这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻
依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻
以下是搜索页面,得到吉林疫苗的搜索信息,里面包含了新闻信息和视频信息
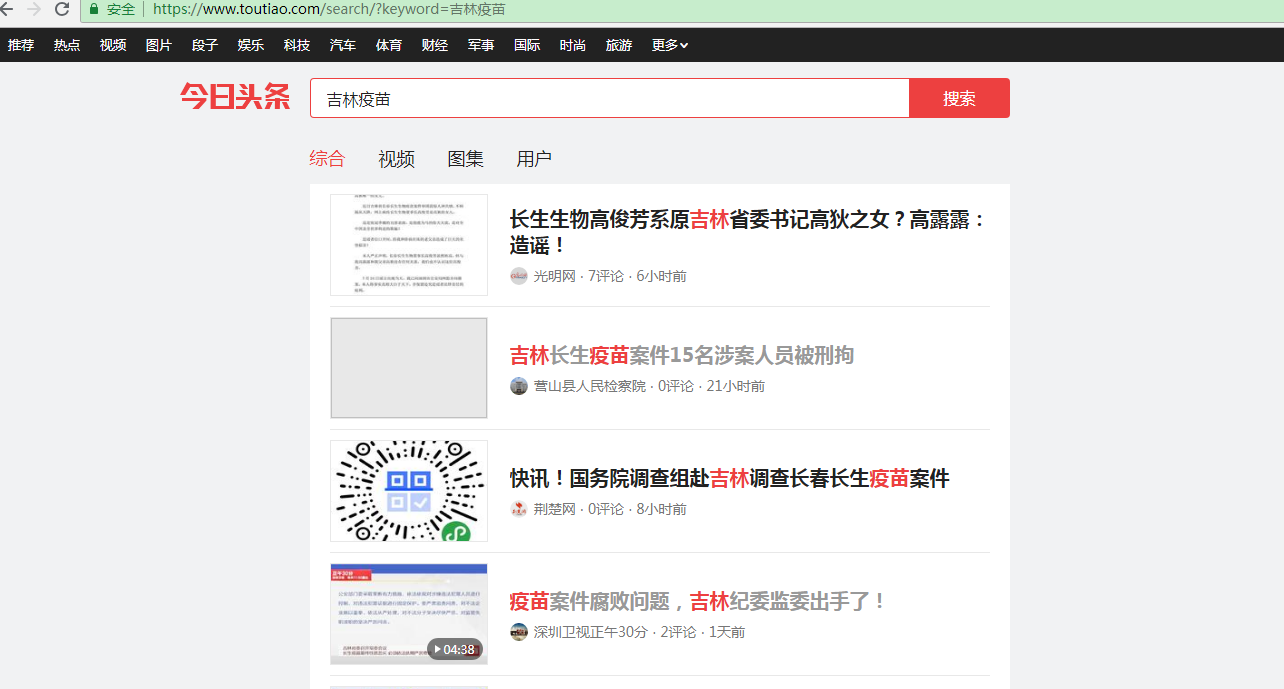
通过F12中network得到了接口url信息:https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E5%90%89%E6%9E%97%E7%96%AB%E8%8B%97&autoload=true&count=20&cur_tab=1&from=search_tab
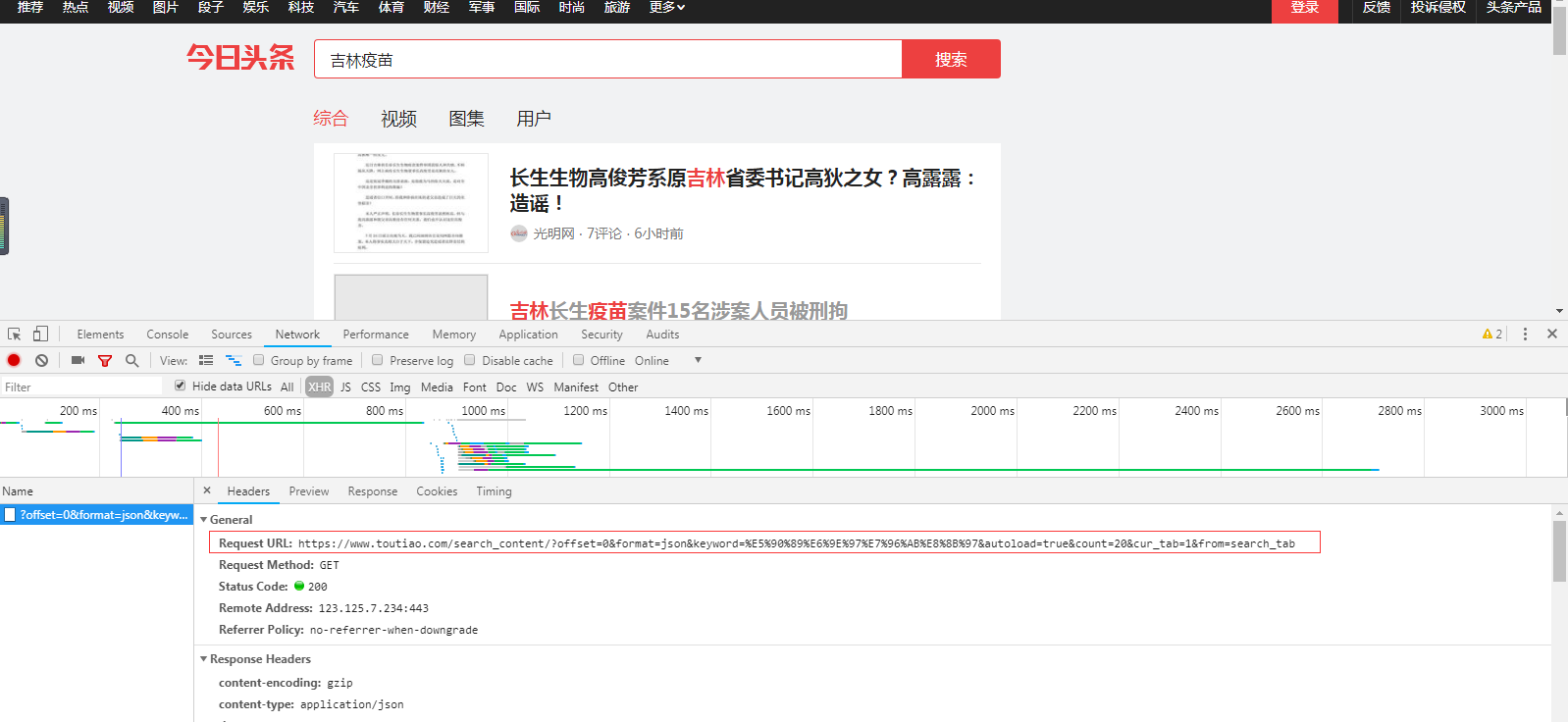
在Postman里面访问接口信息得到json信息(信息里面包含了文章的标题和链接)
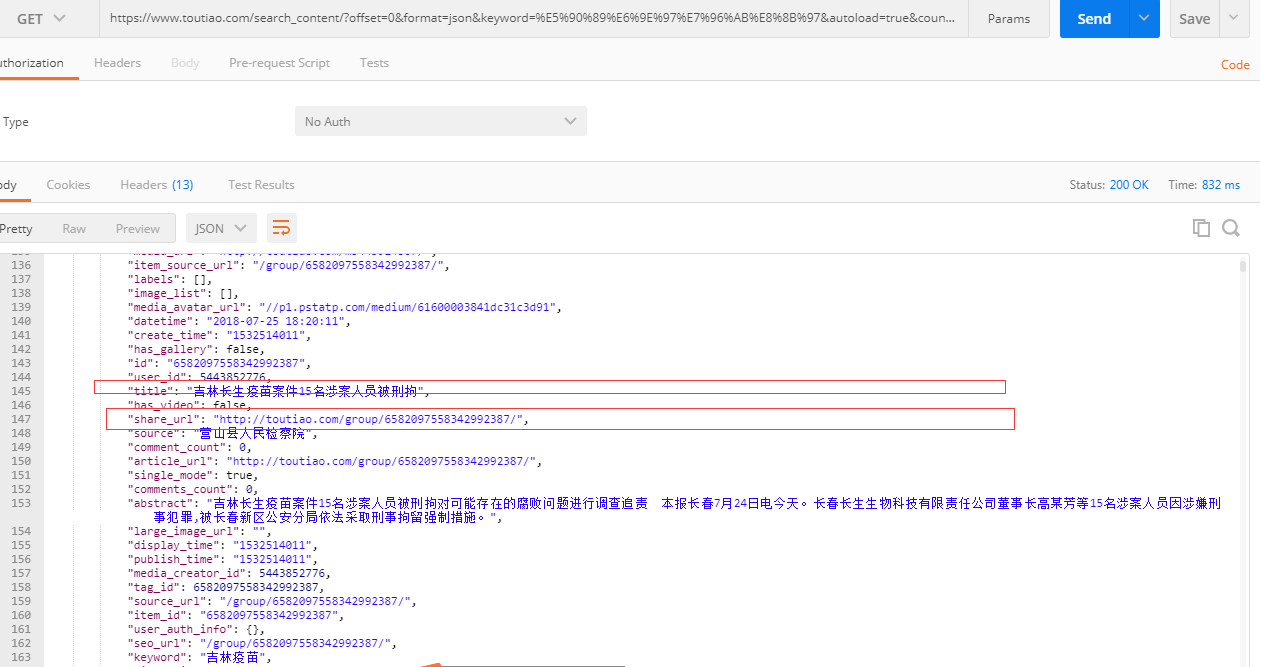
基于这些信息来开发爬虫核心代码
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
import time
import json
from toutiao.items import ToutiaoItem
class ToutiaoSerachSpider(scrapy.Spider):
name = 'toutiao_serach'
allowed_domains = ['toutiao.com']
###接口信息,这里为了方便把 &keyword= 挪到了最后边
start_urls = ['https://www.toutiao.com/search_content/?offset=0&format=json&autoload=true&count=20&cur_tab=1&from=search_tab&keyword=']
def parse(self, response):
new_key_word=response.url+'吉林疫苗'
yield scrapy.Request(new_key_word,callback=self.main_parse)
def main_parse(self,response):
search_content_data=json.loads(response.text)
for aa in search_content_data['data']:
if 'open_url' in aa.keys() and 'play_effective_count'not in aa.keys(): ### 去除搜索后得到的综合里面 保留文章信息类型,去除视频信息类型
yield scrapy.Request(aa['article_url'],callback=self.content_parse)
def content_parse(self,response):
driver = webdriver.PhantomJS()
driver.get(response.url)
time.sleep(3)
title = driver.find_element_by_class_name('article-title').text
content=driver.find_element_by_class_name('article-content').text
item=ToutiaoItem()
item['title'] =title
item['content']=content
yield item
最后得到新闻信息
