| ylbtech-开发-日常工具:TFS(Team Foundation Server) |
TFS(Team Foundation Server)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
| 1.返回顶部 |
1、
- 外文名:Team Foundation Server
- 简 称:TFS
- 属 性:分布式文件系统
目录
- 1 特性
- 2 总体结构
- ▪ NameServer
- ▪ DataServer
- 3 平滑扩容
- 4 存储机制
- 5 容错机制
- ▪ 集群容错
- ▪ NameServer容错
- ▪ DataServer容错
2、
| 2.返回顶部 |
1、
特性
1. 采用扁平化的数据组织结构
2. 使用HA架构和平滑扩容
3. 支持多种客户端
4. 支持大小文件存储
5. 可为外部提供高可靠和高并发的存储访问
6. 支持大文件功能
7. Resource Center Server,用于管理TFS集群的用户资源配置
8. TFS服务程序开发框架,统一TFS网络客户端库,并新增异步回调功能
9. 优化数据流,让写请求尽可能均匀的分布在不同的DataServer
总体结构
一个TFS集群由两个NameServer节点(一主一备)和多个!DataServer节点组成。这些服务程序都是作为一个用户级的程序运行在普通Linux机器上的。
在TFS中,将大量的小文件(实际数据文件)合并成为一个大文件,这个大文件称为块(Block), 每个Block拥有在集群内唯一的编号(Block Id), Block Id在NameServer在创建Block的时候分配,NameServer维护block与DataServer的关系。Block中的实际数据都存储在DataServer上。而一台DataServer服务器一般会有多个独立DataServer进程存在,每个进程负责管理一个挂载点,这个挂载点一般是一个独立磁盘上的文件目录,以降低单个磁盘损坏带来的影响。
NameServer
NameServer主要功能是: 管理维护Block和!DataServer相关信息,包括DataServer加入,退出, 心跳信息, block和!DataServer的对应关系建立,解除。正常情况下,一个块会在DataServer上存在, 主NameServer负责Block的创建,删除,复制,均衡,整理, NameServer不负责实际数据的读写,实际数据的读写由DataServer完成。
DataServer
DataServer主要功能是: 负责实际数据的存储和读写。
同时为了考虑容灾,NameServer采用了HA结构,即两台机器互为热备,同时运行,一台为主,一台为备,主机绑定到对外vip,提供服务;当主机器宕机后,迅速将vip绑定至备份NameServer,将其切换为主机,对外提供服务。图中的HeartAgent就完成了此功能。
TFS的块大小可以通过配置项来决定,通常使用的块大小为64M。TFS的设计目标是海量小文件的存储,所以每个块中会存储许多不同的小文件。DataServer进程会给Block中的每个文件分配一个ID(File ID,该ID在每个Block中唯一),并将每个文件在Block中的信息存放在和Block对应的Index文件中。这个Index文件一般都会全部load在内存,除非出现DataServer服务器内存和集群中所存放文件平均大小不匹配的情况。
另外,还可以部署一个对等的TFS集群,作为当前集群的辅集群。辅集群不提供来自应用的写入,只接受来自主集群的写入。当前主集群的每个数据变更操作都会重放至辅集群。辅集群也可以提供对外的读,并且在主集群出现故障的时候,可以接管主集群的工作。
平滑扩容
原有TFS集群运行一定时间后,集群容量不足,此时需要对TFS集群扩容。由于DataServer与NameServer之间使用心跳机制通信,如果系统扩容,只需要将相应数量的新DataServer服务器部署好应用程序后启动即可。这些DataServer服务器会向NameServer进行心跳汇报。NameServer会根据DataServer容量的比率和DataServer的负载决定新数据写往哪台DataServer的服务器。根据写入策略,容量较小,负载较轻的服务器新数据写入的概率会比较高。同时,在集群负载比较轻的时候,NameServer会对DataServer上的Block进行均衡,使所有!DataServer的容量尽早达到均衡。
进行均衡计划时,首先计算每台机器应拥有的blocks平均数量,然后将机器划分为两堆,一堆是超过平均数量的,作为移动源;一类是低于平均数量的,作为移动目的。
移动目的的选择:首先一个block的移动的源和目的,应该保持在同一网段内,也就是要与另外的block不同网段;另外,在作为目的的一定机器内,优先选择同机器的源到目的之间移动,也就是同台!DataServer服务器中的不同!DataServer进程。
当有服务器故障或者下线退出时(单个集群内的不同网段机器不能同时退出),不影响TFS的服务。此时!NameServer会检测到备份数减少的Block,对这些Block重新进行数据复制。
当有服务器故障或者下线退出时(单个集群内的不同网段机器不能同时退出),不影响TFS的服务。此时!NameServer会检测到备份数减少的Block,对这些Block重新进行数据复制。
在创建复制计划时,一次要复制多个block, 每个block的复制源和目的都要尽可能的不同,并且保证每个block在不同的子网段内。因此采用轮换选择(roundrobin)算法,并结合加权平均。
由于DataServer之间的通信是主要发生在数据写入转发的时候和数据复制的时候,集群扩容基本没有影响。假设一个Block为64M,数量级为1PB。那么NameServer上会有 1 * 1024 * 1024 * 1024 / 64 = 16.7M个block。假设每个Block的元数据大小为0.1K,则占用内存不到2G。
存储机制
在TFS中,将大量的小文件(实际用户文件)合并成为一个大文件,这个大文件称为块(Block)。TFS以Block的方式组织文件的存储。每一个Block在整个集群内拥有唯一的编号,这个编号是由NameServer进行分配的,而DataServer上实际存储了该Block。在!NameServer节点中存储了所有的Block的信息,一个Block存储于多个!DataServer中以保证数据的冗余。对于数据读写请求,均先由!NameServer选择合适的!DataServer节点返回给客户端,再在对应的!DataServer节点上进行数据操作。!NameServer需要维护Block信息列表,以及Block与!DataServer之间的映射关系,其存储的元数据结构如下:
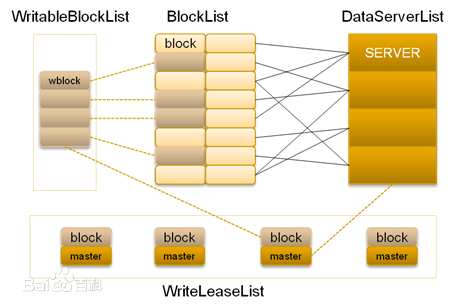
在!DataServer节点上,在挂载目录上会有很多物理块,物理块以文件的形式存在磁盘上,并在!DataServer部署前预先分配,以保证后续的访问速度和减少碎片产生。为了满足这个特性,!DataServer现一般在EXT4文件系统上运行。物理块分为主块和扩展块,一般主块的大小会远大于扩展块,使用扩展块是为了满足文件更新操作时文件大小的变化。每个Block在文件系统上以“主块+扩展块”的方式存储。每一个Block可能对应于多个物理块,其中包括一个主块,多个扩展块。
在DataServer端,每个Block可能会有多个实际的物理文件组成:一个主Physical Block文件,N个扩展Physical Block文件和一个与该Block对应的索引文件。Block中的每个小文件会用一个block内唯一的fileid来标识。!DataServer会在启动的时候把自身所拥有的Block和对应的Index加载进来。
在DataServer端,每个Block可能会有多个实际的物理文件组成:一个主Physical Block文件,N个扩展Physical Block文件和一个与该Block对应的索引文件。Block中的每个小文件会用一个block内唯一的fileid来标识。!DataServer会在启动的时候把自身所拥有的Block和对应的Index加载进来。
容错机制
集群容错
TFS可以配置主辅集群,一般主辅集群会存放在两个不同的机房。主集群提供所有功能,辅集群只提供读。主集群会把所有操作重放到辅集群。这样既提供了负载均衡,又可以在主集群机房出现异常的情况不会中断服务或者丢失数据。
NameServer容错
Namserver主要管理了DataServer和Block之间的关系。如每个!DataServer拥有哪些Block,每个Block存放在哪些DataServer上等。同时,NameServer采用了HA结构,一主一备,主NameServer上的操作会重放至备NameServer。如果主NameServer出现问题,可以实时切换到备NameServer。
另外NameServer和DataServer之间也会有定时的heartbeat,DataServer会把自己拥有的Block发送给!NameServer。NameServer会根据这些信息重建DataServer和Block的关系。
另外NameServer和DataServer之间也会有定时的heartbeat,DataServer会把自己拥有的Block发送给!NameServer。NameServer会根据这些信息重建DataServer和Block的关系。
DataServer容错
TFS采用Block存储多份的方式来实现!DataServer的容错。每一个Block会在TFS中存在多份,一般为3份,并且分布在不同网段的不同DataServer上。对于每一个写入请求,必须在所有的Block写入成功才算成功。当出现磁盘损坏DataServer宕机的时候,TFS启动复制流程,把备份数未达到最小备份数的Block尽快复制到其他DataServer上去。 TFS对每一个文件会记录校验crc,当客户端发现crc和文件内容不匹配时,会自动切换到一个好的block上读取。此后客户端将会实现自动修复单个文件损坏的情况。
并发机制
对于同一个文件来说,多个用户可以并发读。
现有TFS并不支持并发写一个文件。一个文件只会有一个用户在写。这在TFS的设计里面对应着是一个block同时只能有一个写或者更新操作。
现有TFS并不支持并发写一个文件。一个文件只会有一个用户在写。这在TFS的设计里面对应着是一个block同时只能有一个写或者更新操作。
文件名结构
TFS的文件名由块号和文件号通过某种对应关系组成,最大长度为18字节。文件名固定以T开始,第二字节为该集群的编号(可以在配置项中指定,取值范围 1~9)。余下的字节由Block ID和File ID通过一定的编码方式得到。文件名由客户端程序进行编码和解码,它映射方式如下图:
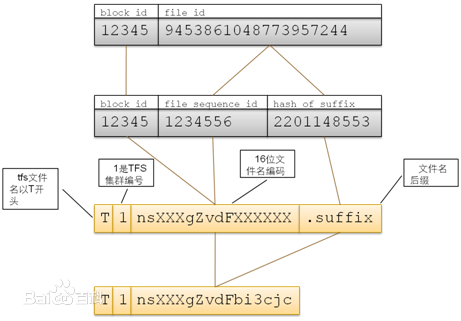
TFS客户程序在读文件的时候通过将文件名转换为BlockID和FileID信息,然后可以在!NameServer取得该块所在!DataServer信息(如果客户端有该Block与!DataServere的缓存,则直接从缓存中取),然后与!DataServer进行读取操作。
TFS客户程序在读文件的时候通过将文件名转换为BlockID和FileID信息,然后可以在!NameServer取得该块所在!DataServer信息(如果客户端有该Block与!DataServere的缓存,则直接从缓存中取),然后与!DataServer进行读取操作。
2、
| 3.返回顶部 |
| 4.返回顶部 |
| 5.返回顶部 |
1、
2、
| 6.返回顶部 |
| 作者:ylbtech 出处:http://ylbtech.cnblogs.com/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 |