一、Rabbit MQ
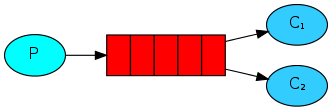
1、工作队列
工作队列就是多个work共同按顺序接收同一个queue里面的任务,还可以设置basic_qos来确保当前的任务执行完毕后才继续接收任务。
import pika
# 连接
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 申明队列
channel.queue_declare(queue="work_queue", durable=True) # durable 持久化,rabbit重启这个queue也不会丢失
messages = ["apple", "pear", "cherry", "banana", "watermelon"]
for message in messages:
# 发送消息,routing表示要发送到那个queue,body就是发送的消息内容,properties是其他的一些配置,可以设置多个
channel.basic_publish(exchange="", routing_key="work_queue", body=message, properties=pika.BasicProperties(
delivery_mode=2 # 发送的消息持久化,前提是queue也是持久化到的
))
print("send {message} ok".format(message=message))
# channel.queue_delete(queue="work_queue") # 删除queue
# 关闭连接
conn.close()
import pika
import time
# 连接
cred = pika.PlainCredentials("Glen", "Glen[1234]") # 用户名密码等信息
# conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672, virtual_host="/", credentials=cred))
channel = conn.channel()
# 回调函数
def callbak(ch, method, properties, body):
print("body:", body)
time.sleep(1)
print("done..")
print("method.delivery_tag", method.delivery_tag)
ch.basic_ack(delivery_tag=method.delivery_tag) # 这里的功能和no_ack类似,突然终端queue会将任务继续分配给下一个work
"""
使用basic_qos设置prefetch_count=1,使得rabbitmq不会在同一时间给工作者分配多个任务,
即只有工作者完成任务之后,才会再次接收到任务。
"""
channel.basic_qos(prefetch_count=1)
# channel.queue_declare(queue="work_queue")
channel.basic_consume(callbak, queue="work_queue", no_ack=False) # no_ack 默认使False,需要等待callback执行完毕才算这个消息处理完毕
channel.start_consuming()
"""
这里多个work会按顺序接收producer发布的任务,处理完成后才继续接收
"""
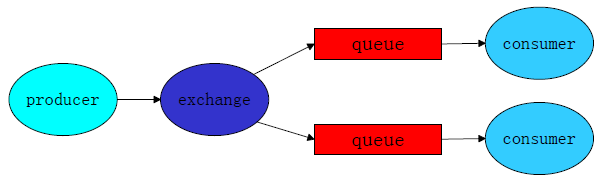
2、交换机
producer先将消息发送到交换机exchange,然后exchange再将消息发送给所有帮绑定的queue,即将消息广播出去
import pika
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 定义交换机
"""
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
"""
channel.exchange_declare(exchange="message", exchange_type="fanout")
while True:
message = input(">>")
# 直接发送到exchange,接收端使用随机的queue来绑定exchange,然后接收
channel.basic_publish(exchange="message", routing_key="", body=message)
print("send {message} ok".format(message=message))
import pika
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 定义交换机
channel.exchange_declare(exchange="message", exchange_type="fanout")
# 生成随机的queue,并绑定到交换机
result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue # 获取随机胜场的queue名字
# 将随机的queue绑定到exchange
channel.queue_bind(exchange="message", queue=queue_name)
def callback(ch, method, properties, body):
print(body)
channel.basic_consume(callback, queue=queue_name, no_ack=True)
channel.start_consuming()
3、路由器
direct和路由器类似,发送小时的时候需要指定目的地routing_key,只有对应的queue才会接收
import pika
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 定义路由键
"""
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
"""
channel.exchange_declare(exchange="message2", exchange_type="direct")
while True:
message, routing = input(">>").split()
# 发送消息的时候同时指定routing_key,只有对应routing_key的consumer才会接收到
# 发送消息示例:info_message info
channel.basic_publish(exchange="message2", routing_key=routing, body=message) # 发送的每个消息都要指明路由
print("send {message} {routing} ok".format(message=message, routing=routing))
import pika
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 定义交换机
channel.exchange_declare(exchange="message2", exchange_type="direct")
# 生成随机的queue,并绑定到交换机
result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue # 获取随机胜场的queue名字
# channel.queue_bind(exchange="message2", routing_key="info", queue=queue_name)
channel.queue_bind(exchange="message2", routing_key="warning", queue=queue_name) # 绑定不同的routing_key
# channel.queue_bind(exchange="message2", routing_key="error", queue=queue_name)
def callback(ch, method, properties, body):
print(body)
channel.basic_consume(callback, queue=queue_name, no_ack=True)
channel.start_consuming()
4、路由模糊匹配
producer发送消息的时候可以模糊地指定接收的queue,如有多个queue, mysql.error redis.eror mysql.info redis.info,指定不同的routing_key可以匹配到不同的queue,mysql.* 可以匹配到mysql.error,mysql.info, *.error可以匹配redis.error,mysql.error。“#”表示所有、全部的意思;“*”只匹配到一个词。
import pika
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 定义路由键
"""
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
"""
channel.exchange_declare(exchange="message3", exchange_type="topic")
"""
发送的消息如下:
a happy.work
b happy.life
c sad.work
d sad.life
"""
while True:
message, routing = input(">>").split()
channel.basic_publish(exchange="message3", routing_key=routing, body=message) # 发送的每个消息都要指明路由
print("send {message} {routing} ok".format(message=message, routing=routing))
import pika
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 定义交换机
channel.exchange_declare(exchange="message3", exchange_type="topic")
# 生成随机的queue,并绑定到交换机
result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue # 获取随机胜场的queue名字
# channel.queue_bind(exchange="message3", routing_key="#", queue=queue_name) # 可以接收任何消息
# channel.queue_bind(exchange="message3", routing_key="happy.*", queue=queue_name) # 绑定不同的routing_key
channel.queue_bind(exchange="message3", routing_key="*.work", queue=queue_name)
def callback(ch, method, properties, body):
print(body)
channel.basic_consume(callback, queue=queue_name, no_ack=True)
channel.start_consuming()
5、rpc远程调用返回
远程调用相当于有一个控制中心和多个计算节点,控制中心发指令调用远程的计算节点的函数进行计算,然后将结果返回给计算中心,pika模块也实现了该功能
import pika
import time
# 创建连接
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 定义队列
channel.queue_declare(queue="rpc_queue")
# 执行的函数
def mul(n):
time.sleep(5)
return n * n
# 定义接收到消息的处理方法
def message_handle(ch, method, properties, body):
print("{body} * {body} = ?".format(body=body))
response = mul(int(body))
# 将计算结果返回
ch.basic_publish(exchange="", routing_key=properties.reply_to, body=str(response))
# 返回执行成功
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(message_handle, queue="rpc_queue")
channel.start_consuming()
import pika
import threading
class Center(object):
def __init__(self):
self.response = ""
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71"))
self.channel = self.connection.channel()
# 定义接收返回消息的队列 然后在发送命令的时候作为参数传递过去,rpc执行完毕后将消息发送到这个queue里面
self.callback_queue = self.channel.queue_declare(exclusive=True).method.queue
self.channel.basic_consume(self.response_hand, no_ack=True, queue=self.callback_queue)
# 定义处理返回消息的函数
def response_hand(self, ch, method, properties, body):
self.response = body
print(body)
def request(self, n):
self.response = ""
# 发送计算请求,同时加上返回队列名
self.channel.basic_publish(body=str(n), exchange="", routing_key="rpc_queue", properties=pika.BasicProperties(
reply_to=self.callback_queue
))
# 等待接收返回数据
while self.response is "":
self.connection.process_data_events()
return int(self.response)
while True:
message = input(">>")
if not message.isdigit():
continue
center = Center()
t = threading.Thread(target=center.request, args=(int(message), )) # 启用多线程,可以不阻塞执行命令
t.start()
二、Redis
redis一共有string、list、set、zset、hash这五种常用集合,下面对常用命令进行整理,参考文档http://doc.redisfans.com/
1、连接方法
import redis
"""
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,
StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令
(比如,SET命令对应与StrictRedis.set方法)。Redis是StrictRedis的子类,
用于向后兼容旧版本的redis-py。 简单说,官方推荐使用StrictRedis方法。
"""
# redis = redis.Redis(host="192.169.120.71", port=6379)
# 连接池
# pool = redis.ConnectionPool(host="192.168.120.71", port=6379)
# 连接redis
# redis = redis.Redis(connection_pool=pool)
# 使用默认方式连接到数据库
# redis = redis.StrictRedis(host='192.168.120.71', port=6379, db=0)
# 使用url方式连接到数据库
# redis = redis.StrictRedis.from_url('redis://@192.168.120.71:6379/0')
# 连接池
# pool = redis.ConnectionPool(host="192.168.120.71", port=6379)
"""
有三种构造url的方法
redis://[:password]@host:port/db # TCP连接
rediss://[:password]@host:port/db # Redis TCP+SSL 连接
unix://[:password]@/path/to/socket.sock?db=db # Redis Unix Socket 连接
"""
pool = redis.ConnectionPool.from_url("redis://@192.168.120.71:6379/0")
redis = redis.StrictRedis(connection_pool=pool)
name = redis.get("name")
print(name)
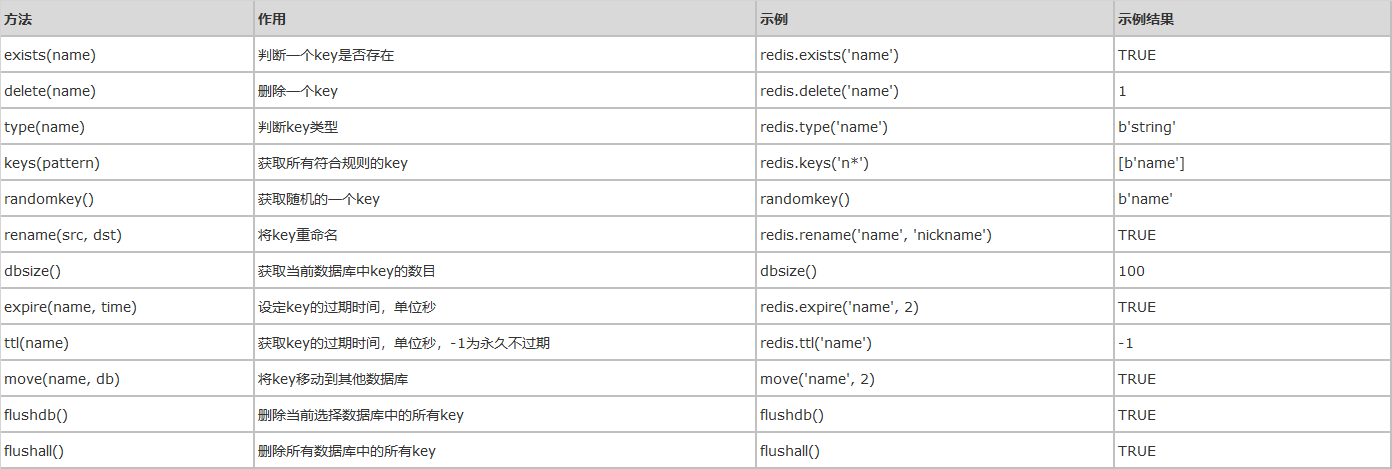
2、key
3、string

4、list

5、set

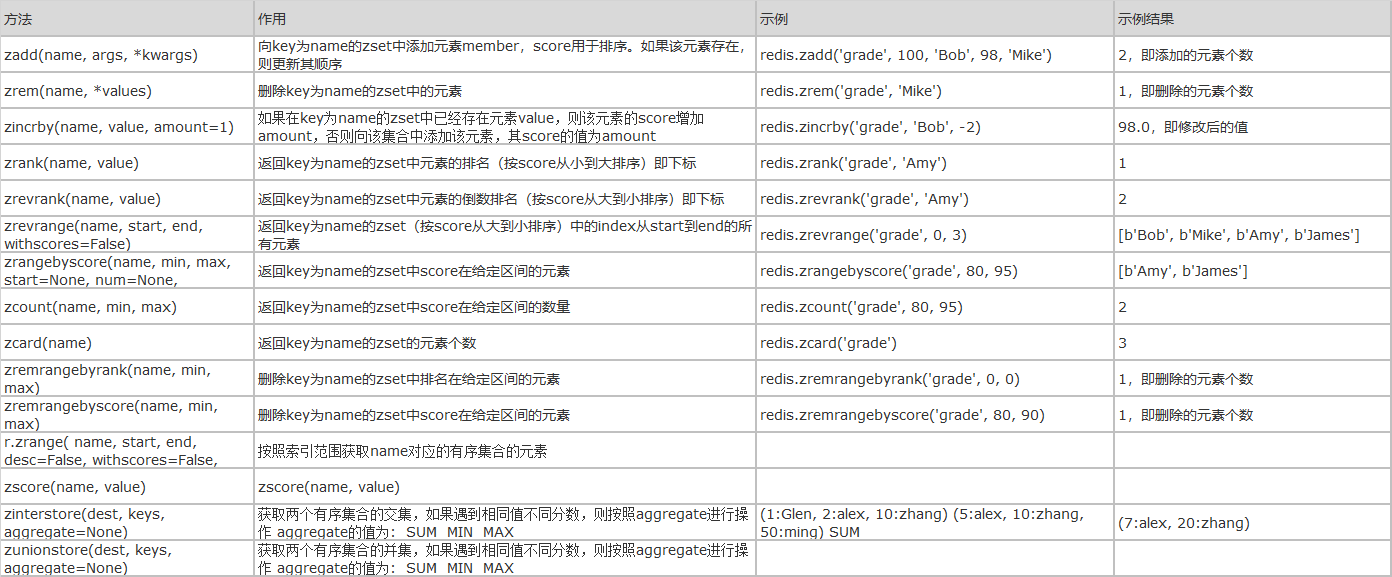
6、zset
7、hash

8、发布、订阅、管道
import redis
pool = redis.ConnectionPool(host="192.168.120.71", port=6379)
# r = redis.StrictRedis(connection_pool=pool)
# pipe = r.pipeline(transaction=True) # 生成管道
# pipe.set("status", 1)
# pipe.set("message", "hello")
# pipe.execute() # 上面两条一起执行,其中一条执行失败则都失败
class RedisPubSub(object):
def __init__(self, channel_sub="fm110", channel_pub="fm110"):
self.__conn = redis.StrictRedis(connection_pool=pool)
self.channel_sub = channel_sub
self.channel_pub = channel_pub
def pub(self, message):
self.__conn.publish(message=message, channel=self.channel_pub)
# return True
def sub(self):
sub = self.__conn.pubsub()
sub.subscribe(self.channel_sub)
sub.parse_response()
return sub
from day11.pub_sub_pipe import *
r = RedisPubSub(channel_sub="fm110", channel_pub="fm110")
r.pub("hello")
from day11.pub_sub_pipe import *
r = RedisPubSub(channel_pub="fm110", channel_sub="fm110")
redis_sub = r.sub()
while True:
msg = redis_sub.parse_response()
print(msg)
三、rpc命令端
import pika
import threading
import uuid
class Center(object):
def __init__(self, remote_host):
self.remote_host = remote_host
self.response = {}
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71"))
self.channel = self.connection.channel()
# self.channel.exchange_declare(exchange="work", exchange_type="fanout")
self.channel.queue_declare(queue=remote_host)
# 定义接收返回消息的队列 然后在发送命令的时候作为参数传递过去,rpc执行完毕后将消息发送到这个queue里面
self.callback_queue = self.channel.queue_declare(exclusive=True).method.queue
self.channel.basic_consume(self.response_hand, no_ack=True, queue=self.callback_queue)
# 定义处理返回消息的函数
def response_hand(self, ch, method, properties, body):
self.response[properties.correlation_id] = eval(body.decode("utf"))
print(self.remote_host, properties.correlation_id, self.response[properties.correlation_id]["stdout"], end="")
def request(self, n):
rpcid = str(uuid.uuid4()) # 使用UUID生成标记,随消息一起发送,rpc处理后再把这个id传递回来
print(self.remote_host, rpcid, n) # 这样及时再同一个队列里面的消息执行结果也不会混乱
self.response[rpcid] = ""
# 发送计算请求,同时加上返回队列名
self.channel.basic_publish(body=str(n), exchange="", routing_key=self.remote_host, properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=rpcid # 发送任务时添加任务id
))
# 等待接收返回数据
while self.response[rpcid] is "":
self.connection.process_data_events()
return self.response[rpcid]
while True:
message = input(">>").split() # cmd ip1,ip2,ip3
if not message:
continue
hosts = message[1].split(",")
for host in hosts:
center = Center(host)
t = threading.Thread(target=center.request, args=(message[0], )) # 启用多线程,可以不阻塞执行命令
t.start()
import pika
import subprocess
# 创建连接
conn = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.120.71", port=5672))
channel = conn.channel()
# 定义队列
# 执行的函数
def cmd_handel(cmd_str):
print(cmd_str)
re = {}
p = subprocess.run(cmd_str, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
re["stdout"] = p.stdout.decode("utf8")
re["stderr"] = p.stderr.decode("utf8")
re["code"] = p.returncode
re["host"] = "1.1.1.1"
print(re["stdout"])
return re
# 定义接收到消息的处理方法
def message_handle(ch, method, properties, body):
print(body.decode("utf8"))
response = cmd_handel(body.decode("utf8"))
# 将计算结果返回
ch.basic_publish(exchange="", routing_key=properties.reply_to, body=str(response), properties=pika.BasicProperties(
correlation_id=properties.correlation_id # 返回消息时一起返回任务id
))
# 返回执行成功
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.queue_declare(queue="2.2.2.2")
queue_name = channel.queue_declare(exclusive=True).method.queue
channel.basic_consume(message_handle, queue="2.2.2.2")
channel.start_consuming()