一、State 状态 (状态数据)
Flink 实时计算程序为了保证计算过程中,出现异常可以容错,就要将中间的计算结果数据存储起来,这些中间结果数据就叫做 State。
State 可以是多种类型的,默认是保存到 JobManager 的内存中,也可以保存到TaskManager 本地文件系统或HDFS这样的分布式文件系统。
二、StateBackEnd(靠谱的存储系统中)
用来保存State 的存储后端就叫做StateBackEnd,默认是保存在JobManager 的内存中,也可以保存到本地文件系统或HDFS这样的分布式文件系统中。
三、CheckPointing(周期性的操作)
Flink 实时计算为了容错,可以将中间数据定期保存起来,这种定期触发保存中间结果的机制叫CheckPoint,CheckPoint 是周期执行的,具体的过程是 JobManager定期的
向TaskManager中的SubTask 发送RPC消息,SubTask将其计算的State保存到 StateBackEnd中,并且向JobManager响应CheckPoint是否成功,如果程序出现异常或重启,
TaskManager 中的SubTask可以从上一次成功的CheckPointing 的 State 恢复。
总结:JobManager 需要周期性的让TaskManager中的 SubTask中的State 保存到StateBackEnd 中。
四、重启策略
Flink 实时计算程序,为了容错,需要开启CheckPointing ,一旦开启CheckPoint,如果没有重启策略,默认的重启策略是无限重启,也可以设置其他重启策略,
如:重启固定次数且可以延迟执行的策略。
五、state存储方式,这几种方式有什么异同?
5.1.MemoryStateBackend
MemoryStateBackend将工作状态数据保存在taskManager的java内存中。key/value状态和window算子使用哈希表存储数值和触发器。进行快照时(checkpointing),
生成得快照数据将和checkpoint ACK消息一起发送给 jobmanager,jobmanager将收到的所有快照保存在java内存中。
MemoryStateBackend现在被默认配置成异步的,这样避免阻塞主线程的pipline处理。
MemoryStateBackend的状态存取的速度都非常快,但是又不适合在生产环境中使用。这是因为MemoryStateBackend有以下限制:
1、每个state的默认大小被限制为5MB(这个值可以通过MemoryStateBackend构造函数设置)
2、每个task的所有state数据(一个task可能包含一个pipline中的多个Operator)大小不能超过RPC系统的帧大小(akka.framesize,默认10MB)
3、jobmanager收到的state数据总和不能超过jobmananger内存。
MemoryStateBackend适合的场景:
本地开发和调试
状态很小的作业
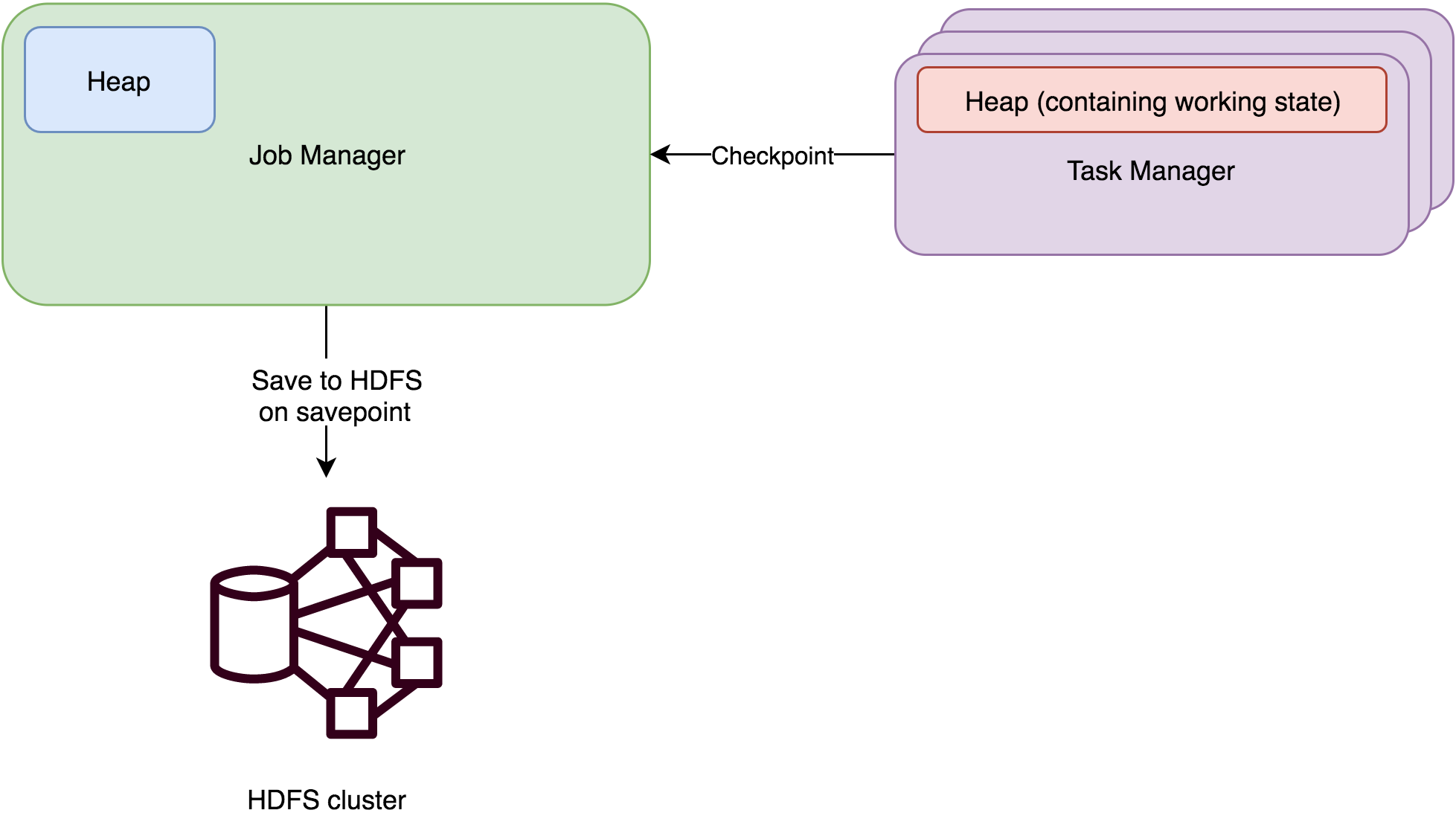
值得说明的是,当触发savepoint时,jobmanager会把快照数据持久化的外部存储。
5.2、FsStateBackend
FsStateBackend需要配置一个 checkpoint路径,例如: "hdfs://namenode:40010/fink/checkpoints"或者"file:///data/flink/checkpoint"
我们一般配置为hdfs目录
FsStateBackend将工作状态数据保存在taskmanager的java内存中。进行快照时,再将快照数据写入上面的路径,然后将写入的文件路径告知jobmanager。
jobmanager中保存所有状态的元数据信息(在HA模式下,元数据会写入checkpoint目录)
FsStateBackend默认使用异步方式进行快照,防止阻塞主线程的pipline处理。可以通过FsStateBackend构造函数取消该模式
new FsStateBackEnd(path,false)
FsStateBackend适合的场景:
大状态,长窗口,大键值(键或者值很大)状态的作业
适合高可用方案
5.3、RocksDBStateBackend
需要配置一个 checkpoint路径,例如: "hdfs://namenode:40010/fink/checkpoints"或者"file:///data/flink/checkpoint"
RocksDB是一种嵌入的持久性的key-value存储引擎,提供ACID支持。由Facebook基于levelDB开发,使用LSM存储引擎,是内存和磁盘混合存储。
RocksDBStateBackend 将工作状态保存在 taskmanager的RocksDB数据库中,checkpoint时,RocksDB中的所有数据会被传输到配置的文件目录,
少量元数据信息保存在jobmanager内存中(HA模式下,会保存在checkpoint目录)
RocksDBStateBackend使用异步方式进行快照
RocksDBStateBackend的限制:
RocksDBStateBackend 适用于以下场景:
- 超大状态、超长窗口(天)、大键值状态的作业
- 适合高可用模式
使用 RocksDBStateBackend 时,能够限制状态大小的是 taskmanager 磁盘空间(相对于 FsStateBackend 状态大小限制于 taskmanager 内存 )。
这也导致 RocksDBStateBackend 的吞吐比其他两个要低一些。因为 RocksDB 的状态数据的读写都要经过反序列化/序列化。
RocksDBStateBackend 是目前三者中唯一支持增量 checkpoint 的。