前言
通常来说,在传统零售行业中80%的收益来自于20%的客户,因此对客户的价值进行分类显得尤其重要,而在本文我们基于批发经销商客户的真实消费数据,建立K-means聚类模型来对客户价值进行细分。
目录
1. 数据来源及背景
2. 明确分析目的
3. 数据探索分析
4. 数据预处理
5. 构建模型
6. 客户价值细分
正文
1. 数据来源及背景
数据来源: http://archive.ics.uci.edu/ml/machine-learning-databases/00292;
数据背景: 这是某批发经销商客户在各类型产品的年度支出数据集. 该数据集样本容量为440, 共有8个特征, 其分别为: 客户渠道, 客户所在地区, 以及在新鲜产品, 奶制品, 食品杂货, 冷冻产品, 洗涤剂和纸制品, 熟食产品这6种类型产品的年度支出.
2. 明确分析目的
通过提出一系列问题, 明确我们的分析目的:
1) 各类产品的年度支出平均水平如何?哪个产品最高?哪个又最低?
2) 如何对这些客户进行分类呢?他们的消费行为又是怎样的呢?
3) 商家该如何根据分类结果制定营销计划呢?
3. 数据探索分析
1. 查看前2行和后2行
import pandas as pd df = pd.read_csv(r'D:DataWholesale customers data.csv') pd.set_option('display.max_rows', 4) df

可通过以上看出我们的数据维度的确是440行×8列, 以及每列都是数字, 到底是字符串类型还是数值类型, 需要进一步探索.
2. 查看数据整体信息
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 440 entries, 0 to 439 Data columns (total 8 columns): Channel 440 non-null int64 Region 440 non-null int64 Fresh 440 non-null int64 Milk 440 non-null int64 Grocery 440 non-null int64 Frozen 440 non-null int64 Detergents_Paper 440 non-null int64 Delicassen 440 non-null int64 dtypes: int64(8) memory usage: 27.6 KB
通过查看数据整体信息, 可以确定每列都是数值型, 且均为64位整数型;另外, 也可以看出数据里是没有缺失值的, 即全部为440.
数据类型现在已经确定了, 接下来寻找我们第一个问题的答案了.
3. 描述性统计
df.describe()

1) 各类产品的年度支出平均水平如何?哪个产品最高?哪个又最低?
这里的平均水平用平均数和中位数这两者中的哪个合适呢?通过分别对比各类型产品的平均数和中位数, 发现平均数都大于中位数, 呈现右偏分布, 显然这里采用中位数来代表较为妥当.
各类型产品的年度支出平均水平分别为: 新鲜产品8504.0m.u.、奶制品3627.0m.u.、食品杂货4755.5m.u.、冷冻产品1526.0m.u.、洗涤剂和纸质品816.5m.u.、熟食产品965.5m.u.
其中, 新鲜产品排名第一,第二是食品杂货,第三、第四和第五分别是奶制品、冰冻产品和熟食产品,第六则是洗涤剂和纸质品.
对于第二个问题,我们利用k-means聚类模型来对其进行分类,而在建模之前,我们需要对数据进行数据预处理
4. 数据预处理
1. 数据清洗
1) 缺失值处理
没有缺失值, 因此不用缺失值处理
2) 异常值处理
在处理异常值之前, 先来通过箱线图查看异常值.
import seaborn as sns import matplotlib.pyplot as plt def get_boxplot(data, start, end): fig, ax = plt.subplots(1, end-start, figsize=(24, 4)) for i in range(start, end): sns.boxplot(y=data[data.columns[i]], data=data, ax=ax[i-start]) get_boxplot(df, 2, 8)

可以看到以上6个连续型变量均有不同程度的异常值, 由于k-means算法对异常值较敏感, 因此选择剔除它
def drop_outlier(data, start, end): for i in range(start, end): field = data.columns[i] Q1 = np.quantile(data[field], 0.25) Q3 = np.quantile(data[field], 0.75) deta = (Q3 - Q1) * 1.5 data = data[(data[field] >= Q1 - deta) & (data[field] <= Q3 + deta)] return data del_df = drop_outlier(df, 2, 8) print("原有样本容量:{0}, 剔除后样本容量:{1}".format(df.shape[0], del_df.shape[0])) get_boxplot(del_df, 2, 8)
原有样本容量:440, 剔除后样本容量:318

在剔除一次异常值之后, 6个连续变量的波动幅度也都都大致接近, 你可能会问为什么还有异常值存在? 现在的异常值是相对于新数据集产生的, 而我们把原数据集中的异常值已经剔除了, 通常来说, 对于异常值只需剔除一次即可, 如果彻底剔除的话, 样本容量可能会有大幅度的变化, 比如:
df_new = df.copy() #直到第10次的时候图像上才没有出现异常值 for i in range(10): df_new = drop_outlier(df_new, 2, 8) print("原有样本容量:{0}, 彻底剔除后样本容量:{1}".format(df.shape[0], df_new.shape[0])) get_boxplot(df_new, 2, 8)
原有样本容量:440, 彻底剔除后样本容量:97

可以看到现在的数据集中已经不存在异常了, 但是样本容量也从440大幅度下降为97, 因此这里不建议彻底删除.
2. 数据变换
对数据中的离散型变量和连续型变量分别进行适当的变换,以适应模型的要求
1) 离散型变量
将离散型变量处理成哑变量.
del_df['Channel'] = del_df.Channel.astype(str) del_df['Region'] = del_df.Region.astype(str) del_df = pd.get_dummies(del_df)
2) 连续型变量
由于连续型变量的数值范围有大有小, 为消除其对聚类结果的影响, 这里采用z-score进行归一化处理
for i in range(6): field = del_df.columns[i] del_df[field] = del_df[field].apply(lambda x: (x - del_df[field].mean()) / del_df[field].std())
数据预处理这部分的工作已大致完成,下一步进行模型构建.
5. 构建模型
选取一个初始的k值, 来进行构建k-means聚类模型
1. 构建K=2的聚类模型
from sklearn.cluster import KMeans km = KMeans(n_clusters=2, random_state=10) km.fit(del_df) print(km.cluster_centers_) print(km.labels_)
[[ 0.08057098 -0.36005276 -0.42021772 0.11899282 -0.66737726 -0.10885484 0.97333333 0.02666667 0.2 0.10222222 0.69777778] [-0.19492979 0.8710954 1.01665578 -0.28788585 1.61462241 0.26335849 0.13978495 0.86021505 0.10752688 0.07526882 0.8172043 ]] [1 1 0 1 1 1 0 1 1 0 1 1 1 0 1 1 0 0 0 1 0 0 0 0 0 0 0 1 1 1 0 1 1 1 0 0 1 0 0 1 0 1 1 1 1 0 0 1 0 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 0 1 1 0 0 0 1 0 0 1 0 0 0 0 1 0 0 0 1 1 1 0 0 1 0 1 0 0 0 0 0 1 0 0 0 1 1 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 1 1 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 0 1 1 0 0 0 0 0 0 0 0]
将客户分为两类合适吗?我们通过迭代的方式来选择合适的k值.
2. 迭代选择合适的k值
import matplotlib.pyplot as plt K = range(1, 10) sse = [] for k in K: km = KMeans(n_clusters=k, random_state=10) km.fit(del_df) sse.append(km.inertia_) plt.figure(figsize=(8, 6)) plt.plot(K, sse, '-o', alpha=0.7) plt.xlabel("K") plt.ylabel("SSE") plt.show()
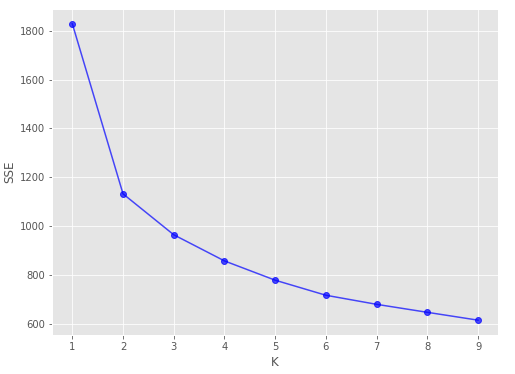
根据肘部法则, 选择K=2, 也就是说将客户分成两类.
6. 客户价值细分
from pandas.plotting import parallel_coordinates #训练模型 km = KMeans(n_clusters=2, random_state=10) km.fit(del_df) centers = km.cluster_centers_ labels = km.labels_ customer = pd.DataFrame({'0': centers[0], "1": centers[1]}).T customer.columns = del_df.keys() df_median = pd.DataFrame({'2': del_df.median()}).T customer = pd.concat([customer, df_median]) customer["category"] = ["customer_1", "customer_2", 'median'] #绘制图像 plt.figure(figsize=(12, 6)) parallel_coordinates(customer, "category", colormap='flag'') plt.xticks(rotation = 15) plt.show()
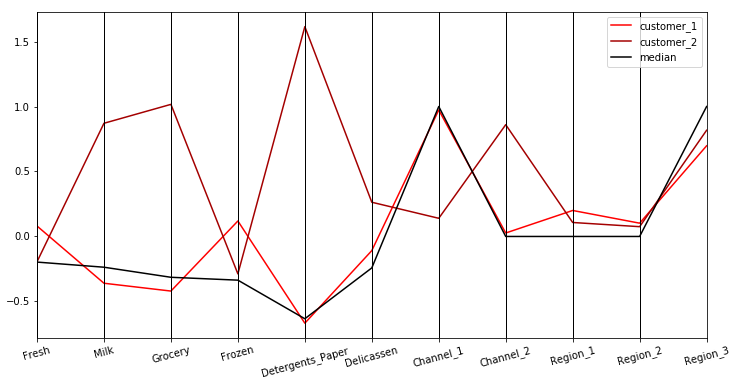
将各类型产品年度支出的聚类中心以及中位数绘制如上图所示, 那么我们的第二个问题也就有了答案.
2) 如何对这些客户进行分类呢?他们的消费行为又是怎样的呢?
我们通过k-means聚类模型将这些客户分为两群: 客户群1和客户群2.
就六种类型产品的年度支出来看, 客户群1在冷冻产品上最高, 在洗涤剂和纸制品上最低; 客户群2在冷冻产品上则最低, 在洗涤剂和纸制品上则最高. 另外, 客户群2在这六种产品的年度支出聚类中心均位于中位数水平之上上, 因此可将客户群2视为重要价值客户, 而客户群1则为一般价值客户.
最后, 我们将所有客户的聚类结果绘制在平行坐标图上
#将聚类后的标签加入数据集 del_df['category'] = labels del_df['category'] = np.where(del_df.category == 0, 'customer_1', 'customer_2') customer = pd.DataFrame({'0': centers[0], "1": centers[1]}).T customer["category"] = ['customer_1_center', "customer_2_center"] customer.columns = del_df.keys() del_df = pd.concat([del_df, customer]) #对6类产品每年消费水平进行绘制图像 df_new = del_df[['Fresh', 'Milk', 'Grocery', 'Frozen', 'Detergents_Paper', 'Delicassen', 'category']] plt.figure(figsize=(18, 6)) parallel_coordinates(df_new, "category", colormap='cool') plt.xticks(rotation = 15) plt.show()

通过上图可以看出模型的聚类效果较为理想, 同时也显示出客户群2(重要价值客户)相对于客户群1(一般价值客户)的数量较少, 毕竟重要的总是占少数.
针对这些结果, 该采取什么措施呢?来到我们的第三个问题
3) 商家该如何根据分类结果制定营销计划呢?
就六大类型产品来说, 可通过问卷的方式来调研改善店铺内布局以及增加产品种类是否会影响客户的购买行为; 另外, 根据聚类结果发现高价值客户的来源倾向于渠道2, 可加大在该渠道上的宣传力度; 最后,可进行一些打折促销活动,刺激客户的购买行为.
参考资料:
网易云课堂《吴恩达机器学习》
《数据分析与挖掘实战》
声明: 本文仅用于学习交流