1、基于用户日志
1.1、计算query term和doc term的条件概率
论文标题:Probabilistic Query Expansion using Query Logs
论文整体架构分为3部分:1、计算了query端的分布和doc端分布的不同,给出了计算方法,并通过数据论证了两者语义上的差别。2、给出了概率计算公式。3、简述了如何利用概率公式进行query扩展。
- query空间和doc空间的gap
query端的数据分布和doc端的数据分布是不一样的,这个是众所周知的,但是有没有一些定量的值来衡量呢?作者给出了计算方式
计算doc的向量空间,对于每一篇doc来说,我们可以获得其向量空间({W_{1}^{(d)},W_{2}^{(d)}......W_{n}^{(d)}}) ,n表示向量空间的维度,对于每一个(W_{i}^{(d)})来说,其计算方式如下图所示,利用的就是tf-idf算法。

接下来计算query的向量空间,在文章中叫virtual document,意思是虚拟空间。对于每一篇doc来说,我们都能获得它的点击query,通过点击query,我们可以获得virtual document vector,计算方式依旧是上图,只不过这里tf-idf计算的空间为query端的结果。
当我们得到每一篇doc的向量和其对应的query向量时(这里是一一对应关系),则我们就能计算两者的相似性了,计算公式为
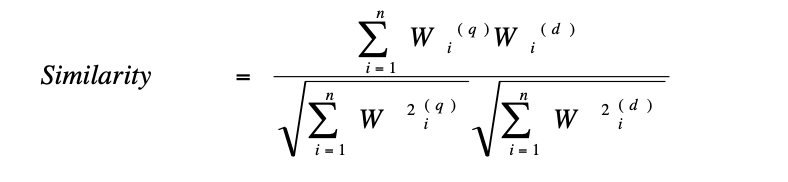
最终,我们会得到每篇doc的相似度结果,经作者论证,表明query端和doc端的确存在很大的鸿沟。
那么,问题来了,我们怎样来解决这个鸿沟呢?解决的办法就是利用点击日志。 - 根据点击日志计算query和doc的term条件概率
这张图表明了用户的点击行为,最左边的query terms表明单词的term信息,比如”北京的大学“分词后是”北京“”大学“(去除停用词后),那么query term中就包含了这两个词,同理,doc端也可以得到document terms,相应的,每个query、doc都和其term有连线。若query和doc有点击行为,则query和doc有连线,这样,就构成了下图。
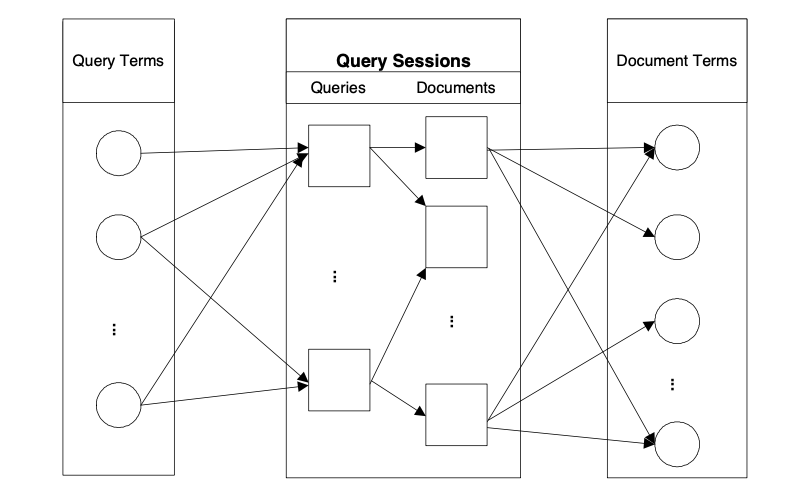
条件概率计算公式为下图,这里的(D_{k})表示有点击的doc所对应的线的连接

- 应用于query扩展
如下图所示,对于未知的(Q)来说,分别计算对应的条件概率,并提取概率最大的term进行扩展。

2、基于翻译模型
2.1
论文题目:Learning to Rewrite Queries
这篇文章其实给了query扩展的一个整体的框架,第一步:挖掘扩展词,第二步:对扩展词进行排序。
- 挖掘扩展词
这里并没有详细的介绍挖掘扩展词的算法,这块内容简单的介绍了下翻译模型如何应用于query的扩展,并且可以利用多种方式共同挖掘,最终得到(q,r)的pair对。 - 对扩展词进行排序
这里介绍了排序的三种方式,pair-wise,point-wise,list-pair-wise三种方式。 - 学习目标