一:Softmax、Hierarchical Softmax、Negative Sampling结构
(一)Softmax
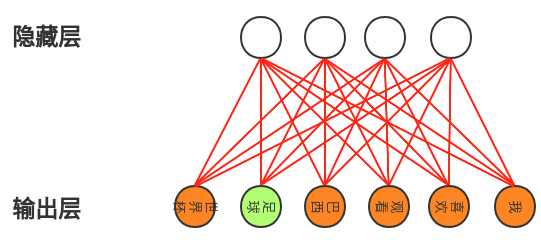
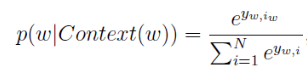
由softmax可以知道,每次求得一个词向量的概率,需要所有的参数(红色连线)参与(分母求和)。如何隐藏层大小为N:300,输出层为词向量维度V:1000,则每次更新的参数量为N*V=300000个。
(二)Hierarchical Softmax
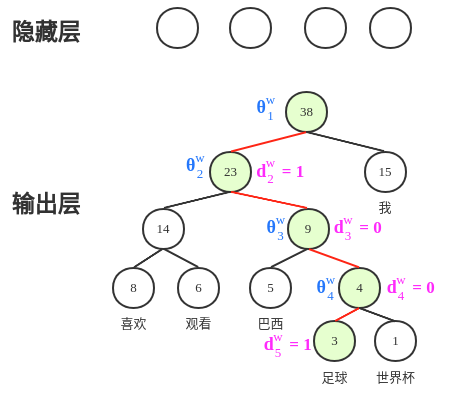
可以看出,隐藏层和输出层的参数在结构上,无直接联系。隐藏层可以直接作为输入X处理,所有的参数都都是在霍夫曼树上面(霍夫曼树只需要在开始建立一次,后面结构不变,反复使用),我们每次更新的参数量大概就是log2V个(红线),其中V为词向量个数。
实现了将Softmax计算转为sigmoid计算,将softmax:V次 exp指数计算转为sigmoid:1次exp指数操作,实现加速!!
将Softmax的N分类变为了log(N)次二分类,更新的参数更少!!!
(三)Negative Sampling

增大正样本的概率同时降低负样本的概率,在效果、效率上比层次softmax好!!!
每次更新的参数量是(正样本+负样本)×N,(其中负样本一般在3-10个,词向量越大,负样本越少),远小于softmax参数更新量,虽然参数量多于层次softmax,但是负采样的计算量并不大,并且最终效果好于层次softmax。
二:word2vec 中的数学原理详解(值得反复读)
我们不生产水,我们只是大自然的搬运工!!!