项目:功能测试(重点)
A、是什么
测试系统中各个接口基本功能是否能够正常运行,提交的数据:正向 + 逆向
B、为什么?
要模拟用户的多样性操作,检测程序的响应是否合情合理(符合预期)
C、怎么用?
C-1、搭建功能测试框架(CSV 必须)
1)、将数据存入外部文档文件2)、添加组件读取文档(CSV Data Set Config)3)、JSON 数据以固定格式引入步骤2读取的数据
C-2、设计测试用例(将用户的操作进行分类)
分类原则:正向 + 逆向(重点)
1. 覆盖所有的必选参数(正向)
2. 组合可选参数(正向_覆盖率问题,考虑人力和时间成本)
3. 参数边界值(逆向_ 比如年龄边界)
4. 如果参数的取值范围是枚举变量,需要覆盖所有枚举值(测试所有可能的数据)
5. 空数据(逆向_不录入数据)
6. 包含特殊的字符(+-=/....)
7. 越界的数据(逆向_比如长度过长或过短)
8. 错误的数据(逆向_比如错误的手机号、身份证号、重复的id....) 实现模板:

C-3、参数化覆盖测试用例
按照测试用例编写测试数据

总结:
测试用例是在设计测试时使用什么类型的数据,就是预设条件以及预期结果 ---- 大纲
参数化覆盖测试用例声明使用什么样的数据(具体的),按照测试用例实现的 ---- 细节
项目:自动化测试
A、是什么?
由程序生成测试数据且让程序代替人工判断响应结果,就是自动化测试(程序代替人工)
B、为什么?
安全、高效、功能强大
C、怎么用?
C-1、自动化测试原则
1)、测试程序的主要功能以及一些经常被复用的功能,并非所有
自动化测试是对功能测试的补充,应用场景:程序升级时,拓展了一些功能,可能要测试之前的功能是否可用
2)、自动化测试测试数据一般只考虑正向数据
自动化测试是对功能测试的补充 + 程序生成多样的测试数据有困难
3)、自动化测试完毕,数据库数据必须恢复成测试之前的状态,优点:重复使用,功能测试不能
4) 、线程组之间不要有**关联**,不要有业务逻辑,优点:可以单独测试某一个功能C-2、实现流程
1)、搭建框架(抽取 http请求默认值、http信息头管理器、结果树)
2)、setUp 和 tearDown 线程组
3)、数据生成可以借助于 counter 函数,数据格式:自定义前缀_调用计数器函数
4)、使用断言组件让程序代替人工判断响应结果
5)、跨线程组传值
思想:setUp 将数据导出到共享空间,tear down 再将数据引入
流程:
1)、setUp 要使用 setProperty 导出数据
怎么获取要导出的 id?使用正则表达式提取器
2)、tearDown 使用 property 函数引入数据
6)、普通线程组结合 setUp 和 teardown 使用时的执行顺序:(先setUp线程组,最后teardown线程组)
多个普通线程组可能并发执行
7)、直连数据库
a、Jmeter本身不具备数据连接功能,整合第三方实现
b、配置数据库连接信息
变量名 + 数据库路径 + 第三方的启动入口 + 账号密码
c、使用 JDBC Request 操作数据库数据
SQL语句有类型: select statement | update statement
variable names: 查询的结果赋值给的变量名
d、将数据传递给 http 请求
结果的赋值规则:变量名\_# 结果个数 | 变量名_N 第N个结果
可以通过 debug sampler 查看底层赋值规则项目:性能压力测试
A、是什么?
模拟多种场景测试程序的响应时间,出错率....等实现
B、为什么?
测试程序的执行效率,执行效率直接关系到用体验
C、怎么用?
聚合报告使用图
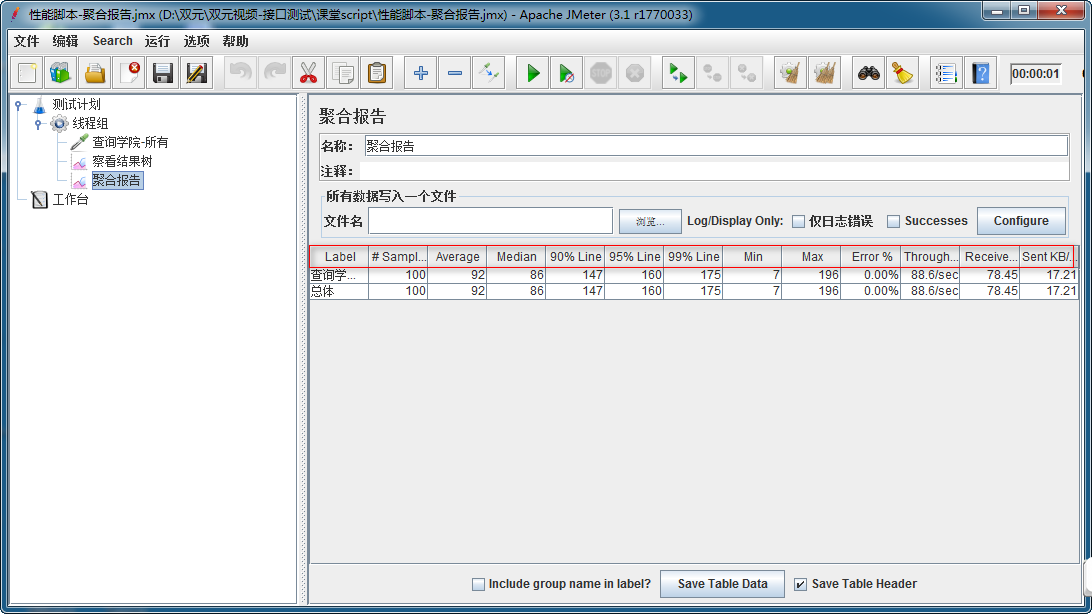
1. Label:在不勾选"Include group name in label?"复选框的情况下,为请求取样器的名称,
否则为“请求取样器所在线程组:请求取样器名称”
2. Samples:用同一个请求取样器,发送请求的数量(注意:该值是不断累计的)。
比如,10个线程数设置为10,迭代10次,那么每运行一次测试,该值就增加10*10=100
3. Average:请求的平均响应时间
4. Median:中位数。50%的样本都没有超过这个时间。
这个值是指把所有数据按由小到大将其排列,就是排列在第50%的值。
5. 90% Line:90%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第90%的值。
6. Min:针对同一请求取样器,请求样本的最小响应时间
7. Max:针对同一请求取样器,请求样本的最大响应时间
8. Error %:出现错误的请求样本的百分比
9. Throughput:吞吐量以“requests/second、requests /minute、requests /hour”来衡量。
时间单位已经被选取为second,所以,显示速率至少是1.0,即每秒1个请求。
10. Received KB/sec - 收到的千字节每秒的吞吐量测试。
11. Kb/sec - 以Kilobytes/seond来衡量的吞吐量(发送的千字节每秒的吞吐量测试)提示
1. 参数化:参数化尽量避免采用从外部读取参数,使用固定参数+函数形式( 如:${__counter(TRUE,)})
2. 察看结果树:必须清除单个接口内察看结果树
(如不去掉,非常占用测试机自身性能),在测试计划下添加一个察看结果树
3. 报告:性能报告可根据实际需求选择,建议保留添加聚合报告
4. 线程组:增删改查每一个功能点,都需建立单独线程组,而避免在同一个线程组内添加
多个HTTP请求完成增删改查(以便参数化对单个请求做压测和并发)
5. 分布式:如并发数量大,采用分布式测试,因为测试机可能性能不够开启太多虚拟用户
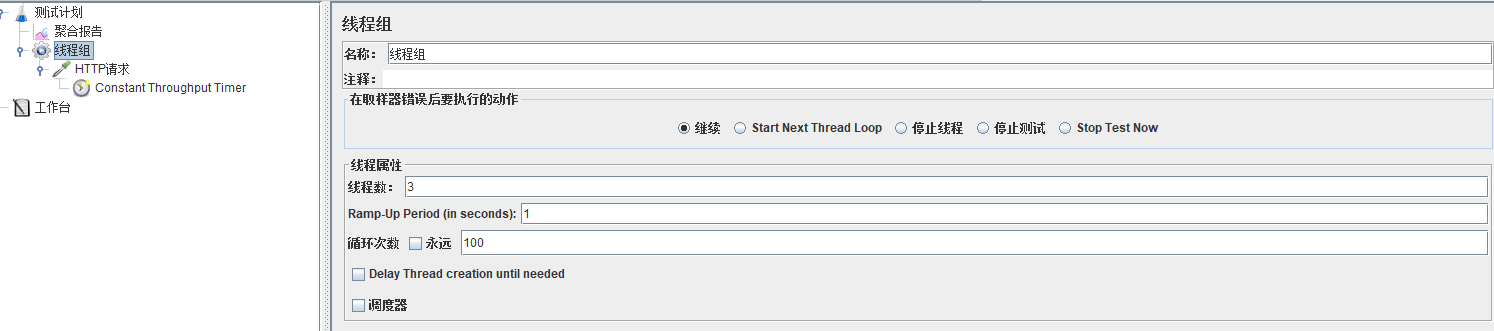
6. 新增/删除:新增和删除接口建议不要采用时间模式来压测,直接使用线程数和循环;案例:
模拟300秒内开启100个虚拟用户(线程组设置线程数为100),每个用户循环访问服务器资源10次(设置循环次数为10),要求平均响应时间在 30 ms内,且错误率为0
模拟 100 个用户同时访问服务器资源(集合点用定时器,设置group by为100),要求平均响应时间在30ms内,且错误率为0
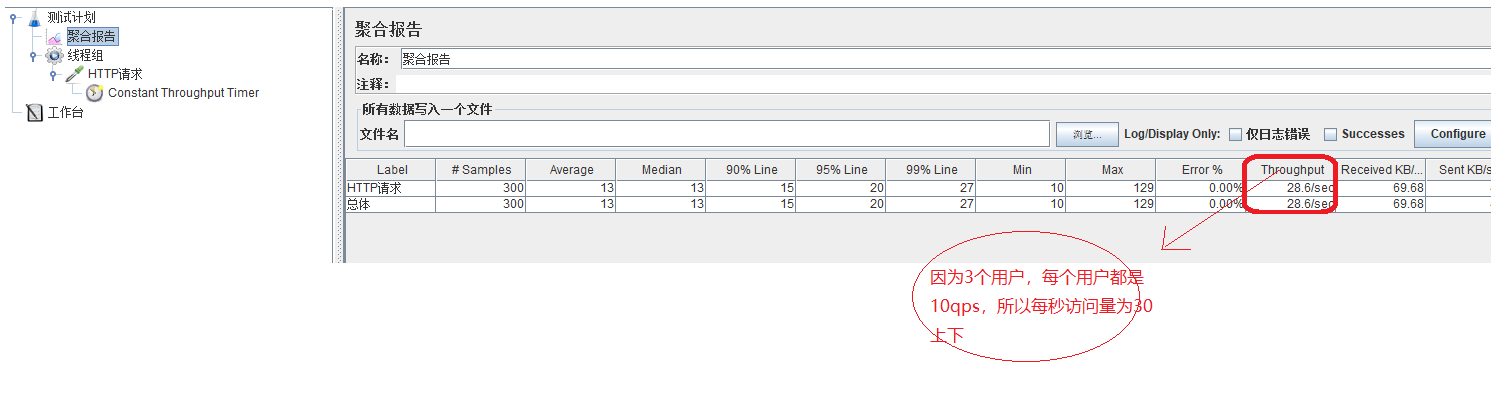
模拟3个用户都以10QPS的评率访问服务器资源(线程数设为3),持续10秒(循环次数为100:频率*持续时间),要求平均响应时间在30ms内,
且错误率为0,constant Throughput Timer组件的:Target throughput(in samplers minute):10*60=600

项目:生成 html 格式测试报告
提示:
JMeter 3.0以上开始支持自动生成动态报告
操作步骤:
两种模式:
无jtl日志或csv日志文件生成报告有jtl日志或csv日志文件生成报告
1. 无日志文件生成:
基本命令格式:
jmeter -n -t <test JMX file> -l <test log file> -e -o <Path to output folder>样例:
jmeter -n -t E:课件JmeterScript自动化脚本Stu_AutoScript.jmx -l testLog -e -o ./output/report参数详解:
-n :以非GUI形式运行Jmeter
-t :source.jmx 脚本路径
-l :运行结果保存路径(.jtl),此文件必须不存在
1) .jtl
2) .txt
3) 无后缀-e :在脚本运行结束后生成html报告
-o :保存html报告的地址, 此文件必须不存在
2. 使用已有的jtl日志文件或csv日志文件生成
基本命令格式:
jmeter -g <log file> -o <Path to output folder>样例:
jmeter -g E:课件JmeterScript自动化脚本
esultt.jtl -o ./outputreport提示:
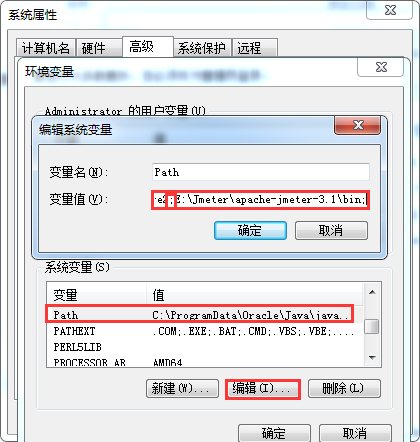
执行命令时,出现Jmeter不是内部或外部命令

解决:
将Jmeter目录下bin文件目录添加到环境变量Path中,注意追加路径是,前面分号;