Hive理论
1、Hive是什么?一个sql解析引擎,将SQL解析成MR,Hive本质就是MR
2、Hive不存数据的,数据实际存在HDFS上,元数据基本上都存在mysql上
3、Hive内容是读多写少,不支持数据的改写和删除
4、Hive的SQL和传统SQL区别:
可扩展性:用户自定义函数
1)UDF:用户自定义普通函数,例:map,一对一
2)UDAF:用户自定义聚合函数,例:groupByKey,多对一
3)UDTF:用户自定义表生成函数,例:flatMap,一对多
数据检查:
HQL(hive):读时模式
加载load数据的速度非常快,加载过程中不需要对数据解析,仅仅涉及到文件的复制和移动
但读的时候慢
SQL(传统):写时模式
加载数据的时候速度非常慢,但是读的时候快
5、Hive体系架构
1)用户接口Cli
2)语句转化Driver:将SQl转换成MR
3)数据存储:元数据(mysql)+实际数据(HDFS)
默认derby:本地,单用户模式
建mysql:多用户模式(本地+远程)
6、Hive数据管理:
1)Table:内部表
2)External Table:外部表
3)Partition:辅助查询,缩小查询范围,加快数据检索速度
4)Bucket:桶,reduce,采样,控制reduce的数量
7、Hive数据类型
1)原生类型int string bool double
2)复合类型
8、hive优化(mapreduce优化)
1)map优化
优化并发个数
block大小会影响并发度
hive.map.aggr=true ,相当于开启Combiner功能
2)reduce优化
优化并发个数
set mapred.reduce.tasks=10
3)mapreduce出现痛点:只有一个reduce的情况
1、没有group by
2、order by,建议用distribute by和sort by来替代
order by:全局排序,因此只有一个reduce,当输入数据规模较大时,计算时间消耗严重
sort by:不是全局排序,如果用sort by排序,并且设置多个reduce,
每个reduce输出是有序的,但是不保证全局排序
distribute by:控制map端的数据如果拆分给redcuce,可控制分区文件的个数
cluster by:相当于distribute by和sort by的结合,但是只默认升序排序
先在map阶段进行排序,再根据不同的key进行分发
例子1:select * from TableA distribute by userid sort by itemid;
例子2:
select * from TableA distribute by itemid sort by itemid asc;
select * from TableA cluster by itemid;
3、笛卡尔积
使用join的时候,尽量有效的使用on条件
4)mapreduce出现痛点:如何加快查询速度(横向尽可能多并发,纵向尽可能少依赖)
1、分区Partition
2、Map Join:指定表是小表,内存处理,通常不超过1个G或者50w记录
3、union all:先把两张表union all,然后再做join或者group by,可以减少mr的数量
union 和 union all区别:union相当记录合并,union all不合并,性能后者更优
4、multi-insert & multi group by
5、Automatic merge:为了多个小文件合并
6、Multi-Count Distinct
一个MR,拆成多个的目的是为了降低数据倾斜的压力
7、并行执行:set hive.exec.parallel=true
5)mapreduce出现痛点:如何加快join操作
1、语句优化:
多表连接:如果join中多个表的join key是同一个,则join会转化为单个mr任务
表的连接顺序:指定大、小表
Hive默认把左表数据放到缓存中,右边的表的数据做流数据
2、如果避免join过程中出现大量结果,尽可能在on中完成所有条件判断
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key) WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
ASELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07')
执行顺序是,首先完成2表JOIN,然后再通过WHERE条件进行过滤,这样在JOIN过程中可能会 输出大量结果,再对这些结果进行过滤,比较耗时。可以进行优化,将WHERE条件放在ON后 ,在JOIN的过程中,就对不满足条件的记录进行了预先过滤。
6)并行实行:
– 同步执行hive的多个阶段,hive在执行过程,将一个查询转化成一个或者多个阶段。
某个特 定的job可能包含众多的阶段,而这些阶段可能并非完全相互依赖的,也就是说可以并行执行 的,这样可能使得整个job的执行时间缩短。
hive执行开启:set hive.exec.parallel=true
7)数据倾斜
mapreduce解决数据倾斜问题
1、大小表关联
2、大大表关联
操作
• Join
• Group by
• Count Distinct
• 原因
• key分布不均导致的
• 人为的建表疏忽
• 业务数据特点
• 症状
• 任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。 • 查看未完成的子任务,可以看到本地读写数据量积累非常大,通常超过10GB可以认定为发生数据倾斜。
• 倾斜度
• 平均记录数超过50w且最大记录数是超过平均记录数的4倍。
• 最长时长比平均时长超过4分钟,且最大时长超过平均时长的2倍。
• 万能方法 • hive.groupby.skewindata=true
H i v e 的优化——数据倾斜——大小表关联
• 原因
• Hive在进行join时,按照join的key进行分发,而在join左边的表的数据会首先读入内存,如果左边表的key相对 分散,读入内存的数据会比较小,join任务执行会比较快;而如果左边的表key比较集中,而这张表的数据量很大, 那么数据倾斜就会比较严重,而如果这张表是小表,则还是应该把这张表放在join左边。
• 思路
• 将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率 • 使用map join让小的维度表先进内存。
• 方法
• Small_table join big_table
8)设置 hive的执行引擎
set hive.execution.engine=spark;
set spark.executor.memory=8g;
set spark.executor.cores=4;
9)优化 in/exists 语句
虽然经过测试,hive1.2.1 也支持 in/exists 操作,但还是推荐使用 hive的一个高效替代方案:left semi join
比如说:
select a.id,a.name from a where a.id in (select b.id from b)
select a.id,a.name from a where exists (select id from b where a.id = b.id )
应该转换成:
select a.id ,a.name from a left semi join b on a.id = b.id
10) map join 能解释一下 map join 的原理吗
理论分析:
如果不指定MapJoin 或者不符合 MapJoin的条件,那么HIve 解析器会将Join操作转换成Common Join,即:在 Reduce阶段完成 Join。容易发生数据倾斜。
可以用MapJoin 把小表全部加载到内存,在map端进行 join,避免 reducer处理。
1)开启 MapJoin 参数设置:
(1)设置自动选择MapJoin
set hive.auto.convert.join = true ;默认为 true
(2)大表小表的阀值设置(默认25M以下认为是小表)
set hive.mapjoin.smalltable.filesize=25000000;
2)MapJoin 工作机制
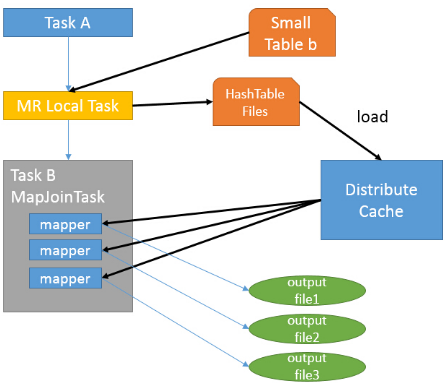
首先是Task A,它是一个 Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地文件中,之后将该文件加载到
DistributeCache中。
接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据 a的每一条记录去和DistributeCache中 b表对应的HashTable关联,并直接输出
结果。
由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件。