消息队列(MQ)简介
Kafka是一个消息队列
消息队列的作用:
异步 解耦 削峰
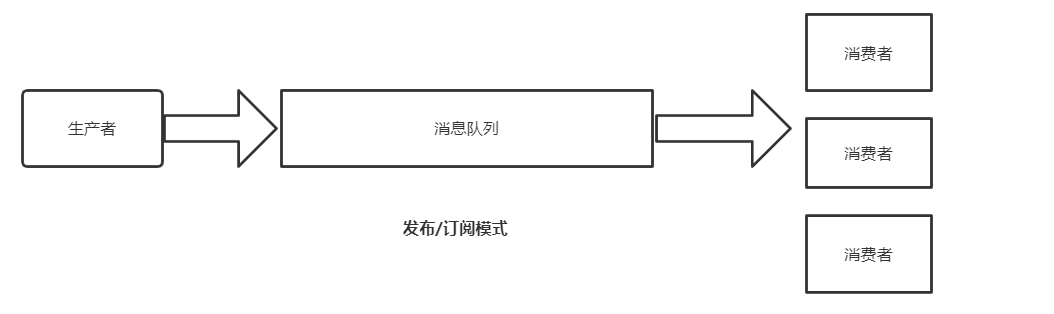
消息队列的两种模式:
1.点对点(消费者主动拉取数据,拉取完成消息清除)
2.发布订阅模式(一对多,消费者接收数据之后 不会清除消息)由队列主动给消费者推消息,速度由消息队列决定,消费者的处理能力不确定。
Kafka采用的是 发布订阅模式中的消费者主动拉取模式(需要维护一个消费者和队列之间的长轮询)
Kafka架构模型
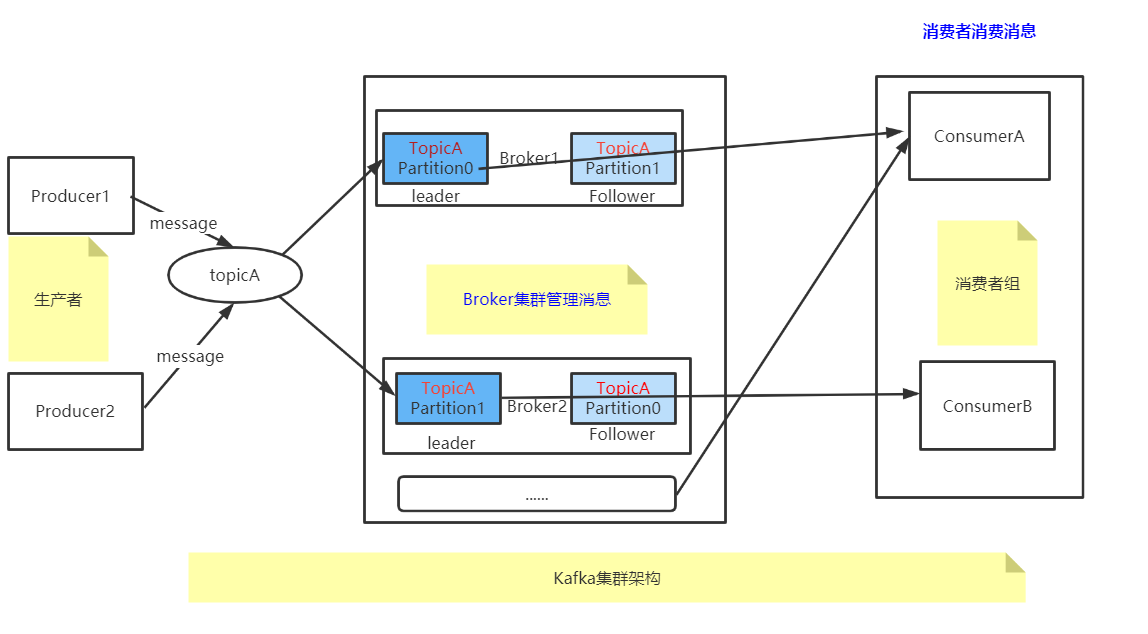
架构概念解释
1、Topic:
不同的TopicA TopicB 给数据分类,一个Topic可以理解为一个队列
2、Partition:
topic是逻辑的概念,partition是物理的概念,对用户来说是透明的。
producer只需要关心消息发往哪个topic,而consumer只关心自己订阅哪个topic,并不关心每条消息存于整个集群的哪个broker。
为了性能考虑,
TopicA一个主题多个分区,提高kafka负载能力。kafka消息队列不能保证全局有序性,只能保证区内有序。
3、Leader Follower:
一个分区Leader Follower 是主备高可用
4、Group:
kafka消费topic是以group为单位来的,一个group消费一个topic。
一个consumer可以消费一个或多个partition,一个partition只能被一个consumer消费。
如果一个消费者宕机后,之前分配给他的分区会重新分配给其他的消费者,实现消费者的故障容错。
topic到group之间是发布订阅的通信方式,即一条topic会被所有的group消费,属于一对多模式;
group到consumer是点对点通信方式,属于一对一模式。
分组的意义
假设一个topic有10个分区,如果没有消费者组,只有一个消费者对这10个分区消费,他的压力肯定大。
如果有了消费者组,组内的成员就可以分担这10个分区的压力,提高消费性能。
mq一共有两种基本消费模式:
1、load balancing(负载均衡):共享订阅、提高性能
2、fan-out(扇出):各自订阅、互不影响
那么有趣的地方来了,group内是load balancing,group间是fan-out
Kafka数据可靠性保证
kafka如何保证消息的顺序性
Kafka 中发送1条消息的时候,可以指定(topic, partition, key) 3个参数。partiton 和 key 是可选的。
如果你指定了 partition,那就是所有消息发往同1个 partition,就是有序的。
并且在消费端,Kafka 保证,1个 partition 只能被1个 consumer 消费。
或者你指定 key(比如 order id),具有同1个 key 的所有消息,会发往同1个 partition。也是有序的。
在或者 你的topic只设置一个分区,这样topic下的所有消息都会发送到一个partion里面,从而有序
kafka分区策略
如果在发消息的时候指定了分区,则消息投递到指定的分区
如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区
如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区
kafka零拷贝 消费者 offset维护
zookeeper在kafka中的作用
1.Broker注册
Broker是分布式部署,并且相互之间相互独立,但是需要一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了zookeeper。
在Zookeeper上有一个专门用来进行Broker服务器列表记录的节点 /broker/ids,每个Broker在启动时,都会到Zookeeper上注册。
即到/broker/ids下创建属于自己的节点,如 /broker/ids/[0...
kafka使用了全局唯一的数字来指代每个Broker服务器,不同的Broker必须使用不同的Broker ID进行注册。
创建完节点后,每个Broker就会将自己的IP地址和端口信息记录到该节点中去。
其中Broker创建的节点是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除
2. Topic注册
在Kafka中,同一个Topic消息会被分成多个分区,并将其分布在多个Broker上。
这些分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点记录 如 /Broker/topics
Kafka中每个Topic都会以/brokers/topics[topic]的形式被记录,如/brokers/topics/login和/brokers/topics/search等
Logstash消费Kafka性能调优
现象:增加多台Logstash,消费kafka的性能并没有提升 不同topic消费速度不均匀,同一个topic下,不同partition消费速度不均匀。
产生原因:
topic的partition的数量少
所有logstash的配置文件都相同,使用同一个group消费所有的topic
解决办法:
提高topic分区数量
对logstash进行分组,数据量较大的topic设置单独的一组logstash和消费组
每组logstash中总的消费线程数量和总的partition数量保持一致