoucrawlerDownloaderMiddleware': 543, 11 }
Tips:在给每个request添加随机User-Agent的同时,让该request禁止重定向,原因是在后面使用代理服务器的时候,如果有一个请求通过代理服务器请求失败,该请求会被重定向,结果导致程序进入该重定向页面的死循环。
4.6.4 使用阿布云代理服务器来发起请求
相对于自己维护一个代理池,使用阿布云代理的动态版(适用于爬虫业务,需要付费)来为每一个request分配一个随机IP更加方便灵活。
阿布云官网:https://center.abuyun.com
阿布云接口教程:https://www.jianshu.com/p/90d57e7a545a?spm=a2c4e.11153940.blogcont629314.15.59f8319fWrMVQK
同样写一个下载中间件,让每一个request通过阿布云来发起请求:
1 # Location: LagouCrawler.middlewares 2 3 class AbuYunProxyMiddleware(object): 4 """ 5 接入阿布云代理服务器,该服务器动态IP1秒最多请求5次。需要在setting中设置下载延迟 6 """ 7 8 def __init__(self, settings): 9 self.proxy_server = settings.get('PROXY_SERVER') 10 self.proxy_user = settings.get('PROXY_USER') 11 self.proxy_pass = settings.get('PROXY_PASS') 12 self.proxy_authorization = 'Basic ' + base64.urlsafe_b64encode( 13 bytes((self.proxy_user + ':' + self.proxy_pass), 'ascii')).decode('utf8') 14 15 @classmethod 16 def from_crawler(cls, crawler): 17 return cls( 18 settings=crawler.settings 19 ) 20 21 def process_request(self, request, spider): 22 request.meta['proxy'] = self.proxy_server 23 request.headers['Proxy-Authorization'] = self.proxy_authorization 24 spider.logger.debug('The {} Use AbuProxy'.format(request.url))
服务器的地址、阿布云的用户名和密码(可以1块钱买1个小时,默认每秒5个请求)都配置在settings.py中:
1 # Location: LagouCrawler.settings 2 3 # 阿布云代理服务器地址 4 PROXY_SERVER = "http://http-dyn.abuyun.com:9020" 5 # 阿布云代理隧道验证信息,注册阿布云购买服务后获取 6 PROXY_USER = 'H9470L5HEARXXXXX' 7 PROXY_PASS = '02E02D1D773XXXXX' 8 # 启用限速设置 9 AUTOTHROTTLE_ENABLED = True 10 AUTOTHROTTLE_START_DELAY = 0.2 # 初始下载延迟
同样在settings.py中配置一下该下载中间件,如4.6.3所示。
5 Scrapy的断点调试
为了方便Scrapy的断点调试,在scrapy.cfg同级目录下新建一个run.py文件:
1 from scrapy.cmdline import execute 2 3 4 def main(): 5 spider_name = 'lagoucrawler' 6 cmd_string = 'scrapy crawl {spider_name}'.format(spider_name=spider_name) 7 execute(cmd_string.split()) 8 9 10 if __name__ == '__main__': 11 main()
这样就可以通过Debug run.py,来进行Scrapy项目的断点调试。
6 项目代码
完整代码的Github地址:https://github.com/StrivePy/LaGouCrawler/tree/recode/LagouCrawler
7 参考资料
- Selenium官方文档:https://selenium-python.readthedocs.io/
- Selenium+Python手册大全:https://www.jianshu.com/nb/25338984
- Scrapy官方文档:https://docs.scrapy.org/en/latest/
- Scrapy中文文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/
- 如何让你的Scrapy爬虫不被ban(1):http://www.cnblogs.com/rwxwsblog/p/4575894.html
- 如何让你的Scrapy爬虫不被ban(2):http://www.cnblogs.com/rwxwsblog/p/4582127.html
- 阿布云官方接入文档:https://www.abuyun.com/http-proxy/dyn-manual.html
- 阿布云Python3使用教程:https://www.jianshu.com/p/90d57e7a545a