一、Analysis Services
Analysis Services是用于决策支持和BI解决方案的数据引擎。它提供报表和客户端中使用的分析数据。
它可在多用途数据模型中创建高性能查询结构,业务逻辑和KPI(企业关键绩效指标),该数据模型可由任何支持Analysis Services作为数据源的客户端程序访问。
多用途数据模型的创建:使用SQL Server Data Tools,并选择则表格或者多维和数据挖掘项目模板。
多用途数据模型的数据填充:通常是数据仓库
多为数据模型的使用:将它部署在特定服务器模式下运行数据库的Analysis Services实例。并使数据对应用程序连接的授权用户可用。
Analysis Services实例:
- 表格实例,运行表格模型
- 多维和数据挖掘实例,运行OLAP多维和数据挖掘模型(默认)
- PowerPivot for SharePoint,在SharePoint中运行PowerPivot或Excel数据模型。
二、SSAS体系结构
SSAS使用服务器组件和客户端组件为商业智能程序提供联机分析处理(OLAP)和数据挖掘功能。
- 服务器组件:SSAS的服务器组件是应用程序msmdsrv.exe,它作为Microsoft Windows服务来实现。支持来自一个计算机的多个实例,每个Analysis Services实例作为单独的Windows服务实例来实现。该应用程序包含很多组件其中包括XMLA监听组件,查询处理器组件等。
- 客户端组件:使用XMLA(XML for Analysis)与Analysis Services进行通信。XMLA基于SOAP的协议,用于发出命令和接收响应。查询语言:SQL,MDX(一种用于分析的行业标准查询语言),DMX(面向数据挖掘行业的查询语言)
- OLAP的支持:允许用户设计、创建和管理由多个数据源聚合的数据的多维结构。多维分析是OLAP的核心。
- 数据挖掘功能:允许用户设计、创建和处理数据挖掘模型。
三、多维数据分析的基本概念:
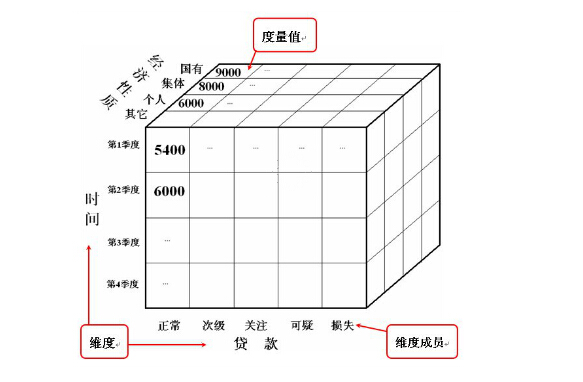
观察变量:如数字1000
度量值:没有上下文的数字是数据而不是信息,在寻找数字信息的过程中,首先要做的就是确定数据的度量值,如销售量、销售额等。通过增加标签,数字由数据变成了信息,这个标签就是元数据,将数据转换为信息的方式之一就是增加元数据。 度量值所在的表是事实数据表,常规多维数据集结构中只能有一个事实数据表。
维:人们观察客观世界的角度,是一种高层次的类型划分。维包含着层次关系,可以把多项重要的属性作为多个维。如时间维,产品维,模型维等。时间维,产品的销售量随着时间的变化。包含维度信息的表叫做维度表。
维度成员:维的一个取值称为维成员。如时间维上的某年某月某日。维成员不一定要在每个维层次上取值,如某年某月。
层次结构:维度成员的集合以及这些成员的相对位置。如时间维的年月日三个层次。地理维的州 国家 城市 区 街道 门牌号。
多维数据集(Cube):是一个数据集合,由数据仓库的子集构造。
维度表:包含某维度信息的表。维度表由主键和维属性组成,维属性是维度表的列属性;产品维度表:Prod_id, Product_Name, Category, Color, Size, Price 时间维度表:TimeKey, Season, Year, Month, Date。维度表的主键是整型值,为了节省事实表的存储空间。
事实表:包含度量值的表。如销售事实表:Prod_id(引用产品维度表), TimeKey(引用时间维度表), SalesAmount(销售总量,以货币计), Unit(销售量)
四、多维数据模型与结构
目前主流的数据仓库建模分为两种,一种是实体关系建模(Entity-Relationship Modeling)和维度建模(Dimension Modeling)。这里讨论维度建模,这一部分是数据仓库的核心,模型的优劣至关重要。

1、概念模型
概念模型也就是通常所说的需求分析。即在与用户交流的过程中,确定数据仓库索要访问的信息,这些信息包括当前、将来以及与历史用关的数据。
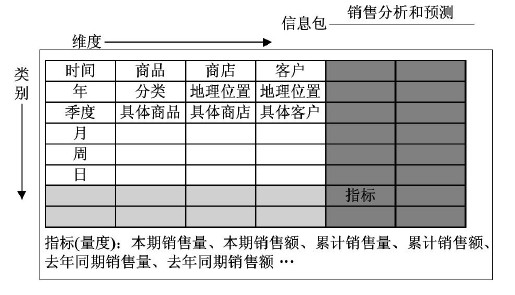
概念模型的目标是建立面向主题的信息包图。由于超立方体在表现上缺乏直观性,尤其当维度超过三维以后,数据的采集和表示都比较困难。因此信息包图的目标也就是在平面上展开超立方体,使用二维表格表现多维特征。利用信息包图设计概念模型需要确定三大内容,以产品的销售情况分析和预测主题分析为例:
a)确定维度
获取对电子商城中销售数据的多维特性分析,确定影响销售的维度:这里的时间、商品、商店、客户
b)确定类别
对每个维度进行分析,确定它与类别之间的传递和映射关系。如时间有年、季度、月、周、日等。商品有大类、小类、具体商品等。
c)确定指标
确定用户需要的指标体系,指标是用户最关系的信息。以销售情况作为依据确定相关的销售指标,如本期销售量,本期销售额,累计销售量,累计销售额等。


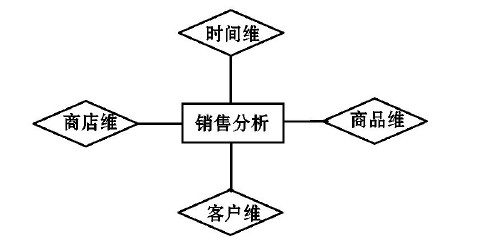
2、逻辑模型
采用星型图建模技术可为数据仓库建立完善的逻辑模型。星型图用来描述数据仓库需求,因此也包括三个逻辑实体,维度、指标和详细类别。由信息包图可以知道,一个维度内的每个单元式一个类别,代表该维度内的一个详细的层次。
a)星型模式
星型模式是一种多维的数据模型,它由一个事实表和逻辑上围绕这个事实表的维表组成。事实表是星型模式的核心,用于存放大量业务性质的事实数据,事实表中包含了度量属性和指向周围维表的外码,事实表中的一个事实指向每个维表中的一个元组。事实表中存放的大量数据是同主题密切相关的、用户最关心的、对象的度量数据。用户依赖于维度表中的维度属性,对事实表中的数据进行查询、分析进而得到支持决策的数据。

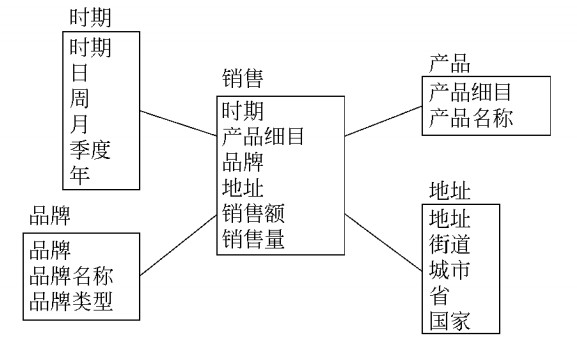
b)雪花模式
雪花模式是星型模式的进一步扩展和规范化,也就是将与事实表关联的维表分为直接关联的主维表和与主维表关联的次维表。雪花模式比星型模式增加了层次结构,体现了维的不同粒度的划分。
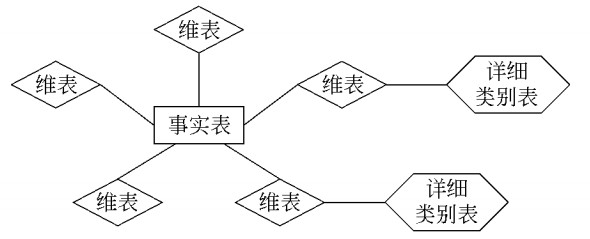

c)星系模式
当多个主题之间有公共的维时候,可以通过共享维表,把事实表连接起来。


雪花模式与星型模式的优缺点比较:
从数据格式来看:雪花型使用规范化数据,星型使用反规范化数据。
从加载内容来看,星形模型加载维度表,不需要在维度之间添加附属模型;雪花模型加载数据集市。
从ETL复杂程度来看:星形模型ETL就相对简单,而且可以实现高度的并行化。
从查询性能角度来看,在OLTP-DW环节,由于雪花型要做多个表联接,性能会低于星型架构;但从DW-OLAP环节,由于雪花型架构更有利于度量值的聚合,因此性能要高于星型架构。
从模型复杂度来看,星型架构更简单。
从层次概念来看,雪花型架构更加贴近OLTP系统的结构,比较符合业务逻辑,层次比较清晰。
从存储空间角度来看,雪花型架构具有关系数据模型的所有优点,不会产生冗余数据,而相比之下星型架构会产生数据冗余。
一般建议使用星型架构。因为我们在实际项目中,往往最关注的是查询性能问题,至于磁盘空间一般都不是问题。 当然,在维度表数据量极大,需要节省存储空间的情况下,或者是业务逻辑比较复杂、必须要体现清晰的层次概念情况下,可以使用雪花型维度。
五、OLAP以及分析服务
OLAP:OLAP是一种技术,它能够使分析人员快速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。根据数据存储方式不同,olap可以分为rolap,molap,holap
ROLAP:关系数据库来存储数据。
优点:
MOLAP:多维数据库来存储数据
优点:



