数据库
数据库简单的来说就是存储数据的仓库。这个仓库是按照一定的数据结构(是数据之间的组织形式或数据之间的联系)来进行组织和存储数据的。
而当今的互联网中,最常用的数据库模型主要是两种,即关系型数据库和非关系型数据库。
Mysql数据库的基础
关系型数据库
关系型数据库模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式)。在关系数据库中,对数据的操作几乎全部建立在一个或多个关系表格上,通过对这些关联表的表格分类、合并、连接或选取等运算来实现数据的管理。
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
mysql是什么
#mysql就是一个基于socket编写的C/S架构的软件 #客户端软件 mysql自带:如mysql命令,mysqldump命令等 python模块:如pymysql
数据库管理软件分类

#分两大类:
关系型:如sqllite,db2,oracle,access,sql server,MySQL,注意:sql语句通用
非关系型:mongodb,redis,memcache
#可以简单的理解为:
关系型数据库需要有表结构
非关系型数据库是key-value存储的,没有表结
window下的配置文件
强调:配置文件中的注释可以有中文,但是配置项中不能出现中文


#在mysql的解压目录下,新建my.ini,然后配置 #1. 在执行mysqld命令时,下列配置会生效,即mysql服务启动时生效 [mysqld] ;skip-grant-tables port=3306 character_set_server=utf8 default-storage-engine=innodb innodb_file_per_table=1 #解压的目录 basedir=E:mysql-5.7.19-winx64 #data目录 datadir=E:my_data #在mysqld --initialize时,就会将初始数据存入此处指定的目录,在初始化之后,启动mysql时,就会去这个目录里找数据 #2. 针对客户端命令的全局配置,当mysql客户端命令执行时,下列配置生效 [client] port=3306 default-character-set=utf8 user=root password=123 #3. 只针对mysql这个客户端的配置,2中的是全局配置,而此处的则是只针对mysql这个命令的局部配置 [mysql] ;port=3306 ;default-character-set=utf8 user=egon password=4573 #!!!如果没有[mysql],则用户在执行mysql命令时的配置以[client]为准 my.ini
ubuntu安装MySQL8.0
https://blog.csdn.net/qq_42468130/article/details/88595418
统一字符编码
show variables like 'char%'; 查看编码
#1. 修改配置文件 [mysqld] default-character-set=utf8 [client] default-character-set=utf8 [mysql] default-character-set=utf8 #mysql5.5以上:修改方式有所改动 [mysqld] character-set-server=utf8 collation-server=utf8_general_ci [client] default-character-set=utf8 [mysql] default-character-set=utf8 #2. 重启服务 #3. 查看修改结果: s show variables like '%char%'
登录mysql
初始状态下,管理员root,密码为空,默认只允许从本机登录localhost 设置密码 [root@egon ~]mysqladmin -uroot password "123" #设置初始密码 由于原密码为空,因此-p可以不用 [root@egon ~] mysqladmin -uroot -p"123" password "456" #修改mysql密码,因为已经有密码了,所以必须输入原密码才能设置新密码 命令格式: [root@egon ~] mysql -h远程myslq服务器的ip地址 -u用户名 -p密码 #远程登录 [root@egon ~]#mysql -uroot -p123 #本地登录 [root@egon ~] mysql #以root用户登录本机,密码为空
sql语句
有了mysql这个数据库软件,就可以将程序员从对数据的管理中解脱出来,专注于对程序逻辑的编写
mysql服务端软件即mysqld帮我们管理好文件夹以及文件,前提是作为使用者的我们,需要下载mysql的客户端,或者其他模块来连接到mysqld,然后使用mysql软件规定的语法格式去提交自己命令,实现对文件夹或文件的管理。该语法即sql(Structured Query Language 即结构化查询语言)
sql:结构化查询语言,它是关系型数据库的操作语言。
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型: #1、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER #2、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT #3、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
sql 语句的执行顺序:
(1) FROM <left_table>
(2) ON <join_condition>
(3) <join_type> JOIN <right_table>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(7) SELECT
(8) DISTINCT <select_list>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
操作数据库
操作数据库(文件夹)
首先最先做的事是:修改字符编码为utf8: set names 'utf8'
查看数据库的个数: show databases;
创建数据库:create datebase 数据库名 character set ='utf8';##一定不要加- 数据库的字符编码
查看某个数据库的信息: show create database 数据库名;
删除数据库: drop database 数据库名; #如果这个库不存在会报错
修改数据库编码: alter database 数据库名 character set utf8 ; #mysql 有很大的兼容性你也可以写成这样character set =utf8
或character set ='utf8' 还可以写为 charset utf8
选择数据库名:use 数据库名 #要先选择某个数据库才能操作数据库中的表
当前处于哪个数据库: select database();
操作表(文件)
查看表的字段信息: describe 表名 ; #查看表结构,可简写为desc 表名
mysql> desc t1; +-------+---------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(8) | NO | | | | +-------+---------+------+-----+---------+----------------+ 2 rows in set (0.01 sec)
查看表的创建信息:
mysql> show create table t1; +-------+---------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+---------------------------------------------------------------------------------------------------------------------------------------------------+ | t1 | CREATE TABLE `t1` ( `id` int(11) NOT NULL auto_increment, `name` char(8) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | +-------+---------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
创建表:create table 表名(列名1 指定该列的类型 是否可以为空,列名2 指定该列的类型 是否可以为空)
create table students( id int unsigned not null auto_increment primary key, name char(8) not null, sex char(4) not null, age tinyint unsigned not null, tel char(13) null default "-" #默认值这样写 );
以 "id int unsigned not null auto_increment primary key" 行进行介绍:
"id" 为列的名称;
"int" 指定该列的类型为 int(取值范围为 -8388608到8388607), 在后面我们又用
"unsigned" 加以修饰, 表示该类型为无符号型, 此时该列的取值范围为 0到16777215;
"not null" 说明该列的值不能为空, 必须要填, 如果不指定该属性, 默认可为空;
"auto_increment" 需在整数列中使用, 其作用是在插入数据时若该列为 NULL,MySQL将自动产生一个比现存值更大的唯一标识符值。在每张表中仅能有一个这样的值且所在列必须为索引列。
"primary key" 表示该列是表的主键, primary key 的特点是唯一且不为空的值, innodb存储引擎就是根据主键来自动搜索结果的. 主键增加表的查询效率
最后的分号建议不写上,因为以后用python没有这个冒号
复制其他表:
#只复制表结构和内容
1. create table 新表名 select * from 旧表名 #这种方法只复制表结构和表内容,但是不会复制其主键和自增,需要自己亲自增加用alter 方法.
#只复制表结构
2. create table 新表名 select* from 旧表名 where 1=2 #这样就只会复制表结构因为1永远不会等二.
修改表:
#修改表名: alter table oldname rename to newname;
#添加字段: alter table 表名 add name varchar(10) not null 这样写name直接添加到最后
alter table 表名 add name varchar(10) not null after id #把name字段添加到id字段之后
alter table 表名 add name varchar(10) not null first #把name字段添加到最前面
#修改列类型: alter table 表名 modify name varchar(4) #增加约束都用modify
删除:
alter table 表名 drop 字段名;#删除字段 drop table 表名 #删除表
清空表:
delete from t1; #如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。
truncate table t1; #数据量大,删除速度比上一条快,且直接自增id从1开始.
下列情况truncate不可用:
1、由 FOREIGN KEY 约束引用的表。(您可以截断具有引用自身的外键的表。)
3、通过使用事务复制或合并复制发布的表。
创建表后硬盘上会出现3个文件
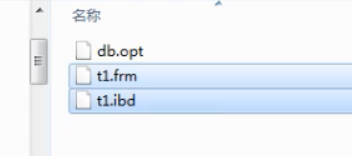
t1.frm 存放表结构
t1.idb 存放innodb类型的数据
操作表内容(记录)
增
#添加一条 into子句中没有出现的属性列,这些属性列将会取空值 insert [into ] 表名 [(字段1,字段2,字段3)] values (值1,值2,值3)#注意:[ ] 里的内容可以不写 #一次添加多条 insert into 表名 (字段1,字段2,字段3)values (值1,值2,值3),(值4,值5,值6);
# 不写属性列的添加
insert into 表名 values(值1,值2,值3)
插入子查询结果:
#对于每个系,求学生的平均年龄,并把结果存入到数据库中 1.首先创建一个新表, create table dept_age (sdept char(15), avg_age int) #2存入到数据库中 insert into dept_age(sdept,avg_abe) select sdept,avg(sage) from student group by sdept
删:
DELETE FROM 表名称 WHERE 条件字段=条件值; #这里是删除一整条信息,在MySQL中不能删除整条信息中的某个信息,只能删除某一条信息,delete 删除的是整条记录
改:
改:1 update 表名 set 字段名=更新值 where 条件字段=条件值;
查:
select [all|distinct]<目标表达式>
from 表名
select 子句中的《目标表达式》,不仅可以是表中的属性列,也可以是表达式
SELECT id,2014-id FROM KaiXing.take_cash_records where user_id =3 #结果

1. select * from 表名 #查看表中的所有内容,*这个最好不要用,占内存,用所有的字段名代替 *,这个写一次就行了,以后直接copy 2.select 所有的字段名 from 表名 where 字段名 = 值。
例题

如何查询字段内重复的内容有多少个?
select *,count(1) from liuran group by author

这里你也许有疑问 count(1)是什么意思?其实就是计算一共有多少符合条件的行。注意数字1并不是第一行的意思,你也可以count(任意数字)结果都是一样的,数据量很大时可以提高运行速度。它和count(*)的区别是count(*)
count(*),执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。
要求:count(1)>1的所有author 为?
select author from liuyan GROUP BY author HAVING count(1)>1

权限
创建用户:
创建用户create user 'egon'@'1.1.1.1' identified by '123'; 创建本地用户:create user 'alex'@'local host' identified by '123';
删除用户: drop user 'egon'@'1.1.1.1'
#授权:对文件夹,对文件,对文件某一字段的权限 查看帮助:help grant 常用权限有:select,update,alter,delete all可以代表除了grant之外的所有权限 #针对所有库的授权:*.* grant select on *.* to 'egon1'@'localhost' identified by '123'; #只在user表中可以查到egon1用户的select权限被设置为Y #针对某一数据库:db1.* grant select on db1.* to 'egon2'@'%' identified by '123'; #只在db表中可以查到egon2用户的select权限被设置为Y #针对某一个表:db1.t1 grant select on db1.t1 to 'egon3'@'%' identified by '123'; #只在tables_priv表中可以查到egon3用户的select权限 #针对某一个字段: mysql> select * from t3; +------+-------+------+ | id | name | age | +------+-------+------+ | 1 | egon1 | 18 | | 2 | egon2 | 19 | | 3 | egon3 | 29 | +------+-------+------+ grant select (id,name),update (age) on db1.t3 to 'egon4'@'localhost' identified by '123';
修改完权限: 要输入flush privileges 权限才能生成.
数据库设计
1.概念
1.有效存储数据
2.满足用户的多种需求
2.关系
1-1 :最少需要1张表
1-n :最少需要2张表
n-n :最少需要3张表 两张的主表的结构不变,用第三张表来表示这两张表的关系
3.数据库三范式即设计数据库所遵循的规范
第一范式
如果一个表的所有属性都是不可分的基本数据项,则成该表满足第一范式.
第一范式是对关系模式最起码的要求,不满足第一范式的数据库,不能成为关系型数据库
但是仅仅符合1NF的设计,仍然会存在数据冗余过大,插入异常,删除异常,修改异常的问题,例如对于表3中的设计:
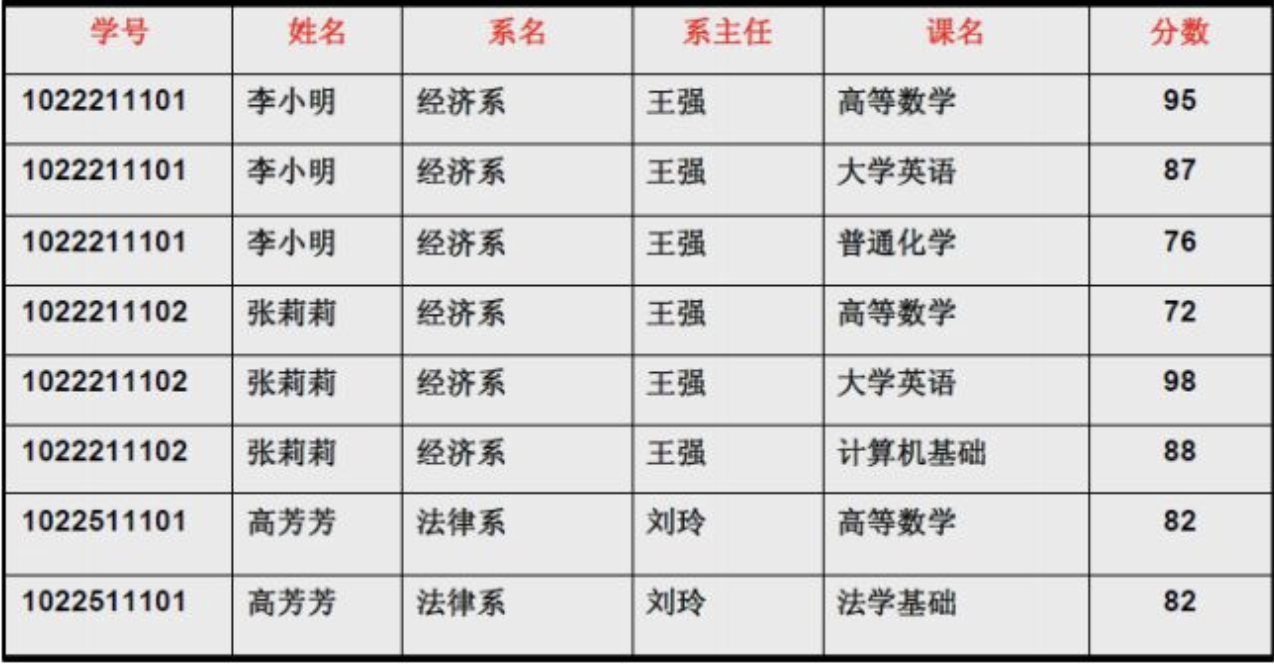
第二范式
要求表中所有非主键字段完全依赖主键,不能产生部分依赖.
什么是完全依赖?
作者:知乎用户
链接:https://www.zhihu.com/question/24696366/answer/29189700
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
例如:学生号确定了一个学生名.这就是学生名依赖了学生号
什么是部分依赖?
部分依赖指的就是使用联合主键后,每个字段仅依赖于联合主键中的某个字段,多个字段联合起来做主键,第二范式不建议使用联合主键,
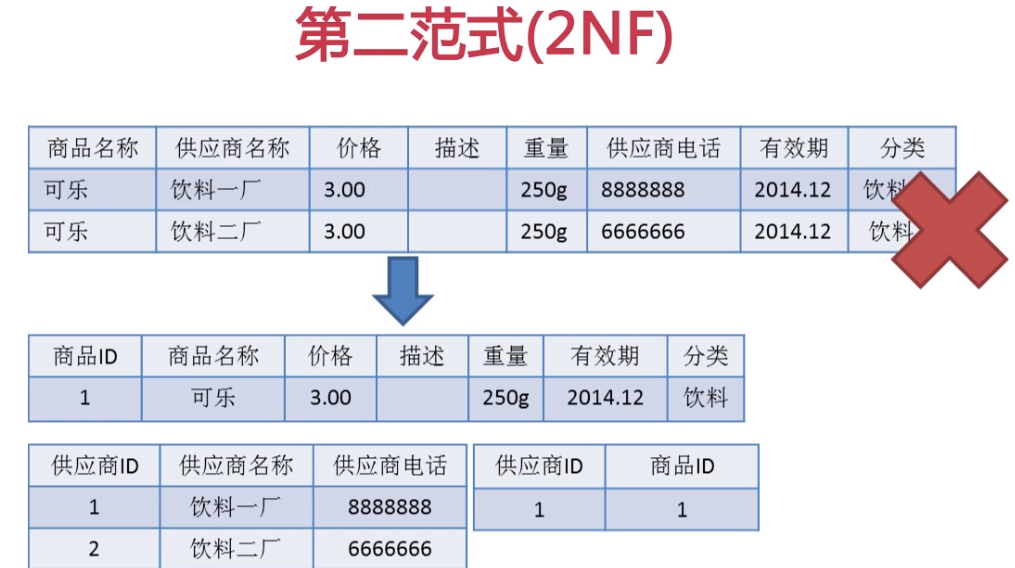
我们可以看出商品名称和供应商名称是联合主键, 但是供应商电话仅依赖于供应商名称这个字段这就叫做部分依赖
部分依赖有哪些缺点呢?
1. 插入异常.加入要插入一个供应商的信息,但是还不知道这个供应商卖的商品名称,这时候就不能插入,因为商品名称和供应商名称是联合主键都不能为空.
2.删除异常: 假设饮料二厂对应的可乐不卖了要删除了,这时候就会把饮料二厂的信息给删除掉,即不应删除的信息也被删除了
3.更新异常,这个在上边的例子上没有体现,在课本上有一个例子,某个学生只
直接去看知乎大神的解释吧更清楚些
如果和解决这种部分依赖呢?
继续分表
第三范式
第三范式(3NF) 3NF在2NF的基础之上,消除了非主属性对于主键的传递函数依赖。也就是说, 如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求。
#传递依赖 如果在一个表中,a->b ,b ->c 这称c传递依赖于a 例如 一个这样的表 有 学号 系名 系主任 这三个属性 学号是主键 学号->系名 同时 系名->系主任 对于系主任来说 传递依赖于学号

从上图,我们可以看到商品名称->分类 而 分类->分类描述,所以对于分类描述来说商品名称就是传递依赖
由此可见,符合3NF要求的数据库设计,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。当然,在实际中,往往为了性能上或者应对扩展的需要,经常 做到2NF或者1NF,但是作为数据库设计人员,至少应该知道,3NF的要求是怎样的。
BC范式
同长认为BC范式是修正的第三范式
视图
书上说:视图是从一个或几个基本表(或视图)导出的表。它与基本表不同,是一个虚表。数据库只存放视图的定义,而不存放视图的对应的数据,这些表仍然存放在原来的基本表中。所以一旦基本表中发生变化,视图中的数据也会发生变化。
视图是一个虚拟的表(非真实存在的)其本质是根据SQL语句获取的动态数据集并为其命名,用户使用时只需要使用名称就可以获取结果集,可以将该结果集当做表来用.
好处:
a.简化表之间的联结(把联结写在select中);
b、适当的利用视图可以更清晰地表达查询,将注意力集中在关系的数据上
c、过滤不想要的数据(select部分)视图能够对机密数据提供安全保护
d、使用视图计算字段值,如汇总这样的值。
注意: 视图并不在数据库中以存储的数据值集形式存在,它在硬盘中仅有一个结构文件并没有数据文件.
一般不建议使用视图,需要和DBA 打交道很麻烦
创建视图的语法: create view 视图名 as SQL语句 [with check option]
with check option 表示对视图进行增删改查操作时要满足视图定义中的谓语条件(即子查询中的条件表达式)
create view teacher_view as select tid from teacher where tname='李平老师';
使用视图:
select cname from course where teacher_id = (select tid from teacher_view);
create view is_student as select sno,sname,sage from student where sdept='IS' with check options # 由于在定义is_student视图的时候加上了with check options 以后再增删改操作时,mysql会自动加上where sdept="IS" 这个条件
其他语法和表的语法一样
触发器
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询。
应用场景:
当用户付完款后,触发购物车中的该商品订单的删除
触发器是mysql提供的一个功能,在现实中我们可以在代码中自己写一个类似触发器的功能,建议在现实中不要用该触发器,因为需要和DBA打交道。
# 插入前 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW BEGIN ... END # 插入后 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW BEGIN ... END # 删除前 CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW BEGIN ... END # 删除后 CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW BEGIN ... END # 更新前 CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW BEGIN ... END # 更新后 CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW BEGIN ... END
触发器的例子:
#准备表 CREATE TABLE cmd ( id INT PRIMARY KEY auto_increment, USER CHAR (32), priv CHAR (10), cmd CHAR (64), sub_time datetime, #提交时间 success enum ('yes', 'no') #0代表执行失败 ); CREATE TABLE errlog ( id INT PRIMARY KEY auto_increment, err_cmd CHAR (64), err_time datetime ); #创建触发器 delimiter // CREATE TRIGGER tri_after_insert_cmd AFTER INSERT ON cmd FOR EACH ROW BEGIN IF NEW.success = 'no' THEN #等值判断只有一个等号 INSERT INTO errlog(err_cmd, err_time) VALUES(NEW.cmd, NEW.sub_time) ; #必须加分号 END IF ; #必须加分号 END// delimiter ; #往表cmd中插入记录,触发触发器,根据IF的条件决定是否插入错误日志 INSERT INTO cmd ( USER, priv, cmd, sub_time, success ) VALUES ('egon','0755','ls -l /etc',NOW(),'yes'), ('egon','0755','cat /etc/passwd',NOW(),'no'), ('egon','0755','useradd xxx',NOW(),'no'), ('egon','0755','ps aux',NOW(),'yes'); #查询错误日志,发现有两条 mysql> select * from errlog; +----+-----------------+---------------------+ | id | err_cmd | err_time | +----+-----------------+---------------------+ | 1 | cat /etc/passwd | 2017-09-14 22:18:48 | | 2 | useradd xxx | 2017-09-14 22:18:48 | +----+-----------------+---------------------+ rows in set (0.00 sec) 插入后触发触发器
例子2
# 定义一个before 行级触发器,为教师表teacher 定义完整性规则"教师的工资不得低于4000元,低于4000元,自动改为4000元 create trigger insert_or_update_sal before insert or update on teacher referencing new row as newtuple for each row begin if(newtuple.job='教授')and (newtuple.sal<4000) then newtuple.sal:4000; end if; end
事务
事务(Transaction):是指一条或一组增删改SQL语句组成的执行单元,这个执行单元要么全部执行,要么不执行.
事务新的理解:事务将几个操作变成原子操作,这个几个操作要么全部执行,要么都不执行
事务在计算机教材中的概念:
所谓事务(transaction)就是一系列的信息交换.而这一系列的信息交换是不可分割的整体,也就是说要么所有的信息交换都完成,要么一次交换都不进行.
事务的特征即ACID:
原子性(atomicity).整个事务中的所有操作必须作为一个单元,要么所有操作全部完成或要么所有操作全部取消
一致性(consistency):事务在开始之前与结束之后,数据库都保持一致性.举个例子:你有1000元我有1000元,咱俩一共2000元,不管咱俩之间如何转账,咱俩加起来的钱必须是2000元,这就是一致性,
隔离性(isolation):一个事务所做的修改在最终提交以前,对其他事务是不可见的
持久性(durability):当事务完成后,该事务对数据库的更改,将持续的保存在数据库之中.
注意:在事务进程的过程中,没有结束后,sql语句是不会更改数据库的内容的.只是将历史记录存放在内存中.
事务开始的标志:任何一条DML语句的执行标志着事务的开启.
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型: #1、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER #2、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT #3、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
事务结束的标志: commit 或rollback
事务的提交和回滚
在mysql数据库管理系统中,默认情况下,事务是自动提交的,也就是说只要一条DML语句,就自动开启了事务并且提交了事务.
可以关闭这种自动提交事务功能:也就是手动提交事务:
start transaction ;
DML语句
commit;
#手动开启回滚出现异常,回滚到初始状态
start transaction; update user set balance=900 where name='wsb'; #买支付100元 update user set balance=1010 where name='egon'; #中介拿走10元 uppdate user set balance=1090 where name='ysb'; #卖家拿到90元,出现异常没有拿到 rollback; commit;
事务的四个特性之一隔离性(isolation):
- 事务A和事务B之间有一定的隔离性
- 隔离性有4个隔离级别
- read uncommitted 读未提交 事务A未提交的数据事务B可以读取到,这里读取到的数据叫做脏数据 ,这种隔离级别最低的,只是理论,数据库的默认隔离级别高于该级别
- read commited 读已提交 事务A提交的数据事务B可以读取到,这种隔离级别可以避免脏数据.这种隔离级别会导致不可重复读取相同的数据.oracle 默认隔离级别就是这个级别
-
不可重复读:这是描述在同一个事务中两条一模一样的 select 语句的执行结果的比较。如果前后执行的结果一样,则是可重复读;如果前后的结果可以不一样,则是不可重复读。
这个特性从字面上也能看出来。 不可重复读的模式下首先不会出现脏读,即读取的都是已提交的数据。在一个事务中,读取操作是不会加排他锁的,当下一条一模一样的 select 语句的执行时,
命中的数据集可能已经被其它事务修改了,这时候,还能读到相同的内容吗? 因此,要达到可重复读的效果,数据库需要做更多的事情,比如,对读取的数据行加共享锁,并保持到事务结束,以禁止其它事务修改它。这样会降低数据库的性能。
而隔离级别的串行则比可重复读更严格。一般数据库的的隔离级别只设置到读取已提交。这是兼顾了可靠性和性能的结果。
-
- repeatable read 可重复读 在可重复读中,该sql第一次读取到数据后,就将这些数据加锁(悲观锁),其它事务无法修改这些数据,就可以实现可重复读了。但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。需要Serializable隔离级别 ,读用读锁,写用写锁,读锁和写锁互斥,这么做可以有效的避免幻读、不可重复读、脏读等问题,但会极大的降低数据库的并发能力。 mysql默认隔离级别是可重复读.
-
幻想读:例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。
而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
-
- seriablizable 可串行化 事务A在操作数据库的时候,事务B只能排队等待也就是不影响事务A的结果,这种隔离级别一般用的很少,吞吐量低, 可避免幻象读,每次读取的都是数据库真实的数据.这是最高的隔离级别.
设置隔离级别
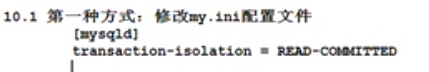
第二种方式:具体百度

慢查询
慢查询:mysql日志记录下查询超过指定时间的语句,我们将超过指定时间的sql查询语句称为慢查询.
那么指定的时间为多少呢?
show variables like "%long%"
结果: 10秒钟
+-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | long_query_time | 10 | +-----------------+-------+
设置指定时间
set long_query_time =1 #设置为1秒
查看慢日志是否开启:
show variables like '%quer%';
结果:
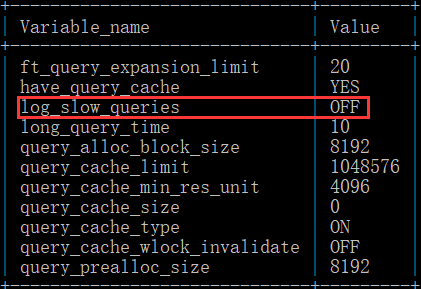
该显示没有开启慢日志
启动慢查询
修改配置文件
在安装目录下的my.ini文件中的mysqld 下
输入
[mysqld] log-slow-queries = /usr/local/mysql/var/slowquery.log #慢查询日志的存放位置,window下写绝对路径 long_query_time = 1 #单位是秒 log-queries-not-using-indexes #查询中如果没有使用到索引也会记录到日志中
然后开启慢日志用sql 自行百度
慢查询日志中记录超过指定格式的语句的格式

数据库的备份和回复
数据库备份
第一步:退出当前mysql客户端
第二步:选择需要导出的数据库和导出的位置
mysqldump -h 39.97.640.184 -p 3306 -u root -p Matrix --databases KaiXi > 2019_12_03_mysql.sql #> 后边跟要备份的地方和名字

如果出现错误了,就是再在路径上添加反斜杠
这样就成功了.
数据库的恢复
如果没有该数据库就提前创建数据库
第一步:创建数据库指定编码集
create database if not exists text default charset ='utf8'
第二步 使用数据库
use text
第三步: source +文件路径 这个一定要进入到数据库中
mysql> source /root/backup_kaixing_text/mysql_back/2019_12_03_mysql.sql