楼主准备爬取此页面的小说,此页面一共有125章
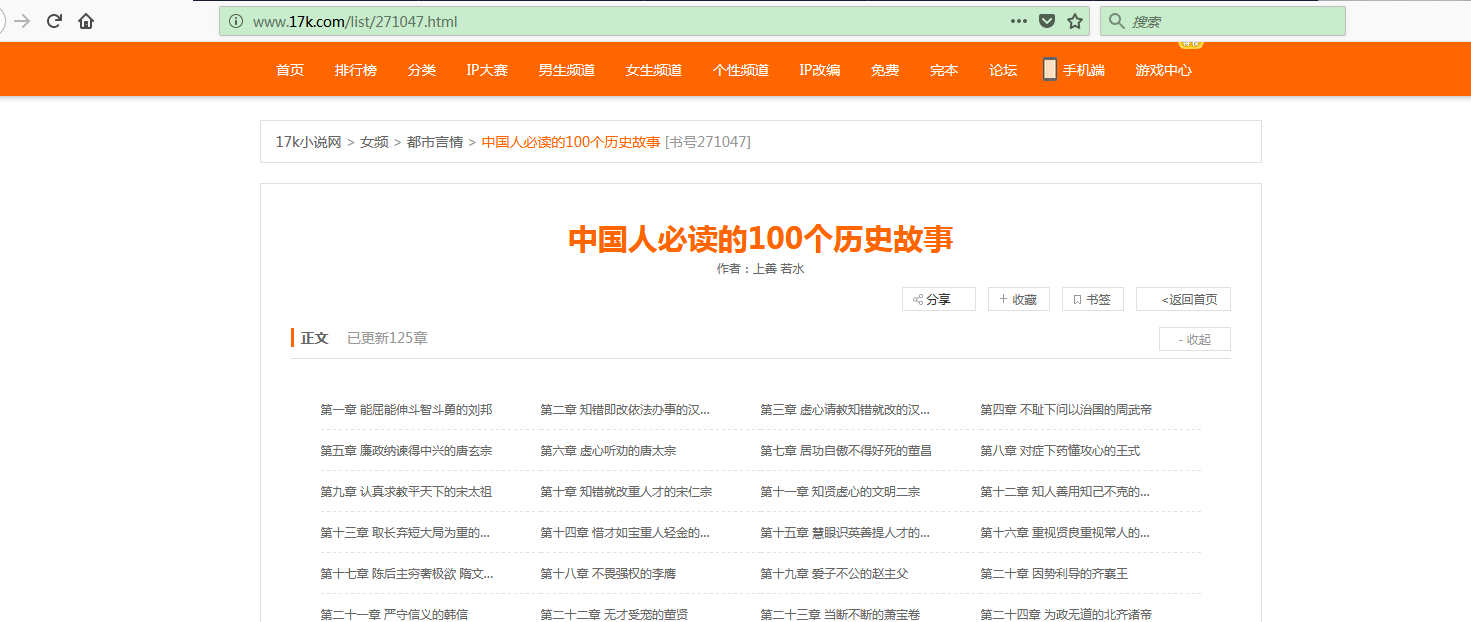
我们点击进去第一章和第一百二十五章发现了一个规律
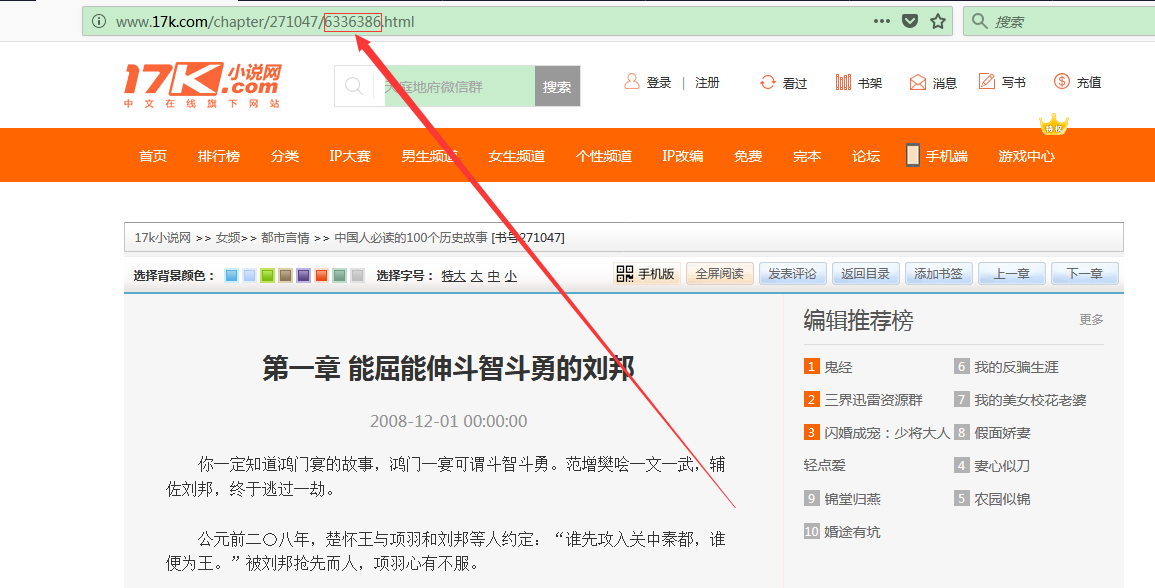
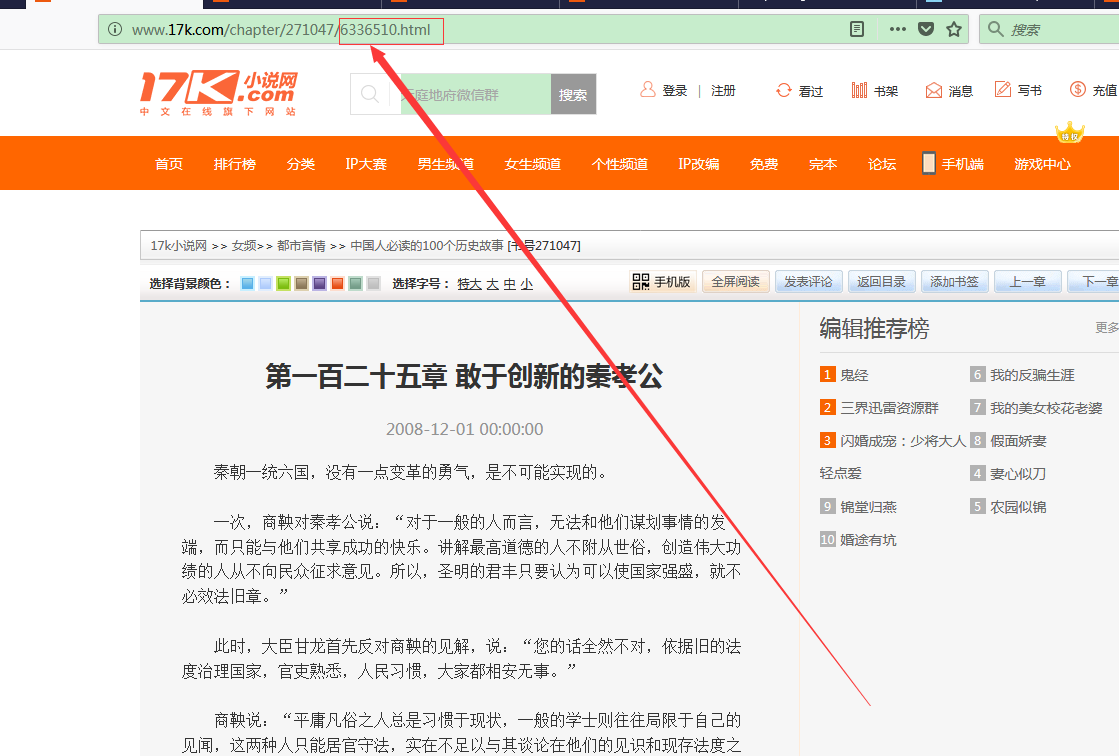
我们看到此链接的 http://www.17k.com/chapter/271047/6336386.html ->http://www.17k.com/chapter/271047/6336510.html
6336386依次递增到6336510 我们根据此灵感 得到下面的spiders核心的代码
# -*- coding: utf-8 -*- import scrapy from k17.items import K17Item import json class A17kSpider(scrapy.Spider): name = '17k' allowed_domains = ['17k.com'] start_urls = ['http://www.17k.com/chapter/271047/6336386.html'] def parse(self, response): for i in range(6336386, 6336510 + 1): new_url="http://www.17k.com/chapter/271047/"+str(i)+".html" yield scrapy.Request(new_url, callback=self.next_parse) def next_parse(self,response): for bb in response.xpath('//div[@class="readArea"]/div[@class="readAreaBox content"]'): item=K17Item() title=bb.xpath("h1/text()").extract()
new_title=(''.join(title).replace(' ','')).strip() item['title']=new_title dec= bb.xpath("div[@class='p']/text()").extract()
dec_new=((''.join(dec).replace(' ','')).replace('u3000','')).strip() ###去除内容中的 和u3000和空格的问题 item['describe'] = dec_new yield item
我们在pipelines.py最后得到最终结果
import json class K17Pipeline(object): def process_item(self, item, spider): return item #初始化时指定要操作的文件 def __init__(self): self.file = open('item.json', 'w', encoding='utf-8') # 存储数据,将 Item 实例作为 json 数据写入到文件中 def process_item(self, item, spider): lines = json.dumps(dict(item), ensure_ascii=False) + ' ' self.file.write(lines) return item # 处理结束后关闭 文件 IO 流 def close_spider(self, spider): self.file.close()
