前言
以下内容是个人学习之后的感悟,转载请注明出处~
Mini-batch梯度下降法
见另一篇文章:梯度下降法。
指数加权平均
其原理如下图所示,以每天的温度为例,每天的温度加权平均值等于β乘以前一天的温度加权平均值,再加上(1-β)乘以
当天温度的和。β值得选取对温度加权平均值的影响非常明显,图中的红黄绿三条曲线即β取不同值时的曲线。
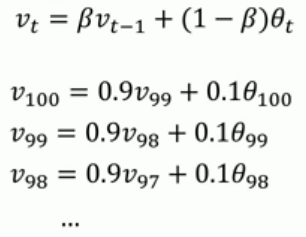

不过此方法有个弊端,就是前期v0为0,导致初期阶段的值很小,并不准确。对此,我们可以对它进行偏差修正,
即 vt := vt / ( 1-β t ) 。但是大部人都不太喜欢用偏差修正,宁愿忍受初期阶段。
动量(momentum)梯度下降法
有时候遇到下图中的情况,我们用传统的梯度下降法,需要花费很长的时间这并不是我们想要的效果。
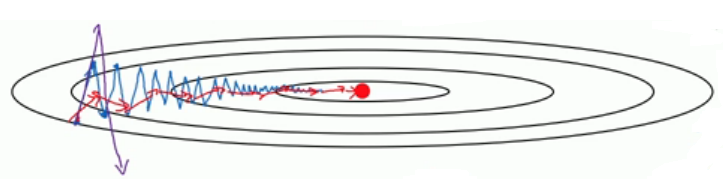
想要解决这种问题,我们能够快速想到的便是增大横向的跨度,减小纵向的跨度,那么具体该怎么实施呢?
这就需要用到动量梯度下降法了,其具体实现如下图所示,其中β一般取0.9 。

总之,该方法可以加快梯度下降。
RMSprop
除了上述的方法外,RMSprop也可以加快梯度下降,解决动量梯度下降法提到的问题。其具体实现如下图所示,其中写成β2是
为了和上面的β区分开来,取值一般取0.999,至于ε是为了防止分母太接近0,其一般取10-8。

Adam优化算法
该算法结合了动量(momentum)下降梯度法和RMSprop法,其具体实现见下图:

其具体参数的取值一般如下图所示:

学习率衰减
在训练模型的时候,通常会遇到这种情况:我们平衡模型的训练速度和损失(loss)后选择了相对合适的学习率(learning rate),
但是训练集的损失下降到一定的程度后就不在下降了,比如training loss一直在0.7和0.9之间来回震荡,不能进一步下降。如下图所示:

遇到这种情况通常可以通过适当降低学习率(learning rate)来实现。但是,降低学习率又会延长训练所需的时间。
学习率衰减(learning rate decay)就是一种可以平衡这两者之间矛盾的解决方案。学习率衰减的基本思想是:学习率随着训练的
进行逐渐衰减。
学习率衰减基本有两种实现方法:
- 线性衰减。例如:每过5个epochs学习率减半
- 指数衰减。例如:每过5个epochs将学习率乘以0.1
注:不同的优化算法适用于不同的深度结构。
以上是全部内容,如果有什么地方不对,请在下面留言,谢谢~