课程目标
- HashMap的构造方法、合适的遍历、复制转换等
- HashMap底层原理
- HashMap、TreeMap、LinkedHashMap比较
- Map各实现类的速度比较
1. Map
通用方法
-
V put(K key, V value)
存入Map中一个key/value映射 -
V get(Object key)
返回指定键所映射的值 -
int size()
返回map中键值映射的数量 -
V remove(Object key)
从map中删除一个键的映射 -
boolean containsKey(Object key)
判断是否包含指定的key -
boolean containsValue(Object value)
判断是否包含指定的value
2. HashMap
构造方法
- HashMap()
默认长度:16
默认负载因子:0.75
负载因子:表示HashMap的使用程度,默认情况下长度16,负载因子0.75表示当HashMap的元素数量超过16的75%时会触发扩容操作,扩容1倍为32。
需要注意的是,扩容后会重新计算HashMap中元素的位置,按照长度为32重新进行计算和排列元素。
因此一个默认HashMap的有效存储空间为160.75=12。
Map map = new HashMap();
等价于
Map map = new HashMap(16, 0.75f);
- HashMap(int initialCapacity)
initialCapacity:指定初始化大小
例如:
Map map = new HashMap(3);
在构造方法中传入3,但实际上并不是创建一个长度为3的Map。
HashMap会对传入的参数进行调整,调整为大于3的最小的2的n次方,即4。
所以最后会创建一个长度为4的HashMap。
当传入5时,会创建一个长度为2^3=8的HashMap。
- HashMap(int initialCapacity, float loadFactor)
loadFactor:负载因子,用来指定map在什么情况下会扩容
{{uploading-image-615576.png(uploading...)}}
注意:在索引为8的位置,存放着120和40,由于发生了碰撞,这种情况下,这两个元素仅算占用1个存储空间。
基本用法
Map<String, Integer> map = new HashMap<>(5);
map.put("zhang1", 2);
map.put("zhang2", 4);
map.put("zhang3", 4);
map.put("zhang4", 1);
map.put("zhang5", 5);
Entry结构
static class Entry<K, V> implemnts Map.Entry<K, V> {
final K key;
V value;
Entry<K, V> next;
final int hash;
}
Map中的每一个键值对都是一个Entry。
遍历HashMap与性能分析
keySet
for (String key : map.keySet()) {
System.out.println(key + " -- " + map.get(key));
}
values
for (Integer value : map.values()) {
System.out.println("value : " + value);
}
entrySet
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + " --- " + entry.getValue());
}
Iterator
Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, Integer> entry = it.next();
System.out.println(entry.getKey() + " +++ " + entry.getValue());
}
性能分析
测试例程
public class TestMap {
public static void main(String[] args) {
Map<String, Integer> map = initialMap();
long start;
long end;
Integer test;
start = System.currentTimeMillis();
for (String key : map.keySet()) {
// System.out.println(key + " -- " + map.get(key));
test = map.get(key);
}
end = System.currentTimeMillis();
System.out.println("keySet:" + (end - start));
start = System.currentTimeMillis();
for (Integer value : map.values()) {
// System.out.println("value : " + value);
test = value;
}
end = System.currentTimeMillis();
System.out.println("values:" + (end - start));
start = System.currentTimeMillis();
for (Map.Entry<String, Integer> entry : map.entrySet()) {
// System.out.println(entry.getKey() + " --- " + entry.getValue());
test = entry.getValue();
}
end = System.currentTimeMillis();
System.out.println("entrySet:" + (end - start));
start = System.currentTimeMillis();
Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, Integer> entry = it.next();
// System.out.println(entry.getKey() + " +++ " + entry.getValue());
test = entry.getValue();
}
end = System.currentTimeMillis();
System.out.println("iterator:" + (end - start));
}
public static Map<String, Integer> initialMap() {
Map<String, Integer> map = new HashMap<>();
String[] strings = new String[]{"a", "b", "c", "d", "e", "f", "g", "h", "i", "j"};
String key;
Integer value;
for (int i = 0; i <= 1000000; i++) {
int x = (int) Math.random() * 10;
key = strings[x] + i * 100;
value = i;
map.put(key, value);
}
return map;
}
}
处理1千万个数的结果:
keySet:454
values:309
entrySet:321
iterator:327
keySet:557
values:410
entrySet:441
iterator:442
多次运行后结果大致在同一的区间。
结论:
- keySet效率最差。
- 若只需要获取value,用values最好。
- entrySet和iterator效率差不多。
原理
例程如下:
Map<Integer, String> map = new HashMap<>();
map.put(120, "a");
map.put(37, "a");
map.put(61, "a");
map.put(40, "a");
map.put(92, "a");
map.put(87, "a");
System.out.println(map);
输出结果:
{37=a, 87=a, 120=a, 40=a, 92=a, 61=a}
HashMap存储顺序图示
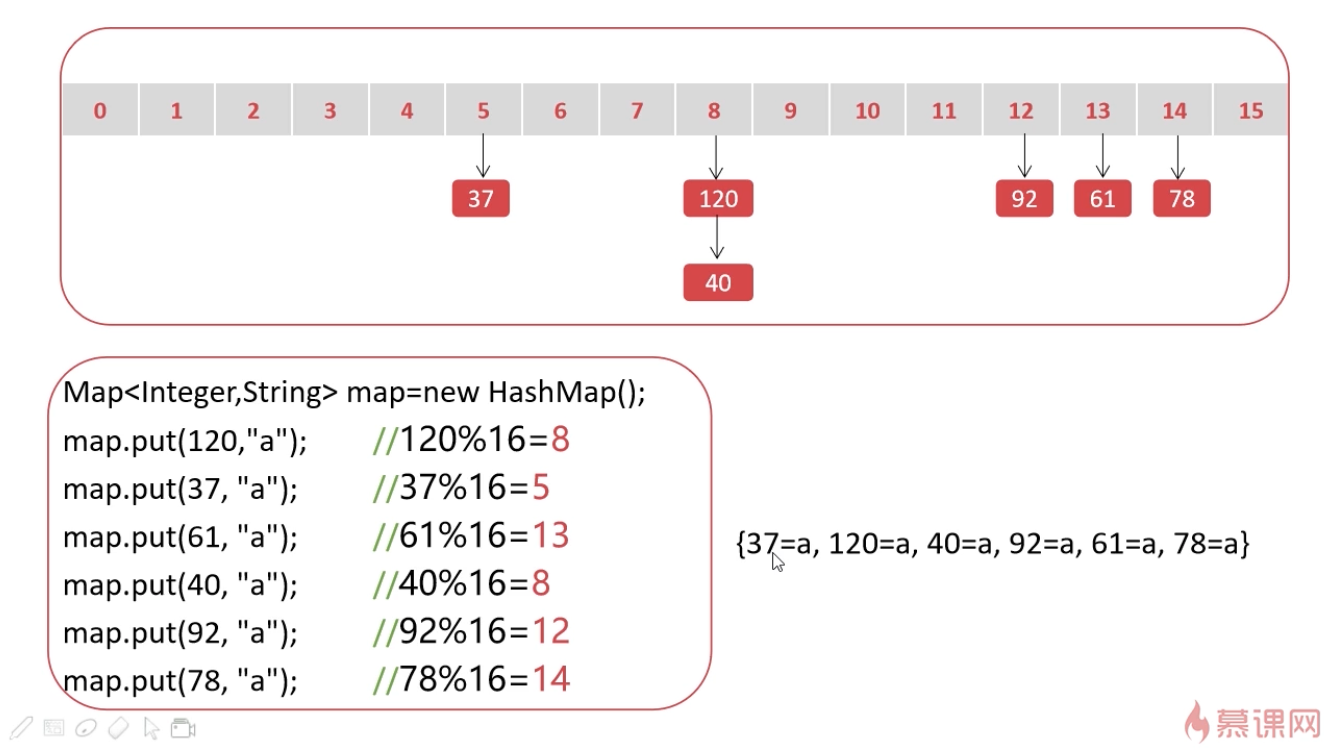
解释:
- 已知,HashMap的初始容量默认为16。
- 根据例程的执行结果可知,HashMap遍历输出的顺序与put顺序无关。
- HashMap中Entry的存储位置和容量有关。
- 当容量为16时,key=120的Entry的存放位置就是120%16=8
- 实际上,在HashMap的底层使用位运算的方式来计算余数。(位运算效率更高,这里为了方便理解,使用取余运算符)
- 在上述例程中,HashMap按照put顺序依次计算key的余数,然后依次将Entry放入对应的位置。
- 需要注意的是,120%16=8与40%16=8 两个key的余数相同,这就产生了哈希碰撞。
- 为了将key=40的Entry放入HashMap中,这里需要用到Entry的next属性,key=120的Entry的next指向key=40的Entry。
- 而key=40的Entry的next为空,因为后续没有发生碰撞。
上述例程说明了当key为整数时,元素在HashMap中的存放位置,下面将说明当key为字符串时元素是如何存放的。
Map<String, Integer> map = new HashMap<>();
map.put("yuwen", 90);
map.put("yinyue", 78);
map.put("tiyu", 88);
map.put("shuxue", 60);
map.put("meishu", 98);
System.out.println(map);
输出
{yuwen=90, shuxue=60, tiyu=88, yinyue=78, meishu=98}
关键方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
用Object的hashCode方法将key转化成hash码后进行优化,并得到优化后的hash码。
例:字符串"yuwen"优化后的hash码是115347492。
static int indexFor(int h, int length)
对优化后的hash码进行取址(取余运算),确定在HashMap中的位置。
例:115347492(h)在长度为16(length)的HashMap中,取址的坐标为4( 115347492%16=4)。
所以,在调用HashMap的put方法时,先计算key的hash值,然后使用indexFor得到坐标。
HashMap常用方法
- 判断是否为空
boolean isEmpty();
- 删除节点
V remove(Object key); // 返回key对应的value
boolean remove(Object key, Object value); // 需要匹配value
- 清空HashMap对象
void clear();
- 判断是否有某个key
boolean containsKey(Object key);
- 判断是否有某个value
boolean containsValue(Object value);
- 替换HashMap中某个key的value
V replace(K key, V value);
boolean replace(K key, V oldValue, V newValue); // 需要匹配旧值
- forEach遍历HashMap
例:
map.forEach((key, value) -> System.out.println(key + " : " + value));
- 尝试获取key值,如果没有就返回一个默认值
V getOrDefault(Object key, V defaultValue)
// TODO 2021年1月19日23:50:36 更新 LinkedHashMap
3. LinkedHashMap
HashMap是无序的,LinkedHashMap是在HashMap基础上,通过实现一个双向链表来保证Map的顺序性。
继承了HashMap,实现了Map接口。
因此LinkedHashMap可以使用HashMap的方法。
LinkedHashMap与HashMap性能比较
为比较HashMap与LinkedHashMap的性能,将上文中的HashMap遍历1千万个元素的例程改为使用LinkedHashMap。
使用LinkedHashMap运行结果:
keySet:763
values:119
entrySet:121
iterator:125
使用HashMap的运行结果:
keySet:557
values:410
entrySet:441
iterator:442
比较两个运行结果可以发现:除使用keySet方法时HashMap更省时外,在使用LinkedHashMap遍历map明显效率更高。
LinkedHashMap的特有方法
LinkedHashMap有2种输出顺序:
按录入顺序输出
Map<String, String> map = new LinkedHashMap<>();
map.put("a1", "x");
map.put("b1", "x");
map.put("c1", "x");
map.put("d1", "x");
System.out.println(map);
输出结果:
{a1=x, b1=x, c1=x, d1=x}
按使用顺序输出
设置LinkedHashMap按使用顺序输出的方式是在初始化map时,手动对构造方法进行设置,第三个参数是boolean accessOrder,当设置为true时就是按使用顺序输出,默认false。
Map<String, String> map = new LinkedHashMap<>(16, 0.75f, true);
map.put("a1", "x");
map.put("b1", "x");
map.put("c1", "x");
map.put("d1", "x");
map.get("b1");
System.out.println(map);
输出结果:
{a1=x, c1=x, d1=x, b1=x}
可以看出key为b1的元素使用后,被移动到了map的最后。
使用LinkedHashMap实现LRU
Least Recently Used的缩写,即 最近最少使用。
LRU是一种缓存淘汰算法,最近的保留,最早的清除。
自定义LRUMap类型
public class LRUMap<K, V> extends LinkedHashMap<K, V> {
/**
* 缓存容量
*/
private int maxSize;
public LRUMap(int maxSize) {
super(16, 0.75f, true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > this.maxSize;
}
}
LRUMap继承LinkedHashMap。
maxSize表示这个缓存的容量,并使用构造方法将maxSize赋值。
最后覆写父类LinkedHashMap的removeEldestEntry方法,判断当前LRUMap对象的大小是否超过最大容量,如果超过容量,就返回true。
父类LinkedHashMap的removeEldestEntry方法如下:

调用removeEldestEntry的afterNodeInsertion方法如下:
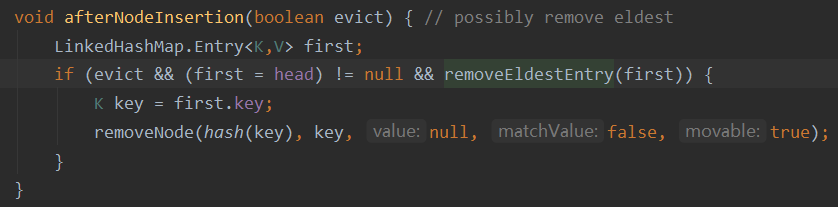
可以看出该方法默认返回false,afterNodeInsertion不会删除最早的元素。
在LRUMap中通过覆写removeEldestEntry,将超过我们定义的容量的最早的元素删除。
测试代码:
Map<String, String> LRU = new LRUMap(3);
LRU.put("x1", "1");
LRU.put("x2", "1");
LRU.put("x3", "1");
LRU.put("x4", "1");
LRU.put("x5", "1");
System.out.println(LRU);
输出结果如下:
{x3=1, x4=1, x5=1}
保留了最新put的3个元素,丢弃了x1和x2。
调用流程描述:
- LRU.put调用了LinkedHashMap的put,但LinkedHashMap没有实现put方法,实际调用的是HashMap的put
- HashMap的put调用了putVal
- putVal最后调用了afterNodeInsertion
- afterNodeInsertion中调用了removeEldestEntry(即LRUMap中覆写的removeEldestEntry)
- removeEldestEntry对map中的元素数量进行判断,超过初始化时设置的容量则返回true
- 由于removeEldestEntry返回true,则调用removeNode删除头部元素。
从put x4起,每次LRU头部的元素都会被删除,然后将新元素加到尾部,LRU的容量始终保持为3。
想知道更多具体的信息,自行debug。
4. TreeMap
TreeMap也是有序的,但不是按输入顺序或使用顺序,而是按照自然数的升序或降序排列。
默认升序,而降序需要自定义比较器。
默认TreeMap:
Map<String, String> map = new TreeMap<>();
map.put("dx", "1");
map.put("bx", "1");
map.put("ax", "1");
map.put("cx", "1");
System.out.println(map);
结果:
{ax=1, bx=1, cx=1, dx=1}
自定义比较器对元素进行降序:
Map<String, String> map = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
map.put("dx", "1");
map.put("bx", "1");
map.put("ax", "1");
map.put("cx", "1");
System.out.println(map);
TreeMap、LinkedHashMap与HashMap性能比较
为比较TreeMap、HashMap与LinkedHashMap的性能,将上文中的HashMap遍历1千万个元素的例程改为使用TreeMap。
使用LinkedHashMap运行结果:
keySet:763
values:119
entrySet:121
iterator:125
使用HashMap的运行结果:
keySet:557
values:410
entrySet:441
iterator:442
使用TreeMap的运行结果:
keySet:1951
values:305
entrySet:292
iterator:298
从上述3种Map的遍历耗时看,keySet方式遍历的性能最差,其他3个遍历方式在同样的Map下差别不大。
在实际中,应该根据数据量、数据的特点选择合适的实现类。