1、导入模块
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入。导入模块有一下几种方法:
1. import module
2. from moudule.xxx.xxx import xx
3. from module.xxx.xxx import xx as xxx
4. from module.xxx.xxx import *
导入模块其实就是告诉Python解释器去解释那个py文件
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件
2、时间模块time/datetime
>>> time.altzone #当前时间转为夏令时区差值
-32400
>>> 32400/3600
9.0
>>> time.asctime() / time.ctime()
'Wed Dec 13 15:07:24 2017'
>>> time.localtime()
time.struct_time(tm_year=2017, tm_mon=12, tm_mday=13, tm_hour=15, tm_min=7, tm_sec=54, tm_wday=2, tm_yday=347, tm_isdst=0)
tm_wday:一个星期的第几天 (从星期一开始为0)
tm_isdst: 是否使用夏令时区, 0表示没有
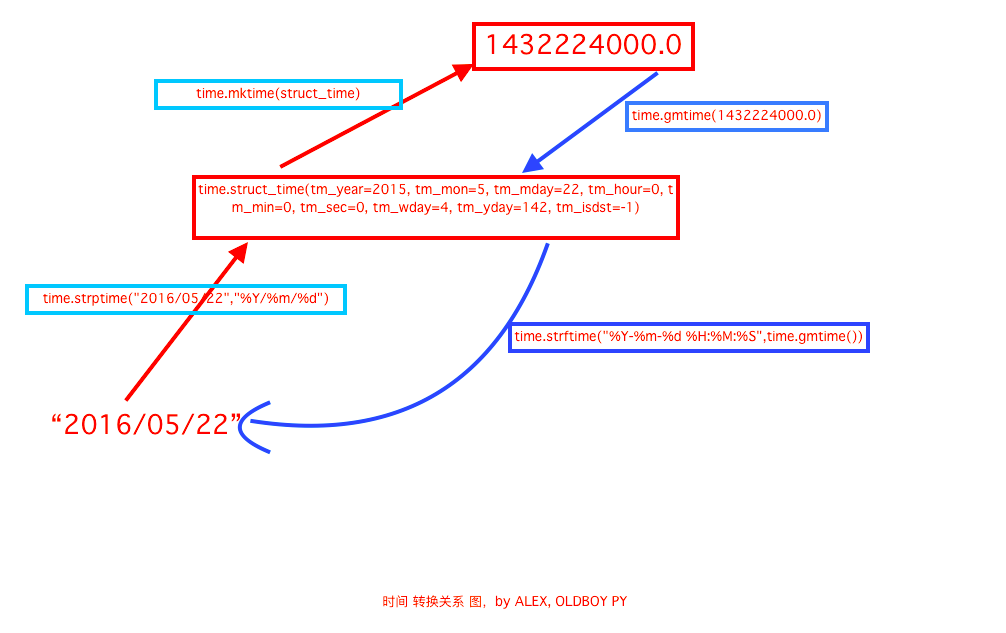
时间字符串 =====> 时间戳
>>> import time
>>> str = "2016/05/22"
>>> string_2_struct = time.strptime(str,"%Y/%m/%d") # 日期字符串 ====> struct时间对象格式
>>> string_2_struct
time.struct_time(tm_year=2016, tm_mon=5, tm_mday=22, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=143, tm_isdst=-1)
>>> struct_2_stamp = time.mktime(string_2_struct) # struct时间对象格式 ====> 时间戳
>>> struct_2_stamp
1463846400.0
时间戳 =====> 时间字符串
>>> stamp_2_struct = time.gmtime(struct_2_stamp) # 时间戳 ====> struct_time格式
>>> stamp_2_struct
time.struct_time(tm_year=2016, tm_mon=5, tm_mday=21, tm_hour=16, tm_min=0, tm_sec=0, tm_wday=5, tm_yday=142, tm_isdst=0)
>>> time.strftime("%Y-%m-%d %H:%M:%S",stamp_2_struct) # struct_time格式 ====> 字符串格式
'2016-05-21 16:00:00'
import datetime
>>> str_time = datetime.datetime.now() # 获取当前时间
>>> str_time
datetime.datetime(2017, 12, 13, 14, 50, 27, 265392)
>>> datetime.date.fromtimestamp(time.time()) # 时间戳 转 日期格式
datetime.date(2017, 12, 13)
更改时间操作:datetime.timedelta(x) # x 默认是天/ hours=3 / minutes=30 当前时间基础上加、减
>>> str_time + datetime.timedelta(3)
datetime.datetime(2017, 12, 16, 14, 50, 27, 265392)
# 时间替换replace
str_time.replace(minute=3,hour=2)
datetime.datetime(2017, 12, 13, 2, 3, 27, 265392)
datetime与time补充:
nowtime = time.time() # uct时间戳 1519980490.124744
datetime.datetime.now() # 北京时间 datetime.datetime(2018, 3, 2, 16, 47, 58, 347367)
随机数
>>> import random
>>> random.random() # 生成随机数
0.34855893809643523
>>> random.randrange(1,10) # range(1,10)之间生成随机数
4
>>> random.randint(1,2) # 从1,2之间生成整数(包括2)
1
###########################
实例:随机码
import random
checkcode = ""
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode)
############################
ord()函数主要用来返回对应字符的ascii码
chr()主要用来表示ascii码对应的字符他的输入时数字,可以用十进制,也可以用十六进制。
>>> chr(80)
'P'
>>> ord('P')
80
3、OS模块
提供对操作系统进行调用的接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cdos.curdir 返回当前目录: ('.')os.pardir 获取当前目录的父目录字符串名:('..')os.makedirs('dirname1/dirname2') 可生成多层递归目录os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirnameos.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirnameos.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印os.remove() 删除一个文件os.rename("oldname","newname") 重命名文件/目录os.stat('path/filename') 获取文件/目录信息os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"os.linesep 输出当前平台使用的行终止符,win下为"
",Linux下为"
"os.pathsep 输出用于分割文件路径的字符串os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'x = os.system("bash command") 运行shell命令,直接显示, x返回的是执行后的状态码
os.environ 获取系统环境变量os.path.abspath(path) 返回path规范化的绝对路径os.path.split(path) 将path分割成目录和文件名二元组返回os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素os.path.exists(path) 如果path存在,返回True;如果path不存在,返回Falseos.path.isabs(path) 如果path是绝对路径,返回Trueos.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回Falseos.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回Falseos.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间os模块官网地址:https://docs.python.org/2/library/os.html?highlight=os#module-os
os补充:
>>> os.listdir()
['.idea', 'day07', 'FTP', 'oldboy', '练习']
>>> os.makedirs("dirname1/dirname2")
>>> os.listdir()
['.idea', 'day07', 'dirname1', 'FTP', 'oldboy', '练习']
>>> os.removedirs("dirname1/dirname2")
>>> os.listdir()
['.idea', 'day07', 'FTP', 'oldboy', '练习']
>>> os.stat('D:\python\untitled')
os.stat_result(st_mode=16895, st_ino=844424930136207, st_dev=369559483, st_nlink=1, st_uid=0, st_gid=0, st_size=4096, st_atime=1513151026, st_mtime=1513151026, st_ctime=1500456486)
>>> os.sep #获取路径分隔符
'\'
>>> os.path.split('D:\python\untitled\__file__')
('D:\python\untitled', '__file__')
#######################################
os.path.join:
- import os
- help(os.path.join)

函数功能:连接两个或更多的路径名组件
如果各组件名首字母不包含'/',则函数会自动加上
如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃
如果最后一个组件为空,则生成的路径以一个'/'分隔符结尾
- path=os.getcwd() #获得当前路径
- path_a=path+"/hello"
- path_b=path+"/wo"
- path_c="hehe"
- path_d=""
- os.path.join(path,path_a,path_b,path_c,path_d)
最后路径取了path_b的绝对路径

4、sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径sys.exit(n) 退出程序,正常退出时exit(0)sys.version 获取Python解释程序的版本信息sys.maxsize 最大值2147483647
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值sys.platform 返回操作系统平台名称>>> sys.stdout.write("please:")
>>> >? hehe
'hehe'
>>> sys.stdin.readline()
>? heh
'heh '
5、hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlibm = hashlib.md5()m.update(b"Hello")m.update(b"It's me")print(m.digest())m.update(b"It's been a long time since last time we ...")print(m.digest()) #2进制格式hashprint(len(m.hexdigest())) #16进制格式hash'''def digest(self, *args, **kwargs): # real signature unknown """ Return the digest value as a string of binary data. """ passdef hexdigest(self, *args, **kwargs): # real signature unknown """ Return the digest value as a string of hexadecimal digits. """ pass'''import hashlibhash = hashlib.md5() ---》 sha1 / sha256 / sha384 / sha512 用法都是一样
hash.update('admin')print(hash.hexdigest())还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
>>> h = hmac.new('天王盖地虎'.encode('utf-8'), '宝塔镇河妖'.encode('utf-8')) # 可以一个也可以多个
>>> h.hexdigest()
'5f90dcd2211cd11601ce05195e3c5232'
6、shutil
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length]) # 只拷贝文件内容,传入的参数是文件对象

shutil.copyfile(src, dst) # 拷贝文件内容,传输的参数是文件名
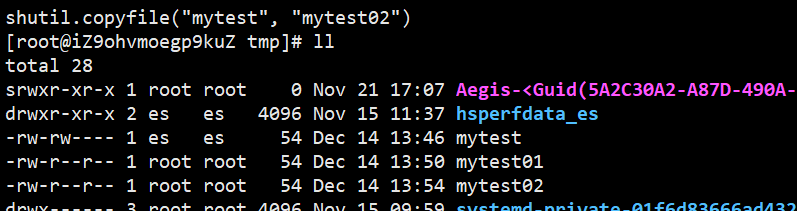
shutil.copymode(src, dst) # 只改变文件权限
-rw-rw---- 1 es es 54 Dec 14 13:46 mytest
-rw-rw---- 1 root root 0 Dec 14 19:28 mytest01
shutil.copystat(src, dst) # 拷贝文件状态 (权限mode bits, atime, mtime, flags),不包括用户与属组
[root@iZ9ohvmoegp9kuZ tmp]# stat mytest
File: ‘mytest’
Size: 54 Blocks: 8 IO Block: 4096 regular file
Device: ca01h/51713d Inode: 393228 Links: 1
Access: (0660/-rw-rw----) Uid: ( 1001/ es) Gid: ( 1001/ es)
Access: 2017-12-14 13:50:31.048796289 +0800
Modify: 2017-12-14 13:46:28.300799584 +0800
Change: 2017-12-14 13:50:25.382679700 +0800
[root@iZ9ohvmoegp9kuZ tmp]# stat mytest01
File: ‘mytest01’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: ca01h/51713d Inode: 393227 Links: 1
Access: (0660/-rw-rw----) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-12-14 13:50:31.048796289 +0800
Modify: 2017-12-14 13:46:28.300799584 +0800
Change: 2017-12-14 19:34:30.919403706 +0800
shutil.copy(src, dst) # 拷贝文件内容与权限
shutil.copy2(src, dst) # 拷贝文件内容、权限、状态
shutil.copytree(src, dst, symlinks=False, ignore=None) # 递归拷贝
shutil.rmtree(path[, ignore_errors[, onerror]]) # 递归的去删除文件
shutil.move(src, dst) # 递归的移动文件或目录
shutil.make_archive(base_name, format,...) # 压缩文件
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile 压缩解压
import zipfile
# 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall()
z.close()
tarfile 压缩解压
import tarfile
# 压缩
tar = tarfile.open('your.tar','w')
tar.add('/Users/wupeiqi/PycharmProjects/bbs2.zip', arcname='bbs2.zip')
tar.add('/Users/wupeiqi/PycharmProjects/cmdb.zip', arcname='cmdb.zip')
tar.close()
# 解压
tar = tarfile.open('your.tar','r')
tar.extractall() # 可设置解压地址
tar.close()
7、shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve
d = shelve.open("shelve_test") 打开一个文件
############# 写入文件内容 ###########
info = {"age": 22, "job": "it"}
name = ["ale", "rain", "test"]
d["name"] = name
d["info"] = info
d.close()
############# 读取文件内容 ##########
print(d.get("info"))
print(d.get('name'))
8、xml模块
import xml.etree. ElementTree as ET
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
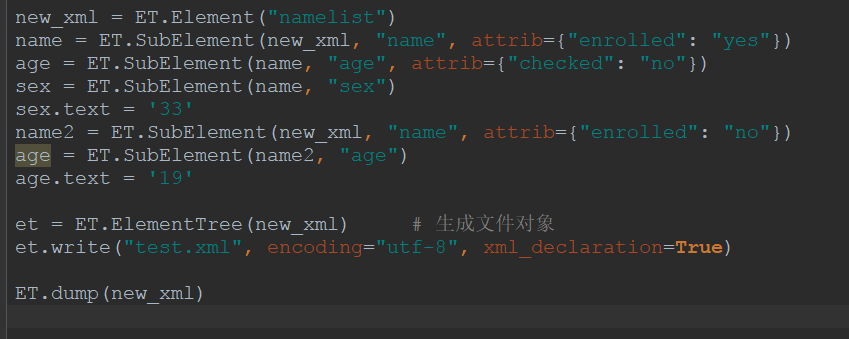
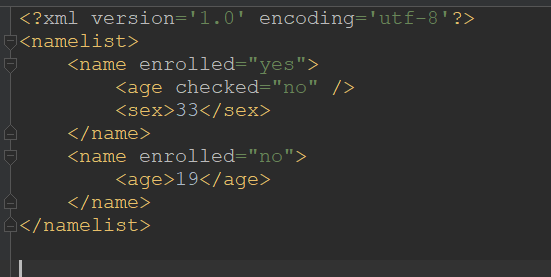
出来如下:
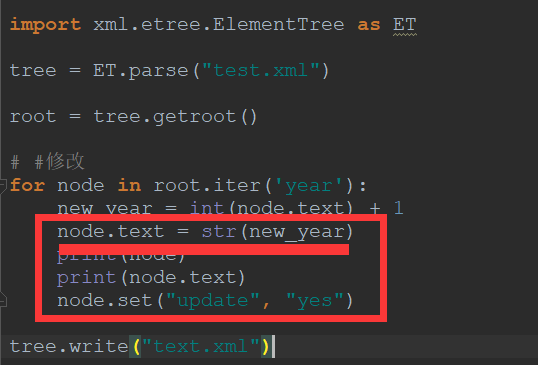
修改xml文件( 每个year中添加 update = yes,修改 node.text 值 )
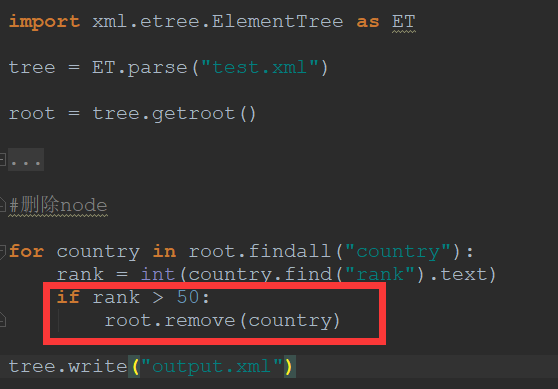
删除xml文件(country 整个node删除)
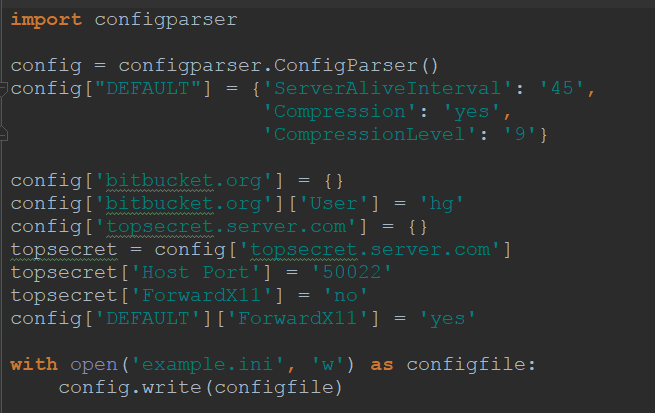
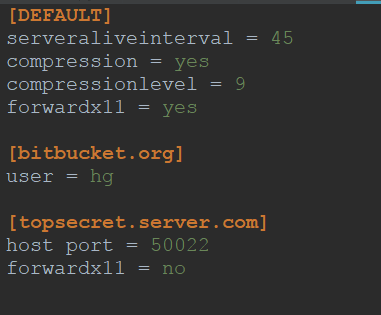
9、configparser模块
例如:my.ini配置文件
10、re模块
'.' 默认匹配除
之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","
abc
eee",flags=re.MULTILINE)'$' 匹配字符结尾,或e.search("foo$","bfoo
sdfsf",flags=re.MULTILINE).group()也可以'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']'?' 匹配前一个字符1次或0次'{m}' 匹配前一个字符m次'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC''(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c'A' 只从字符开头匹配,re.search("Aabc","alexabc") 是匹配不到的'' 匹配字符结尾,同$'d' 匹配数字0-9'D' 匹配非数字'w' 匹配[A-Za-z0-9]'W' 匹配非[A-Za-z0-9]'s' 匹配空白字符、 、
、
, re.search("s+","ab c1
3").group() 结果 ' ''(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'} 最常用的匹配语法
re.match 从头开始匹配re.search 匹配包含re.findall 把所有匹配到的字符放到以列表中的元素返回re.splitall 以匹配到的字符当做列表分隔符re.sub 匹配字符并替换反斜杠的困扰
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。同样,匹配一个数字的"\d"可以写成r"d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
仅需轻轻知道的几个匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)S(DOTALL): 点任意匹配模式,改变'.'的行为
11、 logging日志模块
logging.basicConfig(filename='example.log',level=logging.INFO) # 改日志级别、写入文件
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p') # 日志格式、时间格式
日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
formatter决定日志记录的最终输出格式。
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
logger=logging.getLogger(”chat.gui”) ---> 获取一个 logger
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”) ---> logger
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')# add formatter to ch and fhch.setFormatter(formatter)fh.setFormatter(formatter)